tianchi_nl2sql
1.0.0
Wettbewerbslink
Der Dataset -Organisator wurde veröffentlicht und kann unter https://github.com/zhuiyitechnology/tableqa heruntergeladen werden
Code -Ausführungsumgebung bis zum Ende des Artikels
Der in diesem Projekt übernommene Plan belegt im Rückkampf den fünften Online -Platz und dritte in den Endergebnissen.
Der Code unter der Hauptzweig wird in Form eines Jupyter -Notizbuchs dargestellt. Zum Zweck des Lernens und der Kommunikation wurde der ursprüngliche Code um einen bestimmten Betrag ausgesucht und wird die Online -Ergebnisse nicht vollständig reproduzieren, aber der Effekt wird nicht viel schlechter sein.
Model1.ipynb und model2.ipynb im Codeverzeichnis sind Modellierungsprozesse, und nl2sql/utils -Verzeichnis enthält einige grundlegende Funktionen und Datenstrukturen, die für diese Aufgabe erforderlich sind.
BERT-wwm, Chinese Modellparameter verwendet. Die erste chinesische NL2SQL -Herausforderung verwendet tabellarische Daten aus Finanzen und allgemeinen Feldern als Datenquellen, um passende Paare zwischen natürlicher Sprache und SQL -Anweisungen bereitzustellen, die auf dieser Grundlage gekennzeichnet sind. Wir hoffen, dass Spieler Daten verwenden können, um Modelle zu trainieren, die die natürliche Sprache genau in SQL umwandeln können.
Die Eingabe zum Modell ist eine Frage + -Tabelle, und es wird eine SQL -Struktur ausgegeben, die einer SQL -Anweisung entspricht.
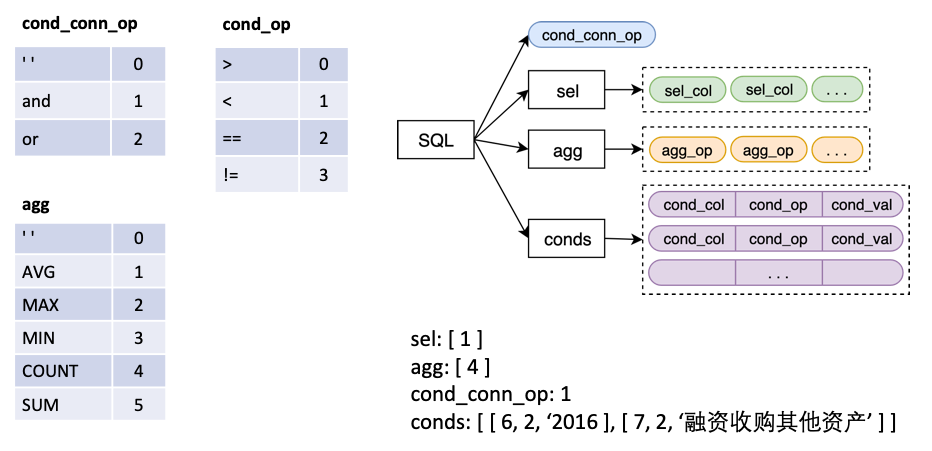
In
