tianchi_nl2sql
1.0.0
Enlace de competencia
El organizador del conjunto de datos se ha hecho público y se puede descargar en https://github.com/zhuiyitechnology/tableqa
Código que ejecuta el entorno hasta el final del artículo
El plan adoptado en este proyecto ocupa el quinto lugar en línea en la revancha y el tercero en los resultados finales.
El código debajo de la rama principal se presenta en forma de un cuaderno Jupyter. A los fines del aprendizaje y la comunicación, el código original se ha resuelto por una cierta cantidad y no reproducirá por completo los resultados en línea, pero el efecto no será mucho peor.
Model1.ipynb y Model2.IPynb en el directorio de código son procesos de modelado, y nl2sql/utils contiene algunas funciones básicas y estructuras de datos necesarias para esta tarea.
BERT-wwm, Chinese en esta competencia. El primer desafío chino NL2SQL utiliza datos tabulares de los campos finanzas y generales como fuentes de datos para proporcionar pares coincidentes entre el lenguaje natural y las declaraciones SQL marcadas sobre esta base. Esperamos que los jugadores puedan usar datos para entrenar modelos que puedan convertir con precisión el lenguaje natural en SQL.
La entrada al modelo es una tabla de preguntas +, y se emite una estructura SQL, que corresponde a una declaración SQL.
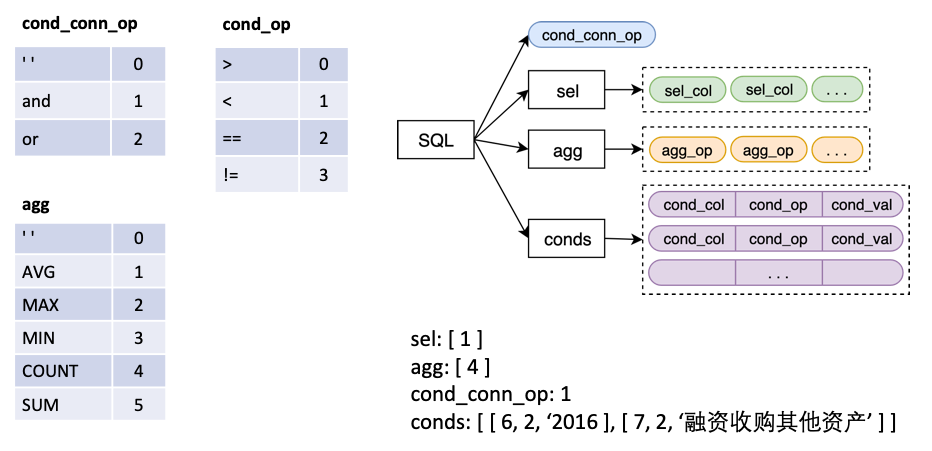
