tianchi_nl2sql
1.0.0
競賽鏈接
數據集主辦方已公開,可以前往https://github.com/ZhuiyiTechnology/TableQA 下載
代碼運行環境至文末
本項目所採用的方案在復賽中的線上排名為第5,決賽最終成績排名第3。
主分支下的代碼以jupyter notebook 的形式呈現,以學習交流為目的,對原始的代碼經過一定的整理,並不會完全復現線上的結果,但效果不會差太多。
code 目錄下的model1.ipynb 與model2.ipynb為建模流程, nl2sql/utils目錄則包含了該任務所需的一些基礎函數和數據結構。
BERT-wwm, Chinese預訓練模型參數首屆中文NL2SQL挑戰賽,使用金融以及通用領域的表格數據作為數據源,提供在此基礎上標註的自然語言與SQL語句的匹配對,希望選手可以利用數據訓練出可以準確轉換自然語言到SQL的模型。
模型的輸入為一個Question + Table,輸出一個SQL 結構,該SQL 結構對應一條SQL 語句。
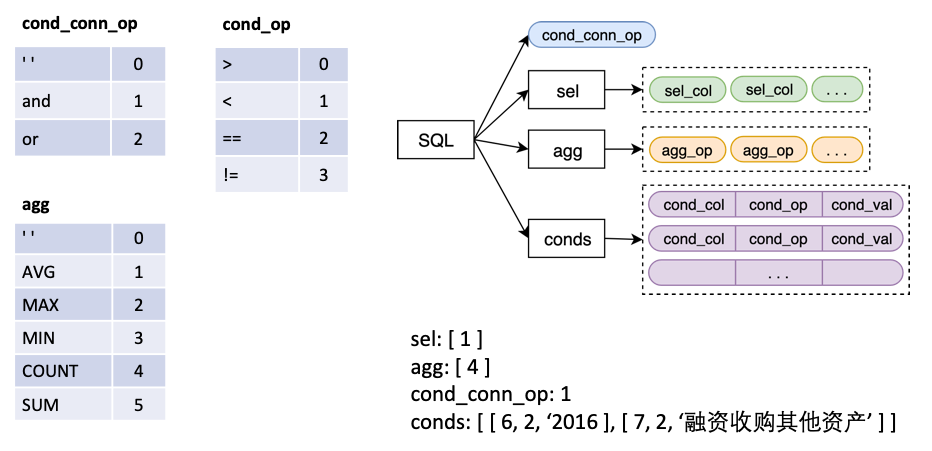
其中
