db per tenant
1.0.0
Dieses Repo enthält ein Beispiel für eine skalierbare Architektur für AI-betriebene Anwendungen. An der Oberfläche handelt es sich um eine KI -App, in der Benutzer PDFs hochladen und mit ihnen chatten können. Unter der Motorhaube erhält jeder Benutzer jedoch eine dedizierte Vektor -Datenbankinstanz (Postgres auf Neon mit PGVector).
Sie können sich die Live-Version unter https://db-per-tenant.up.railway.app/ ansehen
Die App wird mit den folgenden Technologien erstellt:
Anstatt alle Vektor -Einbettungen in einer einzigen Postgres -Datenbank gespeichert zu haben, stellen Sie jedem Mieter (einem Benutzer, einer Organisation, einem Arbeitsbereich oder einer anderen Entität an, die Isolation benötigt) eine eigene Postgres -Datenbankinstanz, in der Sie seine Einbettungen speichern und abfragen können.
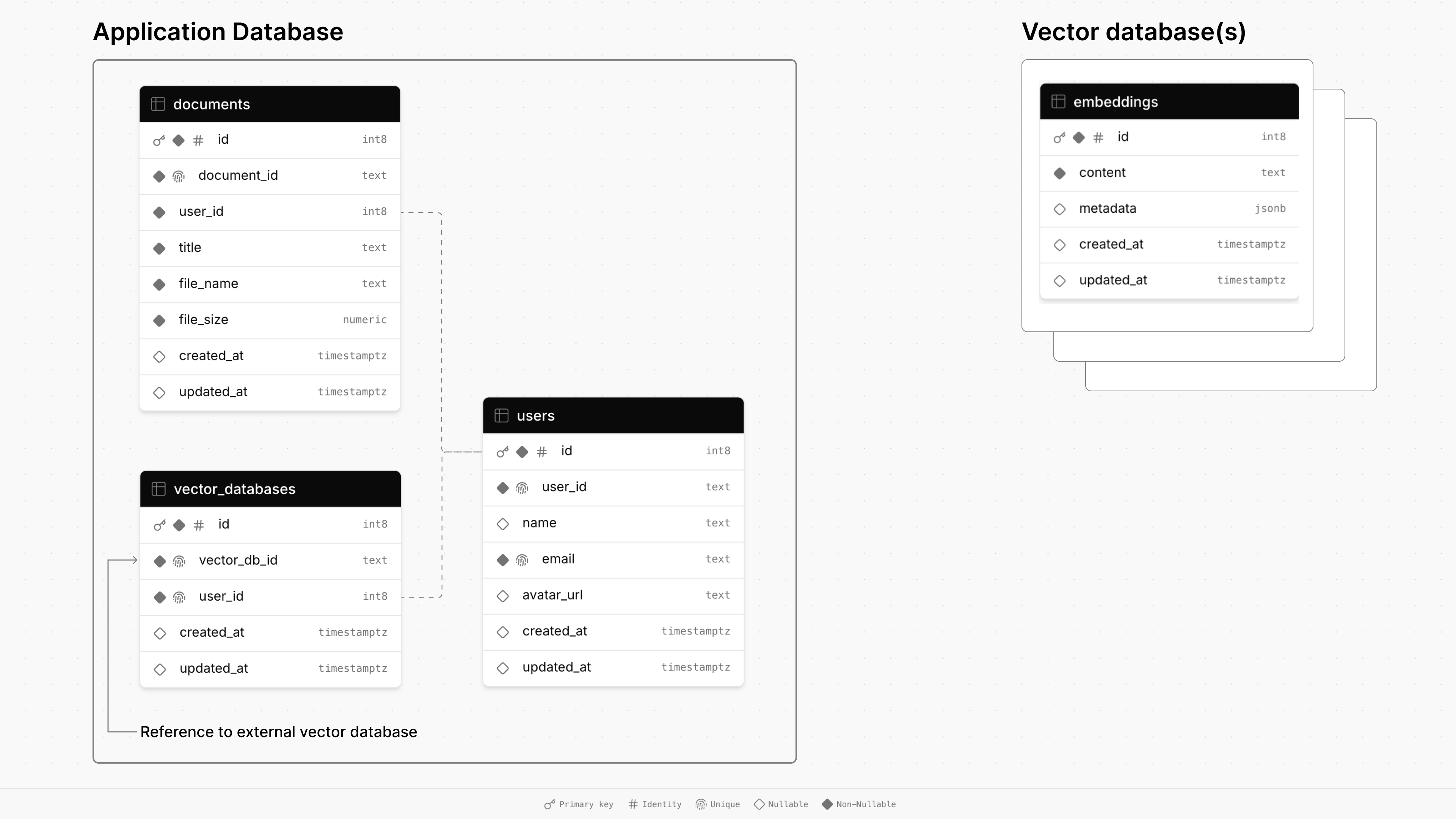
Abhängig von Ihrer Anwendung stellen Sie nach einem bestimmten Ereignis eine Vektor -Datenbank vor (z. B. eine Anmeldung, Organisationserstellung oder ein Upgrade auf kostenpflichtige Stufe). Sie verfolgen dann Mieter und die zugehörigen Vektor -Datenbanken in der Hauptdatenbank Ihrer Anwendung.