en
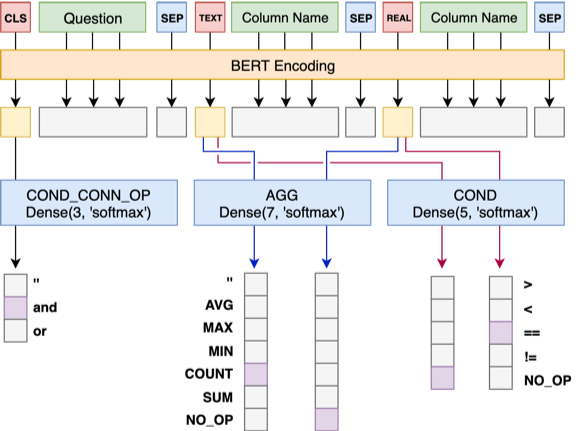
sel es una lista, que representa la columna seleccionada por la instrucción SELECTagg es una lista, correspondiente a sel , que indica qué operación de agregación se realiza en la columna, como Sum, Max, Min, etc.conds es una lista, que representa una serie de condiciones en la declaración WHERE . Cada condición es un triple compuesto de (columnas de condición, operadores de condición, valores de condición).cond_conn_op es un int, que representa la relación paralela entre las condiciones en conds , que pueden ser y o / o Hacemos una transformación simple de la etiqueta original
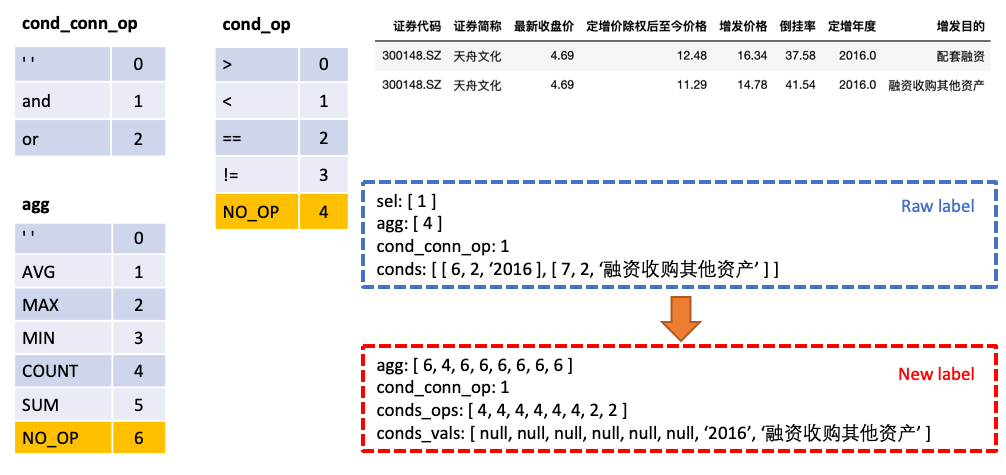
agg con sel , hacer predicciones para cada columna en la tabla en agg , y la nueva categoría NO_OP indica que la columna no está seleccionadaconds en dos partes: conds_ops y conds_vals . La razón de esto es hacer predicciones en dos pasos. Un modelo primero predice qué columnas y operadores se seleccionarán conds , y luego otro modelo predice el valor de comparación de las columnas seleccionadas. 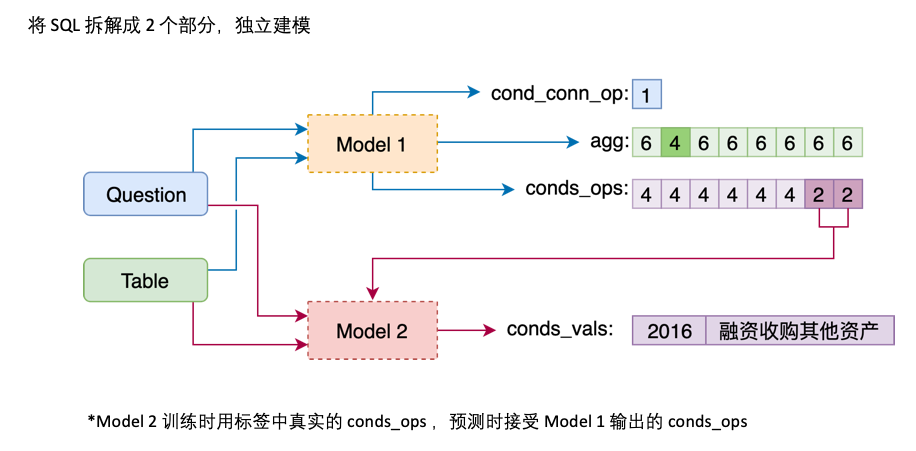
Modelo 1 Conecte la pregunta con el encabezado secuencialmente, agregando un marcador especial, TEXT o REAL antes de cada columna. Estos dos tokens especiales pueden ser reemplazados por dos de los tokens no entrenados reservados por Bert.
