OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
欢迎来到Reddit Post Summarizer聊天界面。此简化的应用程序允许用户无缝地从Reddit URL中提取和汇总内容,并举办QA会话。这是我第一次尝试将LLM与Vector DB一起用于QA,摘要,微调目的。
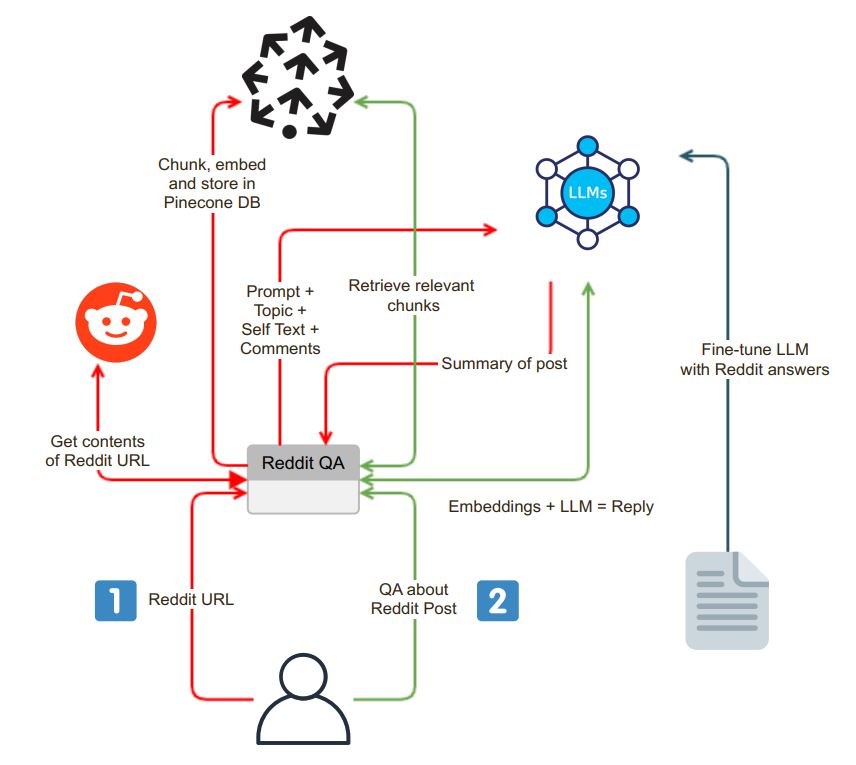
该应用程序使用用户友好的聊天接口启动。用户可以在搜索框中输入Reddit URL,并且系统执行以下步骤:
URL验证:应用程序验证输入的URL是否属于Reddit。
PRAW集成:成功的URL验证后,使用Python Reddit API包装器(Praw)来提取Reddit Post的内容。这包括与帖子相关的自我文字和评论。
数据块和嵌入:检索到的自文本和注释分为较小的,易消化的片段(块)。然后将每个块嵌入,并将嵌入在矢量数据库Pinecone中存储。此步骤对于高效,快速数据检索至关重要。
在提取和嵌入过程之后,该应用程序使用语言模型(LLM)(例如OpenAI GPT-3.5)生成了Reddit帖子的摘要。汇总过程可以分解为以下步骤:
块的生成:通过递归总结块,直到适合LLM的令牌限制来生成合适尺寸的文本块。
LLM模型交互:将提示发送到LLM模型,后来返回了该帖子的简明摘要。该摘要捕获了Reddit内容的本质。
该应用程序提供了一个聊天接口,用户可以在其中与系统进行交互并询问有关Reddit帖子的问题。聊天界面具有一些不同的功能:
上下文问题处理:当用户提出问题时,系统会嵌入问题并搜索矢量数据库以找到上下文相似性。它获取相关上下文,并将其作为提示的一部分附加到用户的问题上。
答案生成:然后将此扩展提示发送到LLM模型,该模型产生了详细且感知的答案。
模型微调:为了确保答案是reddit式的,可以通过Reddit Question-Asswer对进行微调LLM模型,从而提供与Reddit的社区语言相符的答案。
应用程序的独特功能之一是用户可以选择他们想要使用的语言模型。 Langchain促进了这种灵活性,该工具允许该应用程序根据用户的喜好在不同的LLM模型之间无缝切换。
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