Dieser Ansatz bietet mehrere Vorteile:
Hier ist das Datenbankarchitekturdiagramm der Demo -App, das in diesem Repo ist:
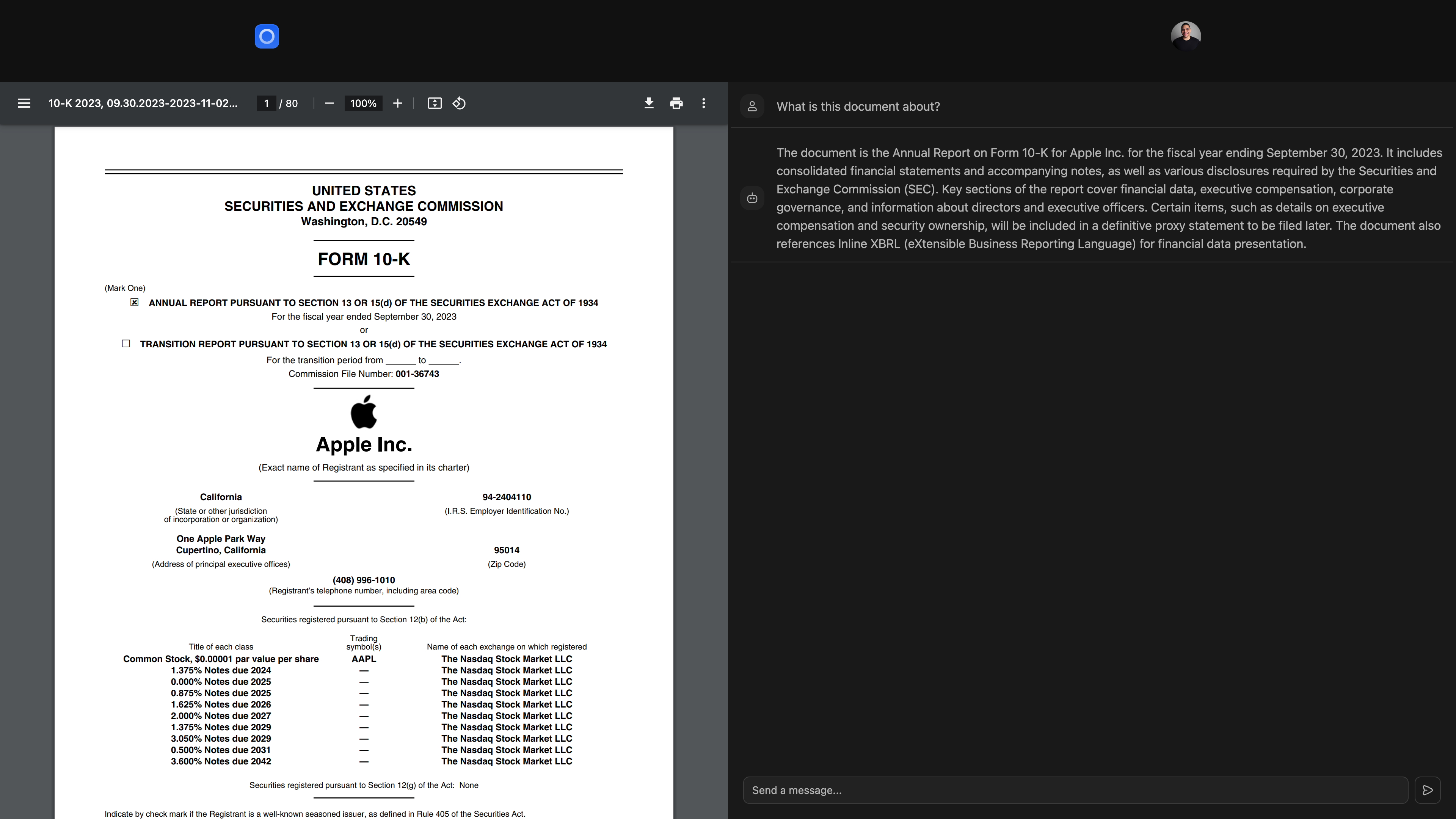
Die Datenbank der Hauptanwendung besteht aus drei Tabellen: documents , users und vector_databases .