sel為一個list,代表SELECT語句所選取的列agg為一個list,與sel一一對應,表示對該列做哪個聚合操作,比如sum, max, min 等conds為一個list,代表WHERE語句中的的一系列條件,每個條件是一個由(條件列,條件運算符,條件值) 構成的三元組cond_conn_op為一個int,代表conds中各條件之間的並列關係,可以是and 或者or 我們將原始的Label 做一個簡單的變換
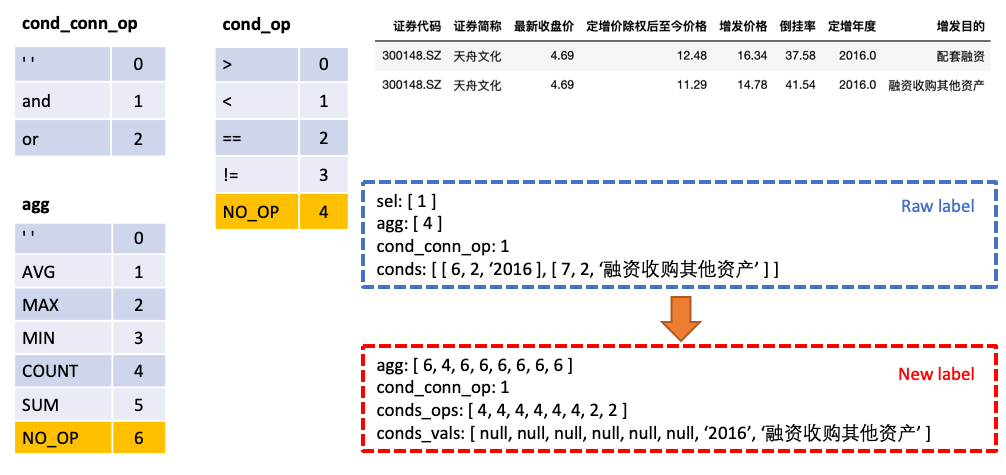
agg與sel合併, agg中對錶格中每一列都做預測,新的類別NO_OP表明該列不被選中conds分為conds_ops與conds_vals兩個部分,這麼做的原因是想分兩步進行預測。由一個模型先預測conds需要選取哪些列以及操作符,再由另一個模型預測所選取的列的比較值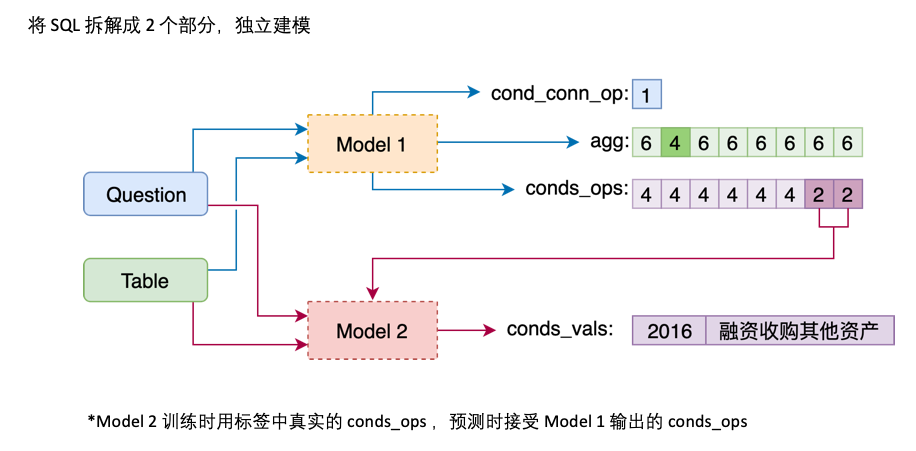
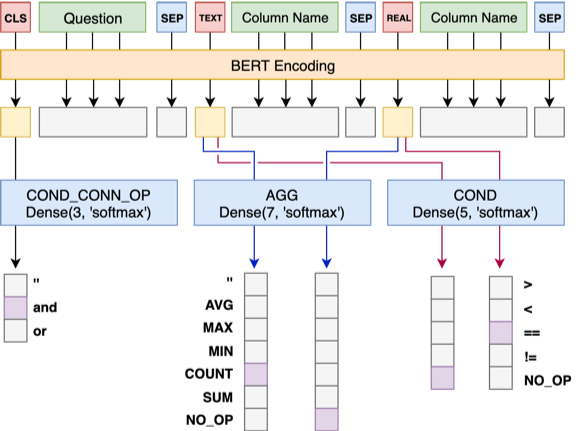
Model 1 將Question 與Header 順序連接,在每個Column 之前添加一個特殊標記, TEXT或REAL ,這兩個特殊的Token 可以從BERT 預留的未訓練過的Token 中任選兩個來代替。
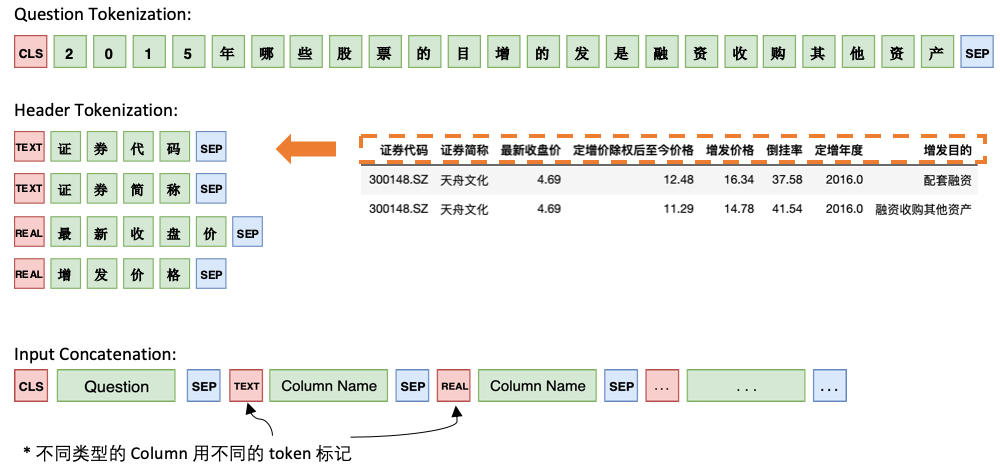
Model 1 的架構如下:
