OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
Bienvenido a la interfaz de chat de resumen de Reddit Post. Esta aplicación basada en optimismo permite a los usuarios extraer y resumir el contenido de las URL de Reddit sin problemas y mantener las sesiones de control de calidad. Este es mi primer intento de usar LLM con DBS vectorial para QA, resumen, fines de ajuste fino.
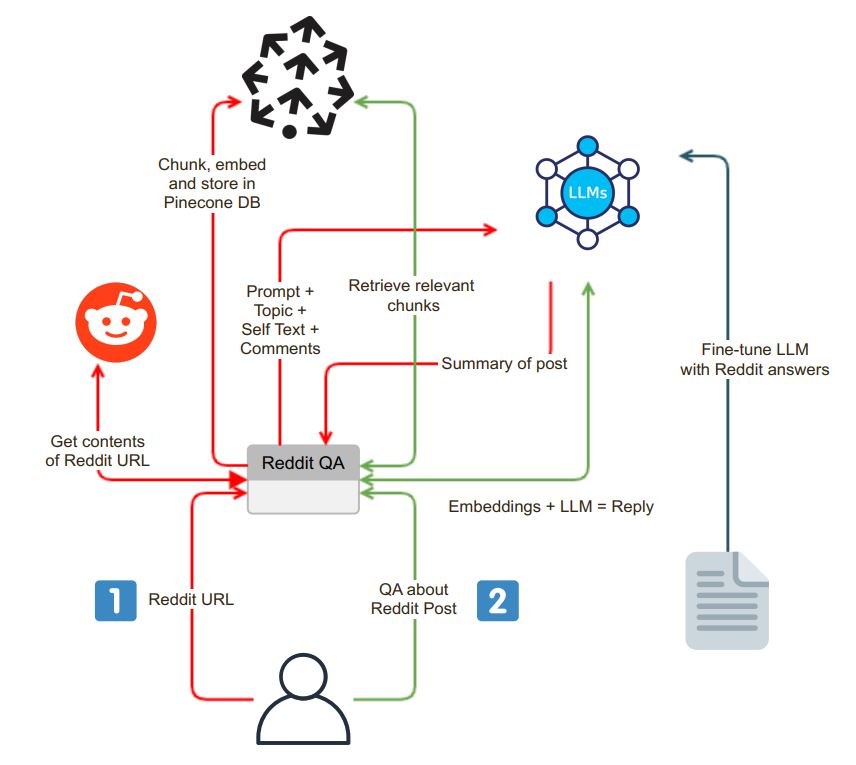
La aplicación se inicia con una interfaz de chat fácil de usar. Los usuarios pueden ingresar una URL Reddit en el cuadro de búsqueda, y el sistema realiza los siguientes pasos:
Validación de URL : la aplicación verifica si la URL ingresada pertenece a Reddit.
Integración de praw : tras la validación de URL exitosa, se emplea el envoltorio de la API de Python Reddit (PRAW) para extraer el contenido de la publicación de Reddit. Esto incluye el auto texto y los comentarios asociados con la publicación.
Data fragmentación e incrustación : el auto texto y los comentarios recuperados se dividen en segmentos más pequeños y digeribles (fragmentos). Cada fragmento se incrusta y los incrustaciones se almacenan en una base de datos vectorial, Pinecone. Este paso es esencial para la recuperación eficiente y rápida de datos.
Después del proceso de extracción e incrustación, la aplicación genera un resumen de la publicación de Reddit utilizando un modelo de idioma (LLM) como OpenAI GPT-3.5. El proceso de resumen se puede dividir en los siguientes pasos:
Generación de fragmentos : se genera un texto de tamaño adecuado resumiendo recursivamente trozos hasta que se ajuste al límite de token de la LLM.
Interacción del modelo LLM : se envía un mensaje de resumen al modelo LLM, que posteriormente devuelve un resumen conciso de la publicación. Este resumen captura la esencia del contenido de Reddit.
La aplicación proporciona una interfaz de chat donde los usuarios pueden interactuar con el sistema y hacer preguntas sobre la publicación de Reddit. La interfaz de chat tiene algunas características distintas:
Procesamiento de preguntas contextuales : cuando un usuario hace una pregunta, el sistema incorpora la pregunta y busca en la base de datos de vectores para la similitud de contexto. Obtiene el contexto relevante y lo agrega a la pregunta del usuario como parte de la solicitud.
Generación de respuestas : este mensaje extendido se envía al modelo LLM, que produce una respuesta detallada y consciente del contexto.
Modelo ajustado : para asegurarse de que las respuestas sean de estilo Reddit, el modelo LLM se puede ajustar con pares de respuesta-respuesta de Reddit, entregando respuestas que se alinean con el lenguaje comunitario de Reddit.
Una de las características únicas de la aplicación es la capacidad de los usuarios de elegir el modelo de idioma que desean usar. Langchain facilita esta flexibilidad, una herramienta que permite que la aplicación cambie perfectamente entre diferentes modelos LLM de acuerdo con las preferencias del usuario.
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