documents werden Informationen zu Dateien enthalten, einschließlich ihrer Titel, Größen und Zeitstempel, und über einen Fremdschlüssel mit Benutzern verknüpft.users verwaltet Benutzerprofile, einschließlich Namen, E -Mails und Avatar -URLs.vector_databases verfolgt, welche Vektordatenbank zu welchem Benutzer gehört. Anschließend verfügt jede Vektor-Datenbank, die vorgelegt wird, über eine embeddings Tabelle zum Speichern von Dokumentenbrocken für die Abrufen-Generation (RAG).
Für diese App werden Vektordatenbanken vorgelegt, wenn sich ein Benutzer anmeldet. Sobald sie ein Dokument hochgeladen haben, wird es in ihrer dedizierten Vektor -Datenbank unterteilt und gespeichert. Sobald der Benutzer mit ihrem Dokument chatten, wird die Vektor -Ähnlichkeitssuche gegen ihre Datenbank ausgeführt, um die relevanten Informationen abzurufen, um ihre Eingabeaufforderung zu beantworten.
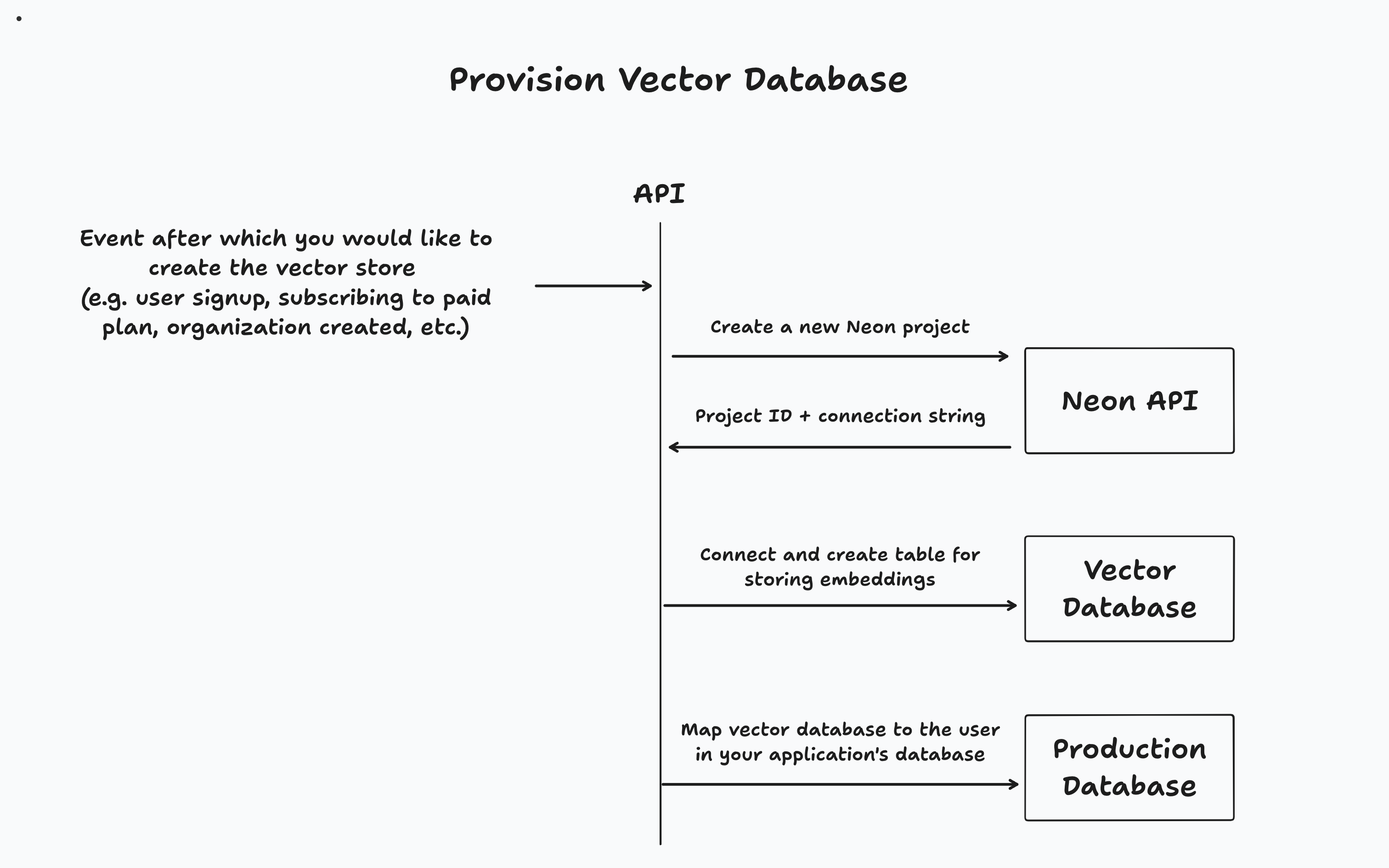
// Code from app/lib/auth.ts
authenticator . use (
new GoogleStrategy (
{
clientID : process . env . GOOGLE_CLIENT_ID ,
clientSecret : process . env . GOOGLE_CLIENT_SECRET ,
callbackURL : process . env . GOOGLE_CALLBACK_URL ,
} ,
async ( { profile } ) => {
const email = profile . emails [ 0 ] . value ;
try {
const userData = await db
. select ( {
user : users ,
vectorDatabase : vectorDatabases ,
} )
. from ( users )
. leftJoin ( vectorDatabases , eq ( users . id , vectorDatabases . userId ) )