sel ist eine Liste, die die Spalte darstellt, die von der SELECT ausgewählt wurdeagg ist eine Liste, die sel entspricht und angibt, welche Aggregationsoperation in der Spalte durchgeführt wird, z. B. Summe, max, min usw.conds ist eine Liste, die eine Reihe von Bedingungen in der WHERE -Aussage darstellt. Jede Bedingung ist dreifach aus (Bedingungssäulen, Bedingungsoperatoren, Zustandswerte).cond_conn_op ist ein int, der die parallele Beziehung zwischen den Bedingungen in conds darstellt, die sein können und oder Wir machen eine einfache Transformation des Originaletiketts
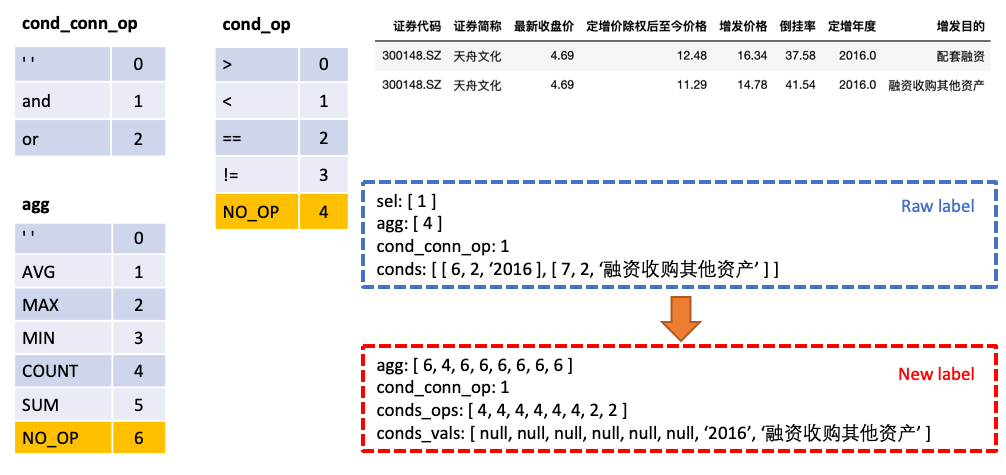
agg mit sel zusammenführen, Vorhersagen für jede Spalte in der Tabelle in agg machen, und die neue Kategorie NO_OP zeigt an, dass die Spalte nicht ausgewählt istconds in zwei Teile: conds_ops und conds_vals . Der Grund dafür ist, Vorhersagen in zwei Schritten zu treffen. Ein Modell sagt zunächst voraus, welche Spalten und Operatoren conds ausgewählt werden sollen, und dann prognostiziert ein anderes Modell den Vergleichswert der ausgewählten Spalten. 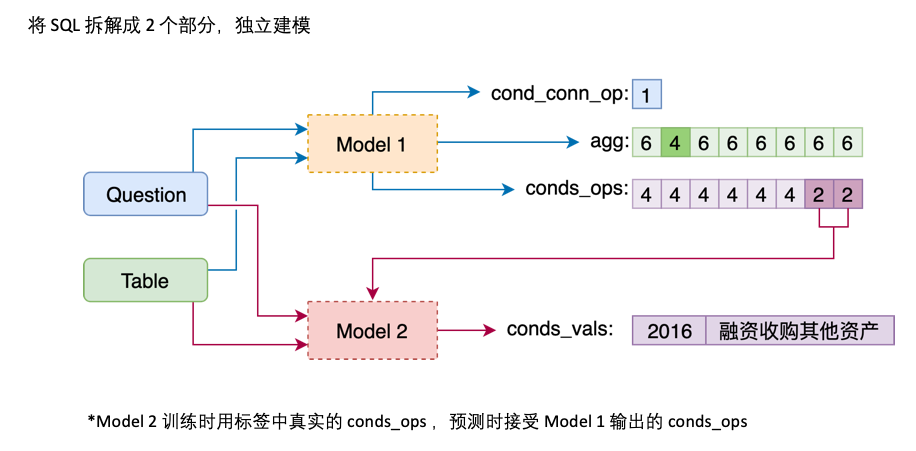
Modell 1 Verbinden Sie die Frage nacheinander mit dem Header und fügen Sie vor jeder Spalte einen speziellen Marker, TEXT oder REAL hinzu. Diese beiden speziellen Token können durch zwei der von Bert reservierten ungeübten Token ersetzt werden.
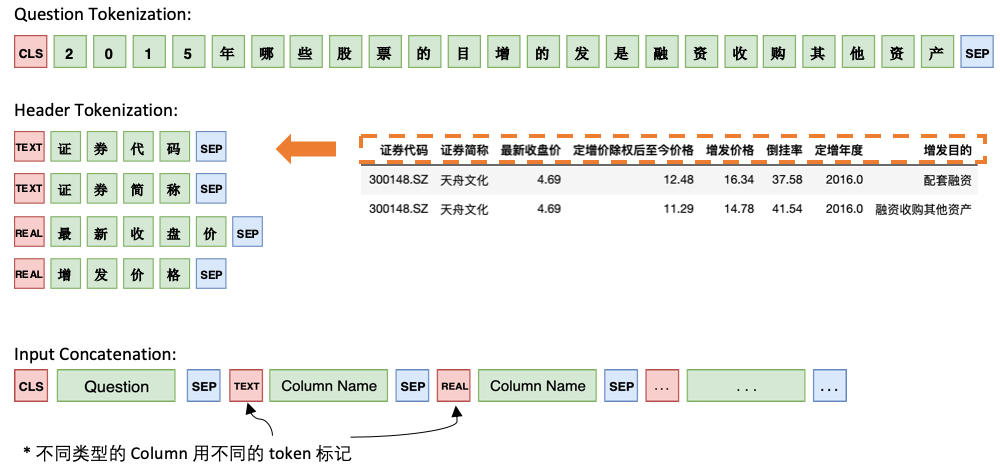
Die Architektur von Modell 1 lautet wie folgt:
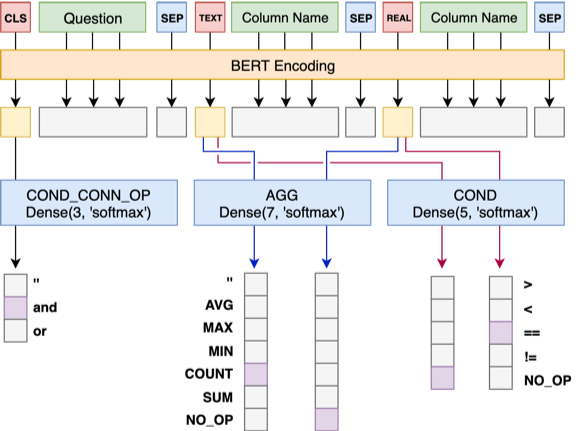
Modell 2 ist für die Vorhersage von cond_val verantwortlich. Unsere Idee ist es, cond_op und cond_val basierend auf cond_col aufzumählen und eine Reihe von Kandidatenkombinationen zu generieren, wobei diese Kombinationen als mehrfache Binärklassifizierungsprobleme behandelt werden.
