OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
歡迎來到Reddit Post Summarizer聊天界面。此簡化的應用程序允許用戶無縫地從Reddit URL中提取和匯總內容,並舉辦QA會話。這是我第一次嘗試將LLM與Vector DB一起用於QA,摘要,微調目的。
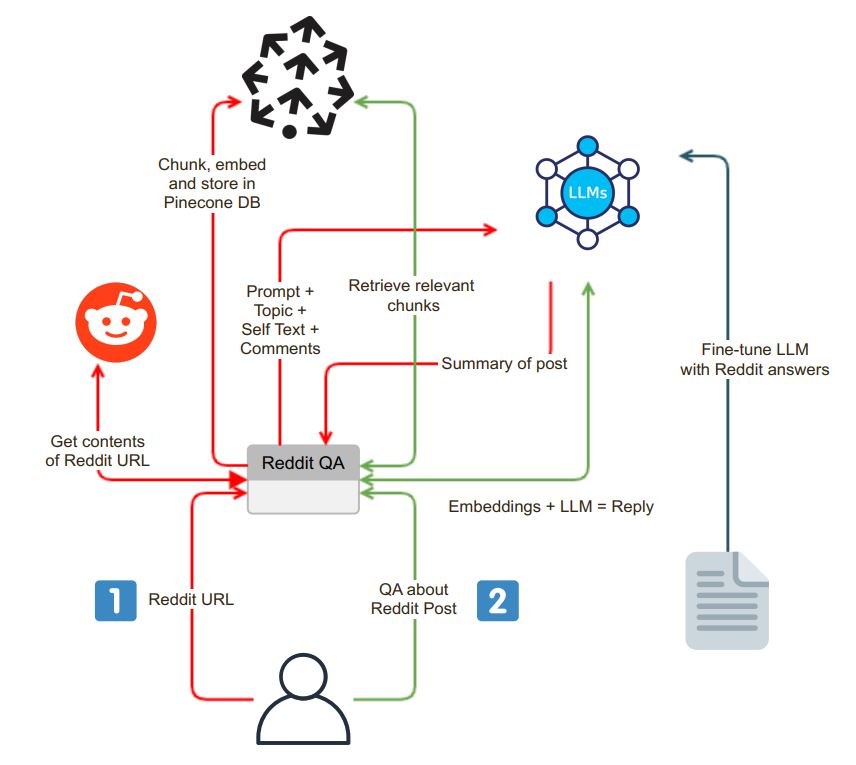
該應用程序使用用戶友好的聊天接口啟動。用戶可以在搜索框中輸入Reddit URL,並且系統執行以下步驟:
URL驗證:應用程序驗證輸入的URL是否屬於Reddit。
PRAW集成:成功的URL驗證後,使用Python Reddit API包裝器(Praw)來提取Reddit Post的內容。這包括與帖子相關的自我文字和評論。
數據塊和嵌入:檢索到的自文本和註釋分為較小的,易消化的片段(塊)。然後將每個塊嵌入,並將嵌入在矢量數據庫Pinecone中存儲。此步驟對於高效,快速數據檢索至關重要。
在提取和嵌入過程之後,該應用程序使用語言模型(LLM)(例如OpenAI GPT-3.5)生成了Reddit帖子的摘要。匯總過程可以分解為以下步驟:
塊的生成:通過遞歸總結塊,直到適合LLM的令牌限制來生成合適尺寸的文本塊。
LLM模型交互:將提示發送到LLM模型,後來返回了該帖子的簡明摘要。該摘要捕獲了Reddit內容的本質。
該應用程序提供了一個聊天接口,用戶可以在其中與系統進行交互並詢問有關Reddit帖子的問題。聊天界面具有一些不同的功能:
上下文問題處理:當用戶提出問題時,系統會嵌入問題並蒐索矢量數據庫以找到上下文相似性。它獲取相關上下文,並將其作為提示的一部分附加到用戶的問題上。
答案生成:然後將此擴展提示發送到LLM模型,該模型產生了詳細且感知的答案。
模型微調:為了確保答案是reddit式的,可以通過Reddit Question-Asswer對進行微調LLM模型,從而提供與Reddit的社區語言相符的答案。
應用程序的獨特功能之一是用戶可以選擇他們想要使用的語言模型。 Langchain促進了這種靈活性,該工具允許該應用程序根據用戶的喜好在不同的LLM模型之間無縫切換。
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