. where ( eq ( users . email , email ) ) ;
if (
userData . length === 0 ||
! userData [ 0 ] . vectorDatabase ||
! userData [ 0 ] . user
) {
const { data , error } = await neonApiClient . POST ( "/projects" , {
body : {
project : { } ,
} ,
} ) ;
if ( error ) {
throw new Error ( `Failed to create Neon project, ${ error } ` ) ;
}
const vectorDbId = data ?. project . id ;
const vectorDbConnectionUri = data . connection_uris [ 0 ] ?. connection_uri ;
const sql = postgres ( vectorDbConnectionUri ) ;
await sql `CREATE EXTENSION IF NOT EXISTS vector;` ;
await migrate ( drizzle ( sql ) , { migrationsFolder : "./drizzle" } ) ;
const newUser = await db
. insert ( users )
. values ( {
email ,
name : profile . displayName ,
avatarUrl : profile . photos [ 0 ] . value ,
userId : generateId ( { object : "user" } ) ,
} )
. onConflictDoNothing ( )
. returning ( ) ;
await db
. insert ( vectorDatabases )
. values ( {
vectorDbId ,
userId : newUser [ 0 ] . id ,
} )
. returning ( ) ;
const result = {
... newUser [ 0 ] ,
vectorDbId ,
} ;
return result ;
}
return {
... userData [ 0 ] . user ,
vectorDbId : userData [ 0 ] . vectorDatabase . vectorDbId ,
} ;
} catch ( error ) {
console . error ( "User creation error:" , error ) ;
throw new Error ( getErrorMessage ( error ) ) ;
}
} ,
) ,
) ;
// Code from app/routes/api/document/chat
// Get the user's messages and the document ID from the request body.