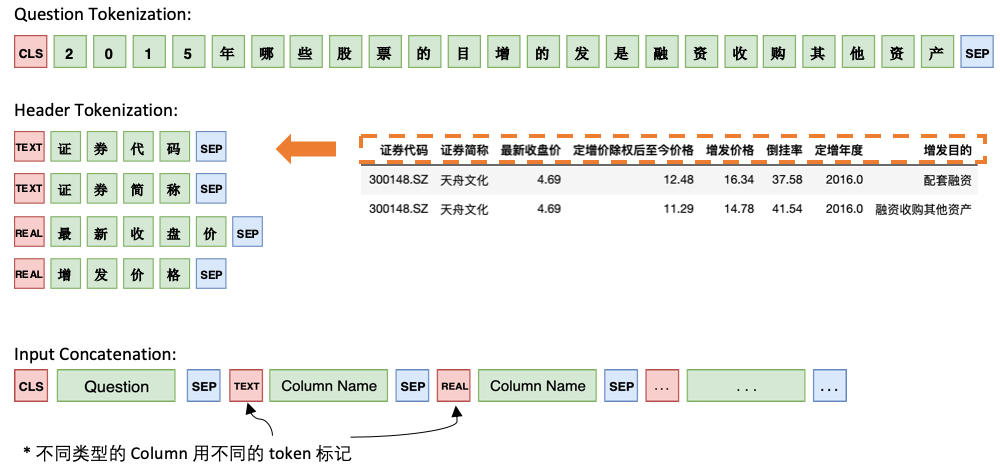
La arquitectura del modelo 1 es la siguiente:
El modelo 2 es responsable de la predicción de cond_val . Nuestra idea es enumerar cond_op y cond_val en función cond_col seleccionado por el Modelo 1, y generar una serie de combinaciones candidatas, tratando estas combinaciones como múltiples problemas de clasificación binaria.
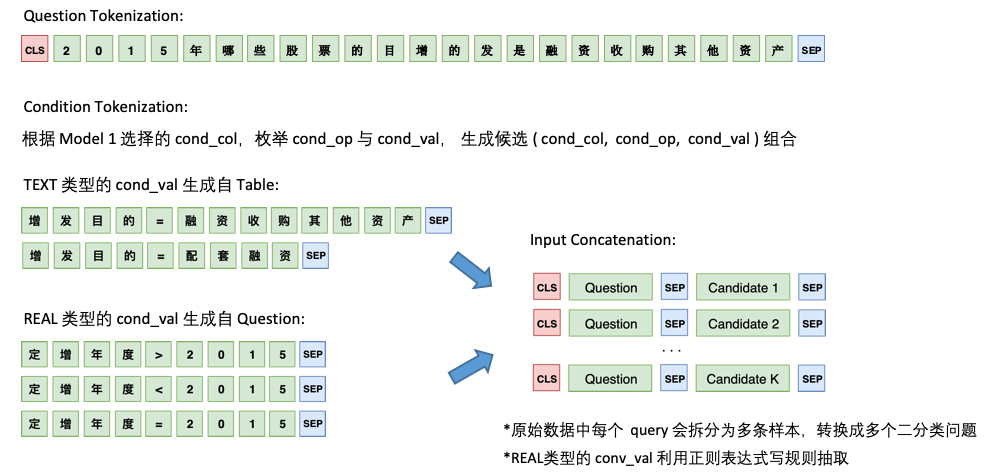
La arquitectura del modelo 2 es la siguiente:

Finalmente, fusione las predicciones del Modelo 2 para algunas combinaciones de candidatos
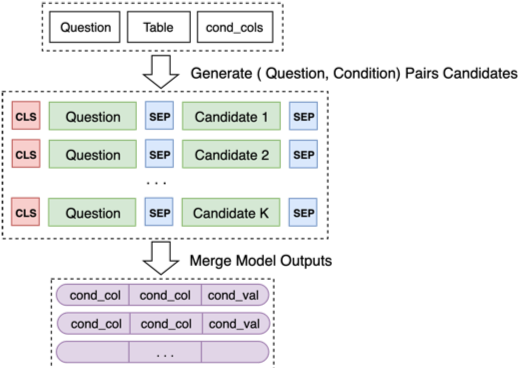
Para más detalles, consulte nuestro PPT de defensa final para su optimización en el entrenamiento de modelos y algunas ideas exitosas y no exitosas.
Marco de aprendizaje profundo: tensorflow, keras
Consulte requisitos.txt para versiones específicas
Una forma más conveniente de hacerlo es ejecutarlo en Docker. La siguiente imagen de Docker se utilizó en la competencia.
| REPOSITORIO | ETIQUETA | ID de imagen |
|---|---|---|
| tensorflow/tensorflow | Nightly-Gpu-Py3-Jupyter | 6E60684E9AA4 |
Como necesito usar Python3.6, uso la imagen de TensorFlow Nightly Build. Pasé la imagen que usé durante la competencia al Docker Hub, que se puede obtener a través del siguiente comando.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

