OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
Bienvenue à l'interface de chat Summarizer Reddit Post. Cette application basée sur le rationalisation permet aux utilisateurs d'extraire et de résumer le contenu à partir des URL Reddit de manière transparente et de maintenir des sessions QA. Ceci est ma première tentative d'utilisation de LLMS avec des DB vectoriels pour QA, résumé, fin de réglage fin.
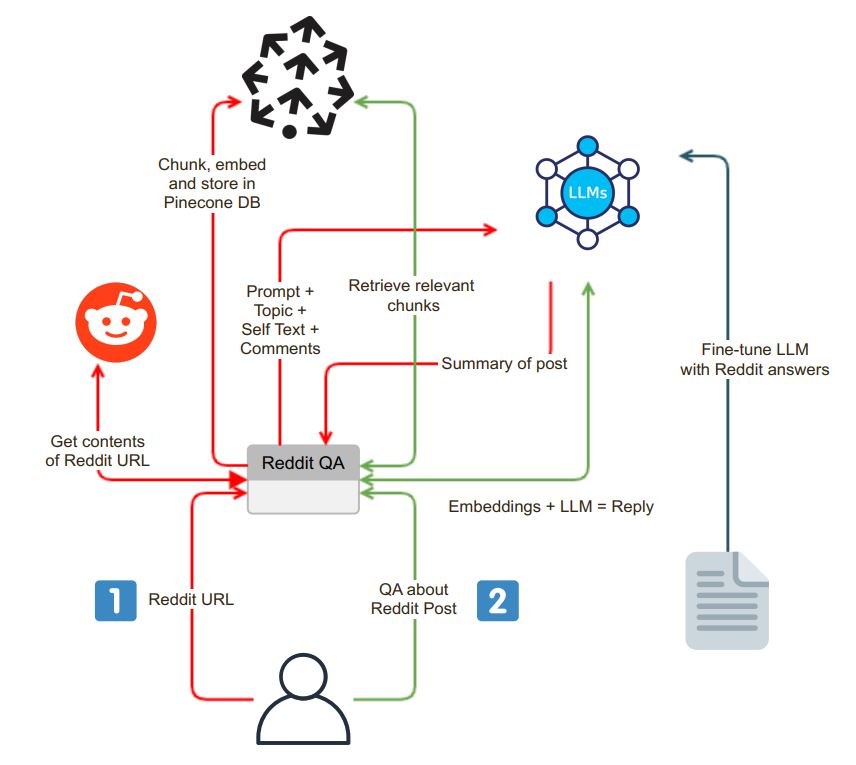
L'application initie avec une interface de chat conviviale. Les utilisateurs peuvent saisir une URL Reddit dans la zone de recherche, et le système entreprend les étapes suivantes:
Validation de l'URL : l'application vérifie si l'URL entrée appartient à Reddit.
Intégration de Praw : lors de la validation réussie de l'URL, l'emballage API Python Reddit (PRAW) est utilisé pour extraire le contenu du poteau Reddit. Cela inclut l'auto-texte et les commentaires associés au message.
Données Chunking et intégration : l'auto-texte et les commentaires récupérés sont divisés en segments plus petits et digestibles (morceaux). Chaque morceau est ensuite intégré et les intégres sont stockés dans une base de données vectorielle, Pinecone. Cette étape est essentielle pour une récupération efficace des données.
Après le processus d'extraction et d'incorporation, l'application génère un résumé du post Reddit à l'aide d'un modèle de langue (LLM) tel que OpenAI GPT-3.5. Le processus de résumé peut être décomposé dans les étapes suivantes:
Génération de morceaux : un morceau de texte de taille appropriée est généré en résumant récursivement des morceaux jusqu'à ce qu'il corresponde à la limite de jeton du LLM.
Interaction du modèle LLM : une invite de résumé est envoyée au modèle LLM, qui renvoie par la suite un résumé concis de la publication. Ce résumé capture l'essence du contenu Reddit.
L'application fournit une interface de chat où les utilisateurs peuvent interagir avec le système et poser des questions sur la publication Reddit. L'interface de chat a des fonctionnalités distinctes:
Traitement de la question contextuelle : Lorsqu'un utilisateur pose une question, le système intègre la question et recherche la base de données vectorielle pour la similitude du contexte. Il récupère le contexte pertinent et l'ajoute à la question de l'utilisateur dans le cadre de l'invite.
Génération de réponses : Cette invite étendue est ensuite envoyée au modèle LLM, qui produit une réponse détaillée et consciente du contexte.
Modèle de réglage fin : Pour s'assurer que les réponses sont de style Reddit, le modèle LLM peut être affiné avec les paires de questions de questions Reddit, offrant des réponses qui s'alignent avec la langue communautaire de Reddit.
L'une des fonctionnalités uniques de l'application est la possibilité pour les utilisateurs de choisir le modèle de langue qu'ils souhaitent utiliser. Cette flexibilité est facilitée par Langchain, un outil qui permet à l'application de basculer de manière transparente entre différents modèles LLM en fonction des préférences de l'utilisateur.
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

