tianchi_nl2sql
1.0.0
Lien de compétition
L'organisateur de l'ensemble de données a été rendu public et peut être téléchargé sur https://github.com/zhuiyitechnology/Tableqa
Code exécutant l'environnement jusqu'à la fin de l'article
Le plan adopté dans ce projet se classe cinquième en ligne dans le match revanche et troisième dans les résultats finaux.
Le code sous la branche principale est présenté sous la forme d'un cahier de jupyter. Aux fins de l'apprentissage et de la communication, le code d'origine a été réglé pour un certain montant et ne reproduira pas complètement les résultats en ligne, mais l'effet ne sera pas bien pire.
Model1.Ipynb et Model2.Ipynb dans le répertoire de code sont des processus de modélisation, et nl2sql/utils contient certaines fonctions de base et structures de données requises pour cette tâche.
BERT-wwm, Chinese dans ce concours. Le premier défi chinois NL2SQL utilise des données tabulaires des champs financiers et généraux comme sources de données pour fournir des paires correspondantes entre le langage naturel et les instructions SQL marquées sur cette base. Nous espérons que les joueurs pourront utiliser des données pour former des modèles qui peuvent convertir avec précision le langage naturel en SQL.
L'entrée du modèle est un tableau de question +, et une structure SQL est sortie, ce qui correspond à une instruction SQL.
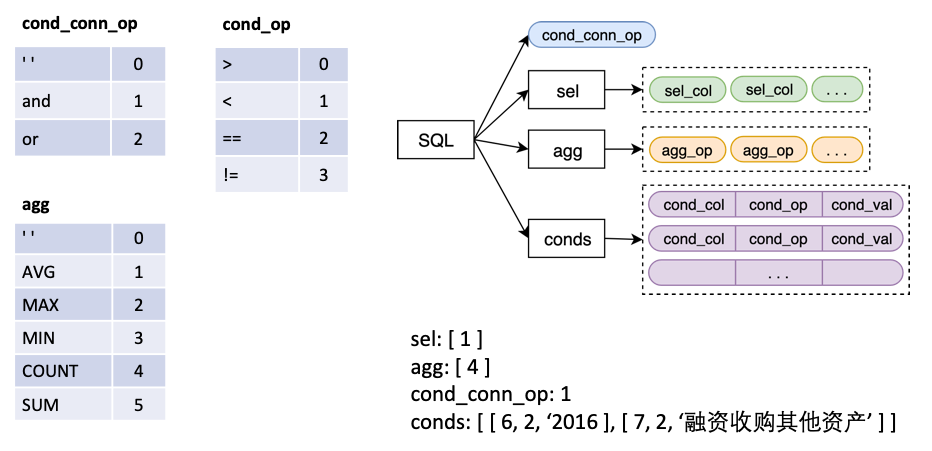
dans
sel est une liste, représentant la colonne sélectionnée par l'instruction SELECTagg est une liste, correspondant à sel , indiquant quelle opération d'agrégation est effectuée sur la colonne, telle que SUM, MAX, MIN, etc.conds est une liste, représentant une série de conditions dans la déclaration WHERE . Chaque condition est un triple composé de (colonnes de condition, opérateurs de conditions, valeurs de condition).cond_conn_op est un int, représentant la relation parallèle entre les conditions de conds , qui peuvent être et ou Nous faisons une simple transformation de l'étiquette d'origine
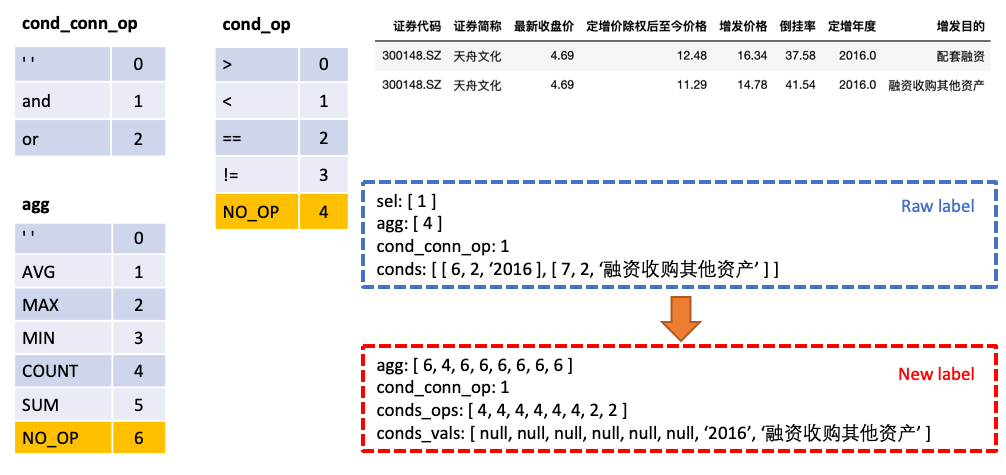
agg avec sel , faire des prédictions pour chaque colonne du tableau dans agg , et la nouvelle catégorie NO_OP indique que la colonne n'est pas sélectionnéeconds en deux parties: conds_ops et conds_vals . La raison en est de faire des prédictions en deux étapes. Un modèle prédit d'abord les colonnes et les opérateurs à sélectionner conds , puis un autre modèle prédit la valeur de comparaison des colonnes sélectionnées. 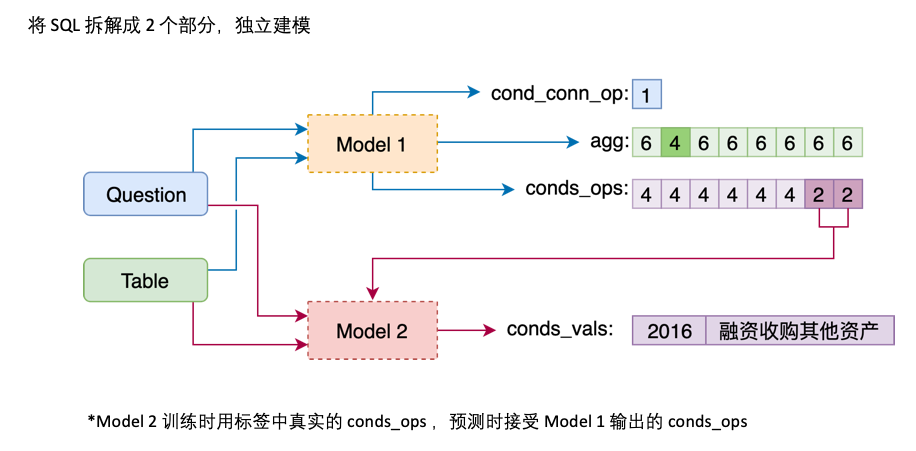