const {
messages ,
documentId ,
} : {
messages : Message [ ] ;
documentId : string ;
} = await request . json ( ) ;
const { content : prompt } = messages [ messages . length - 1 ] ;
const { data , error } = await neonApiClient . GET (
"/projects/{project_id}/connection_uri" ,
{
params : {
path : {
project_id : user . vectorDbId ,
} ,
query : {
role_name : "neondb_owner" ,
database_name : "neondb" ,
} ,
} ,
} ,
) ;
if ( error ) {
return json ( {
error : error ,
} ) ;
}
const embeddings = new OpenAIEmbeddings ( {
apiKey : process . env . OPENAI_API_KEY ,
dimensions : 1536 ,
model : "text-embedding-3-small" ,
} ) ;
const vectorStore = await NeonPostgres . initialize ( embeddings , {
connectionString : data . uri ,
tableName : "embeddings" ,
columns : {
contentColumnName : "content" ,
metadataColumnName : "metadata" ,
vectorColumnName : "embedding" ,
} ,
} ) ;
const result = await vectorStore . similaritySearch ( prompt , 2 , {
documentId ,
} ) ;
const model = new ChatOpenAI ( {
apiKey : process . env . OPENAI_API_KEY ,
model : "gpt-4o-mini" ,
temperature : 0 ,
} ) ;
const allMessages = messages . map ( ( message ) =>
message . role === "user"
? new HumanMessage ( message . content )
: new AIMessage ( message . content ) ,
) ;
const systemMessage = new SystemMessage (
`You are a helpful assistant, here's some extra additional context that you can use to answer questions. Only use this information if it's relevant:
${ result . map ( ( r ) => r . pageContent ) . join ( " " ) } ` ,
) ;
allMessages . push ( systemMessage ) ;
const stream = await model . stream ( allMessages ) ;
return LangChainAdapter . toDataStreamResponse ( stream ) ;Dieser Ansatz ist zwar von Vorteil, kann er auch eine Herausforderung sein, um die Implementierung zu implementieren. Sie müssen den Lebenszyklus jeder Datenbank, einschließlich Bereitstellung, Skalierung und Deprovisionierung, verwalten. Glücklicherweise ist Postgres on Neon anders eingerichtet:
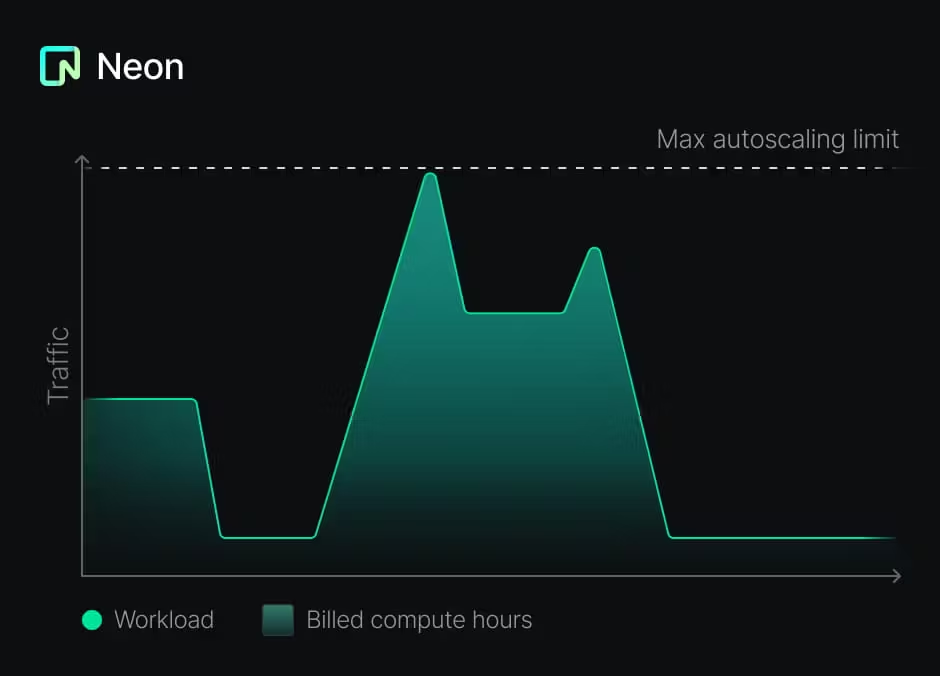
Dies ermöglicht das vorgeschlagene Muster, eine Datenbank pro Mieter zu erstellen, nicht nur möglich, sondern auch kostengünstig.
Wenn Sie eine Datenbank pro Mieter haben, müssen Sie Migrationen für jede Datenbank verwalten. Dieses Projekt verwendet Nieselregen:
/app/lib/vector-db/schema.ts mithilfe von TypeScript definiert.bun run vector-db:generate und in /app/lib/vector-db/migrations gespeichert.bun run vector-db:migrate ausführen. In diesem Befehl wird ein Skript ausgeführt, das eine Verbindung zur Datenbank jedes Mieters herstellt und die Migrationen anwendet.Es ist wichtig zu beachten, dass alle, die Sie einführen möchten, rückwärtskompatibel sein sollten. Andernfalls müssten Sie mit Schema -Migrationen unterschiedlich umgehen.
Während dieses Muster bei der Erstellung von AI -Anwendungen nützlich ist, können Sie es einfach verwenden, um jedem Mieter eine eigene Datenbank zu bieten. Sie können auch eine andere Datenbank als Postgres für die Datenbank Ihrer Hauptanwendung verwenden (z. B. MySQL, MongoDB, MSSQL Server usw.).
Wenn Sie Fragen haben, wenden Sie sich bitte an die Neon -Zwietracht oder wenden Sie sich an das Neon -Verkaufsteam. Wir würden gerne von Ihnen hören.