Model 2 則負責cond_val的預測。我們的思路是根據Model 1 選擇的cond_col ,枚舉cond_op與cond_val ,生成一系列的候選組合,將這些組合當成多個二分類問題來做
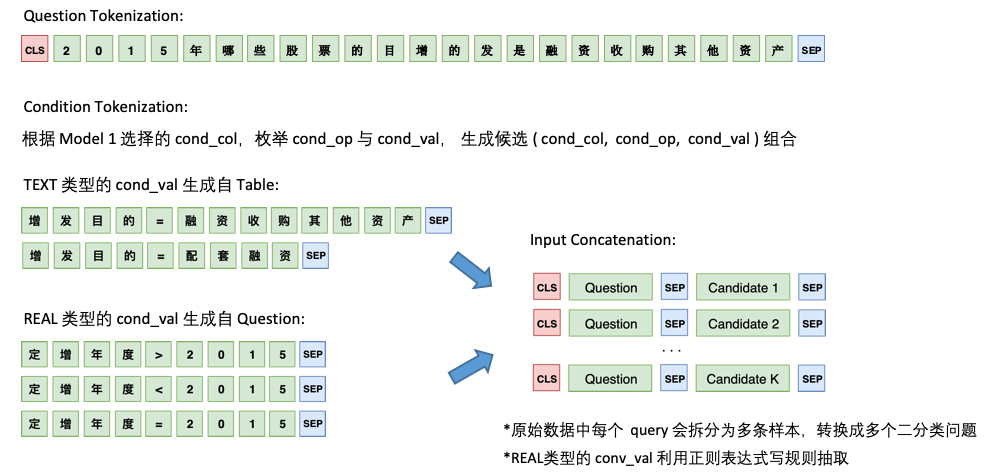
Model 2 的架構如下:

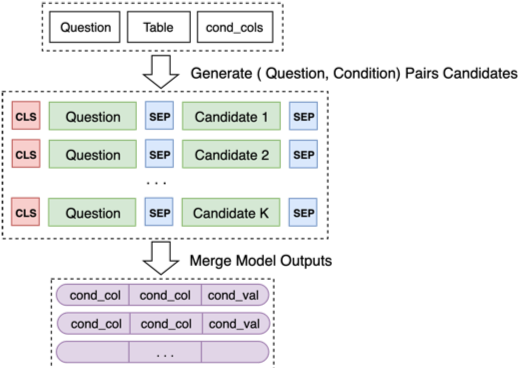
最後將Model 2 對一些列候選組合的預測合併起來
關於模型訓練中的優化,以及一些成功、不成功的idea,詳細可以見我們決賽答辯ppt。
深度學習框架: tensorflow, keras
具體版本見requirements.txt
更方便的做法是在Docker 中運行。比賽中用瞭如下Docker 鏡像
| REPOSITORY | TAG | IMAGE ID |
|---|---|---|
| tensorflow/tensorflow | nightly-gpu-py3-jupyter | 6e60684e9aa4 |
由於需要用到python3.6,使用了tensorflow nightly build 的鏡像,我將比賽時用的鏡像傳到docker hub 上了,可以通過如下命令獲取。
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

