OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
Reddit Post Summarizerチャットインターフェイスへようこそ。この流れベースのアプリケーションを使用すると、ユーザーはReddit URLからコンテンツをシームレスに抽出および要約し、QAセッションを保持できます。これは、QA、要約、微調整目的でベクターDBSを使用してLLMSを使用する私の最初の試みです。
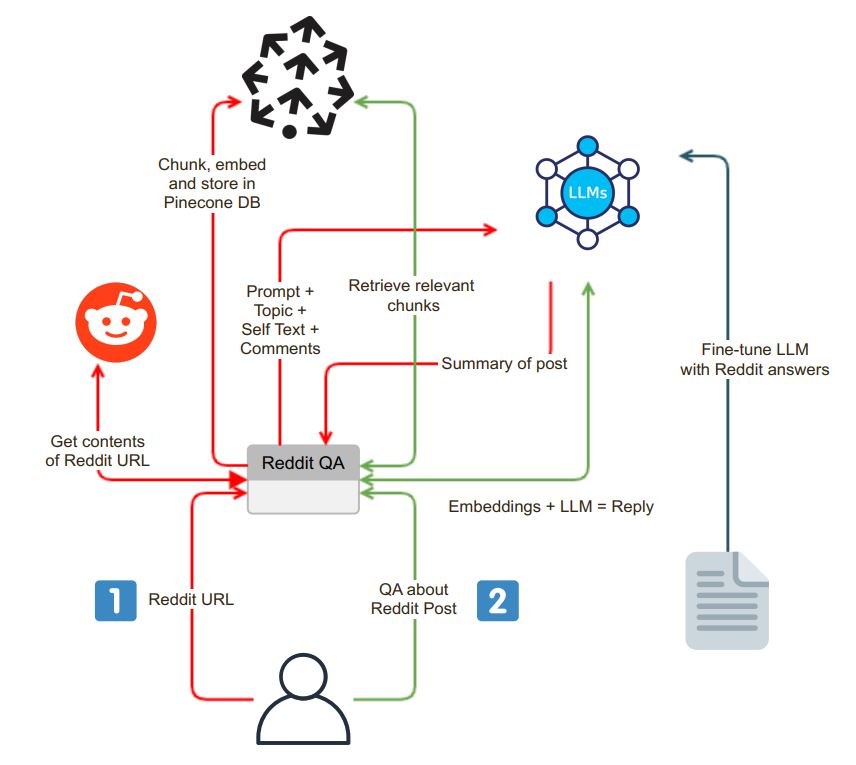
アプリケーションは、ユーザーフレンドリーなチャットインターフェイスで開始されます。ユーザーは検索ボックスにReddit URLを入力でき、システムは次の手順を実行できます。
URL検証:アプリケーションは、入力されたURLがRedditに属しているかどうかを検証します。
PRAWの統合:URL検証が成功すると、Python Reddit APIラッパー(PRAW)が使用され、Reddit Postの内容が抽出されます。これには、投稿に関連するセルフテキストとコメントが含まれます。
データチャンキングと埋め込み:検索されたセルフテキストとコメントは、より小さな消化可能なセグメント(チャンク)に分割されます。次に、各チャンクが埋め込まれ、埋め込みはベクトルデータベースPineconeに保存されます。このステップは、効率的かつ迅速なデータ取得に不可欠です。
抽出および埋め込みプロセスに続いて、アプリケーションは、OpenAI GPT-3.5などの言語モデル(LLM)を使用してReddit Postの概要を生成します。要約プロセスは、次の手順に分類できます。
チャンク生成:適切なサイズのテキストチャンクは、LLMのトークン限界に合うまでチャンクを再帰的に要約することにより生成されます。
LLMモデルの相互作用:要約プロンプトがLLMモデルに送信され、その後、投稿の簡潔な要約が返されます。この要約は、Redditコンテンツの本質をキャプチャします。
アプリケーションは、ユーザーがシステムと対話し、Redditの投稿について質問することができるチャットインターフェイスを提供します。チャットインターフェイスには、いくつかの明確な機能があります。
コンテキストの質問処理:ユーザーが質問をすると、システムは質問を埋め込み、コンテキストの類似性についてベクトルデータベースを検索します。関連するコンテキストを取得し、プロンプトの一部としてユーザーの質問に追加します。
回答生成:次に、この拡張プロンプトがLLMモデルに送信され、詳細かつコンテキスト認識の回答が生成されます。
モデルの微調整:回答がRedditスタイルであることを確認するために、LLMモデルはRedditの質問回答ペアで微調整でき、Redditのコミュニティ言語に合わせた回答を提供します。
アプリケーションのユニークな機能の1つは、ユーザーが使用する言語モデルを選択できることです。この柔軟性は、アプリケーションがユーザーの好みに応じて異なるLLMモデル間をシームレスに切り替えることができるツールであるLangchainによって促進されます。
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

