OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
Willkommen an der Reddit Post Summariizer Chat -Schnittstelle. Mit dieser streamlit-basierten Anwendung können Benutzer Inhalte aus Reddit-URLs nahtlos extrahieren und zusammenfassen und QA-Sitzungen abhalten. Dies ist mein erster Versuch, LLMs mit Vektor-DBS für QA, Zusammenfassung und Feinabstimmungszwecke zu verwenden.
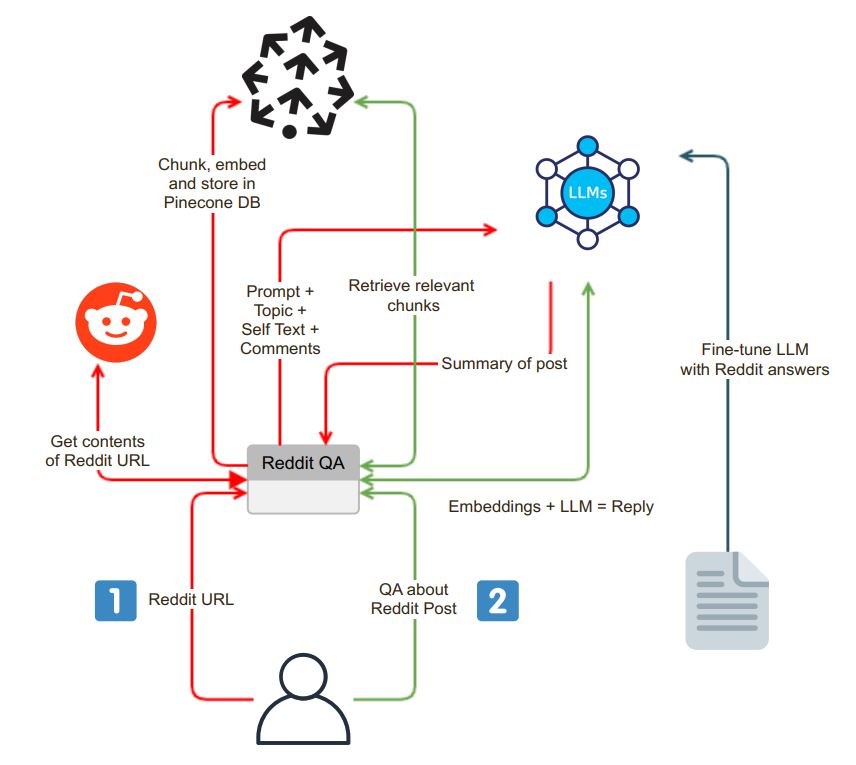
Die Anwendung initiiert mit einer benutzerfreundlichen Chat-Oberfläche. Benutzer können eine Reddit -URL in das Suchfeld eingeben, und das System führt die folgenden Schritte aus:
URL -Validierung : Die Anwendung überprüft, ob die eingegebene URL zu Reddit gehört.
PRAW -Integration : Bei erfolgreicher URL -Validierung wird der Python Reddit API -Wrapper (PRAW) verwendet, um den Inhalt des Reddit -Posts zu extrahieren. Dies schließt den Selbsttext und die mit dem Beitrag verbundenen Kommentare ein.
Datenbummel und Einbettung : Der abgerufene Selbsttext und die Kommentare sind in kleinere, verdauliche Segmente (Stücke) unterteilt. Jeder Chunk wird dann eingebettet und die Einbettungen werden in einer Vektor -Datenbank, Pnecone, gespeichert. Dieser Schritt ist für ein effizientes und schnelles Datenabruf von wesentlicher Bedeutung.
Nach dem Extraktions- und Einbettungsprozess erzeugt die Anwendung eine Zusammenfassung des Reddit-Posts mit einem Sprachmodell (LLM) wie OpenAI GPT-3.5. Der Zusammenfassungsprozess kann in die folgenden Schritte unterteilt werden:
Chunk -Generierung : Ein Textanteil der geeigneten Größe wird erzeugt, indem die Brocken rekursiv zusammengefasst werden, bis sie zur Token -Grenze des LLM passt.
LLM -Modellinteraktion : Eine zusammenfassende Eingabeaufforderung wird an das LLM -Modell gesendet, das anschließend eine kurze Zusammenfassung des Posts zurückgibt. Diese Zusammenfassung erfasst die Essenz des Reddit -Inhalts.
Die Anwendung bietet eine Chat -Oberfläche, in der Benutzer mit dem System interagieren und Fragen zum Reddit -Beitrag stellen können. Die Chat -Oberfläche hat verschiedene Funktionen:
Kontextfragestellung : Wenn ein Benutzer eine Frage stellt, bettet das System die Frage ein und sucht die Vektordatenbank nach Kontextähnlichkeit. Es holt den relevanten Kontext ab und findet ihn als Teil der Eingabeaufforderung an die Frage des Benutzers an.
Antwortgenerierung : Diese erweiterte Eingabeaufforderung wird dann an das LLM-Modell gesendet, das eine detaillierte und kontextbewusste Antwort erzeugt.
Model Feinabstimmung : Um sicherzustellen, dass die Antworten im Reddit-Stil sind, kann das LLM-Modell mit Reddit-Frage-Answer-Paaren fein abgestimmt werden, die Antworten liefern, die mit Reddits Gemeinschaftssprache übereinstimmen.
Eine der einzigartigen Funktionen der Anwendung ist die Fähigkeit der Benutzer, das Sprachmodell auszuwählen, das sie verwenden möchten. Diese Flexibilität wird von Langchain erleichtert, ein Tool, mit dem die Anwendung entsprechend den Benutzerpräferenzen nahtlos zwischen verschiedenen LLM -Modellen wechseln kann.
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