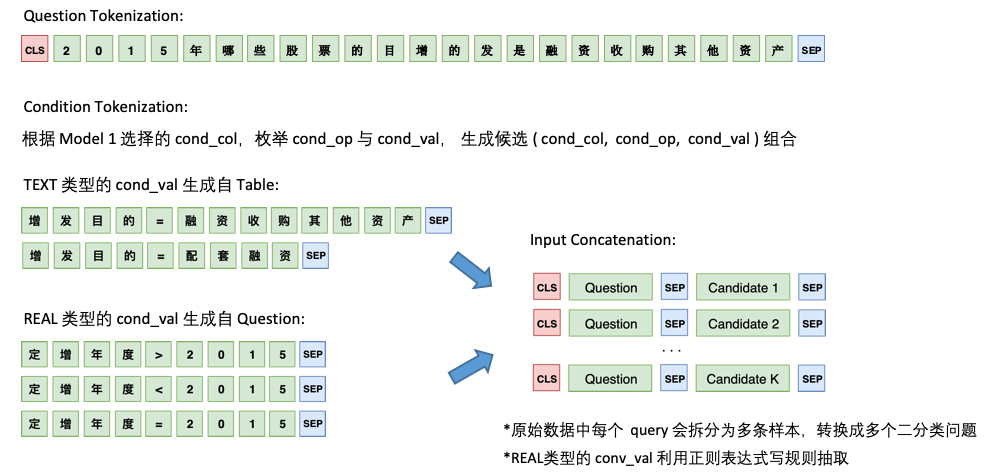
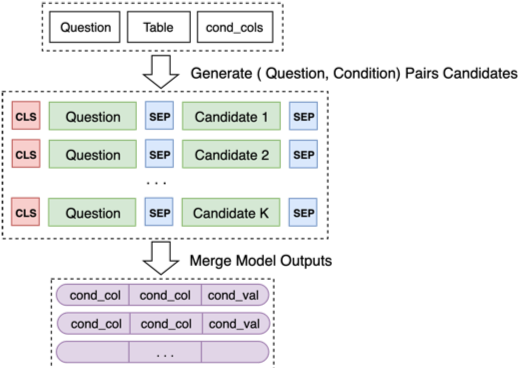
Die Architektur von Modell 2 lautet wie folgt:

Schließlich fusionieren Sie die Vorhersagen von Modell 2 für einige Kandidatenkombinationen
Weitere Informationen finden Sie in unserer endgültigen Verteidigungs -PPT zur Optimierung des Modelltrainings und einigen erfolgreichen und erfolglosen Ideen.
Deep Learning Framework: Tensorflow, Keras
Siehe Anforderungen.txt für bestimmte Versionen
Eine bequemere Möglichkeit, dies zu tun, besteht darin, es in Docker auszuführen. Das folgende Docker -Bild wurde im Wettbewerb verwendet
| Repository | ETIKETT | Bild -ID |
|---|---|---|
| Tensorflow/Tensorflow | Nachtgpu-Py3-Jupyter | 6e60684e9aa4 |
Da ich Python3.6 verwenden muss, verwende ich das Bild von TensorFlow Nightly Build. Ich habe das Bild übergeben, das ich während des Wettbewerbs an den Docker -Hub verwendet habe, der durch den folgenden Befehl erhalten werden kann.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

