OpenAI RAG for Reddit Comments QnA using Docker
1.0.0
Reddit Post Summarizer 채팅 인터페이스에 오신 것을 환영합니다. 이 간소화 기반 응용 프로그램을 통해 사용자는 Reddit URL의 컨텐츠를 원활하게 추출하고 요약하고 QA 세션을 보유 할 수 있습니다. 이것은 QA, 요약, 미세 조정 목적으로 벡터 DBS와 함께 LLM을 사용하려는 첫 번째 시도입니다.
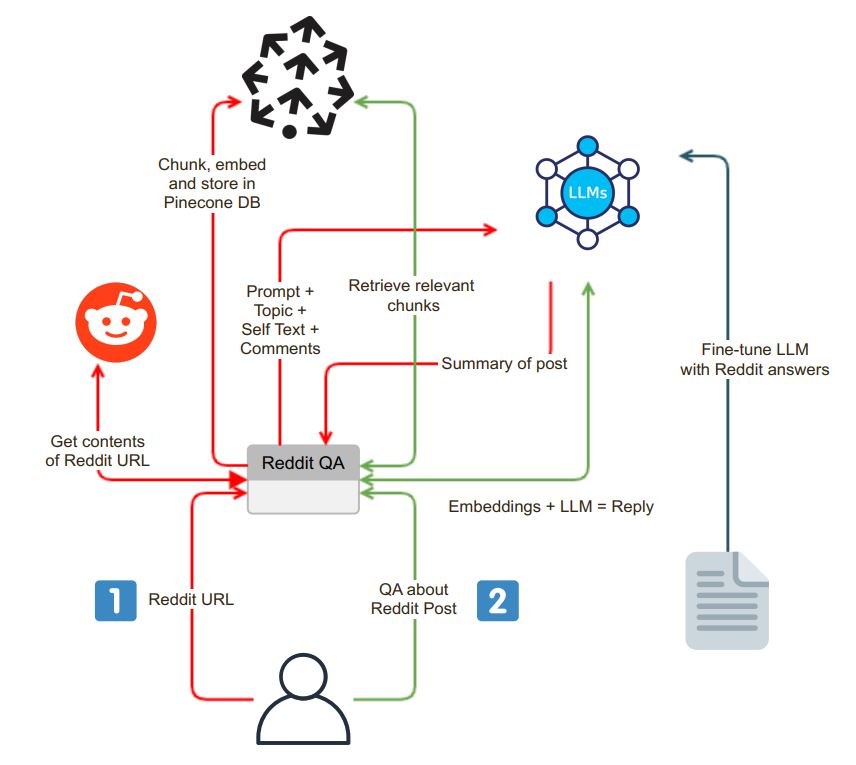
응용 프로그램은 사용자 친화적 인 채팅 인터페이스로 시작합니다. 사용자는 검색 창에 Reddit URL을 입력 할 수 있으며 시스템은 다음 단계를 수행합니다.
URL 유효성 검사 : 응용 프로그램은 입력 된 URL이 Reddit에 속하는지 여부를 확인합니다.
PRAW 통합 : 성공적인 URL 유효성 검증 후 Python Reddit API 래퍼 (PRAW)는 Reddit 게시물의 내용을 추출하기 위해 사용됩니다. 여기에는 셀프 텍스트 및 게시물과 관련된 주석이 포함됩니다.
데이터 청크 및 임베딩 : 검색된 셀프 텍스트 및 주석은 더 작고 소화 가능한 세그먼트 (청크)로 나뉩니다. 그런 다음 각 청크를 내장하고 내장은 벡터 데이터베이스 인 Pinecone에 저장됩니다. 이 단계는 효율적이고 빠른 데이터 검색에 필수적입니다.
추출 및 임베딩 프로세스 후, 응용 프로그램은 OpenAI GPT-3.5와 같은 언어 모델 (LLM)을 사용하여 Reddit 게시물의 요약을 생성합니다. 요약 프로세스는 다음 단계로 나눌 수 있습니다.
청크 생성 : 적합한 크기의 텍스트 청크는 LLM의 토큰 한계에 맞을 때까지 청크를 재귀 적으로 요약하여 생성됩니다.
LLM 모델 상호 작용 : 요약 프롬프트가 LLM 모델로 전송되어 게시물의 간결한 요약을 반환합니다. 이 요약은 Reddit 컨텐츠의 본질을 포착합니다.
응용 프로그램은 사용자가 시스템과 상호 작용하고 Reddit 게시물에 대한 질문을 할 수있는 채팅 인터페이스를 제공합니다. 채팅 인터페이스에는 몇 가지 고유 한 기능이 있습니다.
상황에 맞는 질문 처리 : 사용자가 질문을 할 때 시스템은 질문을 포함하고 컨텍스트 유사성을 위해 벡터 데이터베이스를 검색합니다. 관련 컨텍스트를 가져와 프롬프트의 일부로 사용자의 질문에 추가합니다.
답변 생성 :이 확장 프롬프트는 LLM 모델로 전송되어 상세하고 상황을 인식합니다.
모델 미세 조정 : 답변이 Reddit 스타일인지 확인하기 위해 LLM 모델을 Reddit 질문 응답 쌍으로 미세 조정하여 Reddit의 커뮤니티 언어와 일치하는 응답을 제공 할 수 있습니다.
응용 프로그램의 고유 한 기능 중 하나는 사용자가 사용하려는 언어 모델을 선택할 수 있다는 것입니다. 이 유연성은 Langchain에 의해 촉진됩니다. Langchain은 응용 프로그램이 사용자 기본 설정에 따라 다른 LLM 모델간에 원활하게 전환 할 수있는 도구입니다.
cp .env.example .env
docker build -t reddit-gpt .
docker run -d --env-file .env -p 8501:8501 reddit-gpt