Modèle 1 Connectez la question à l'en-tête séquentiellement, en ajoutant un marqueur spécial, TEXT ou REAL avant chaque colonne. Ces deux jetons spéciaux peuvent être remplacés par deux des jetons non entraînés réservés par Bert.
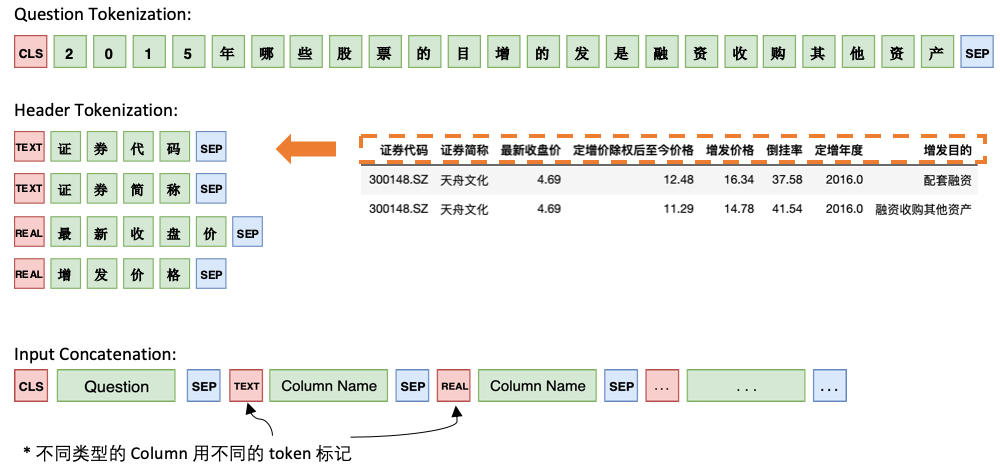
L'architecture du modèle 1 est la suivante:
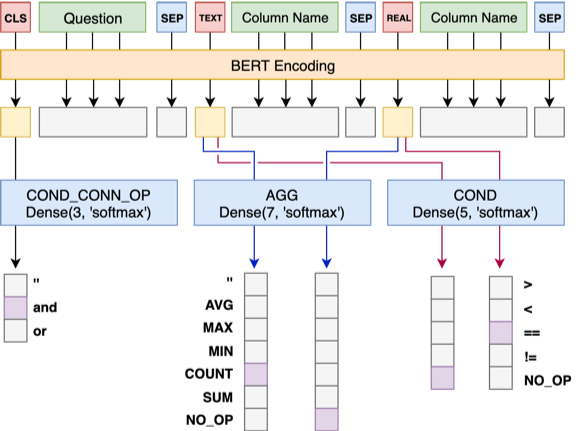
Le modèle 2 est responsable de la prédiction de cond_val . Notre idée est d'énumérer cond_op et cond_val sur la base cond_col sélectionné par le modèle 1, et de générer une série de combinaisons de candidats, traitant ces combinaisons comme plusieurs problèmes de classification binaire.
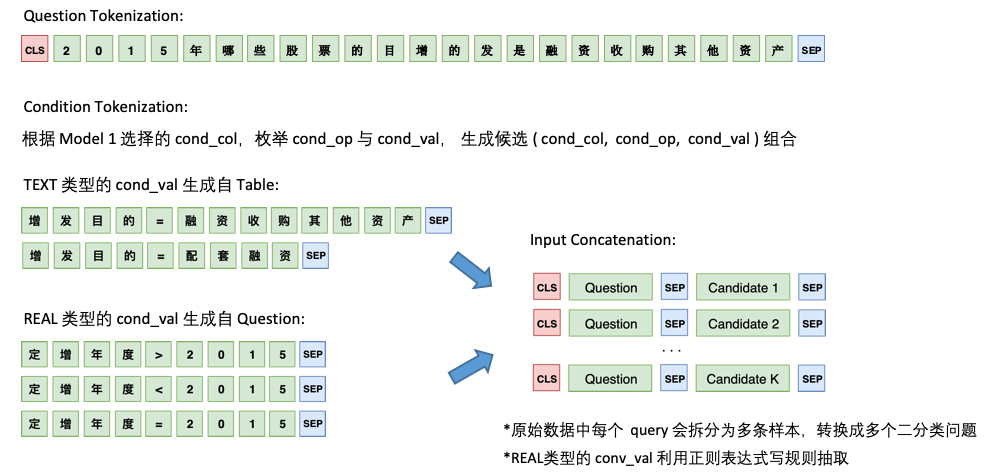
L'architecture du modèle 2 est la suivante:

Enfin, fusionnez les prédictions du modèle 2 pour certaines combinaisons de candidats
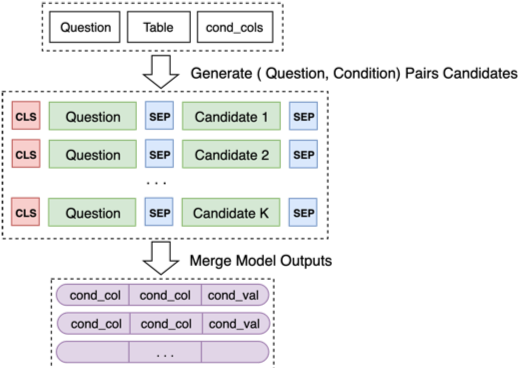
Pour plus de détails, veuillez consulter notre Final Defense PPT pour l'optimisation dans la formation des modèles et quelques idées réussies et infructueuses.
Cadre d'apprentissage en profondeur: Tensorflow, Keras
Voir exigences.txt pour des versions spécifiques
Un moyen plus pratique de le faire est de l'exécuter dans Docker. L'image Docker suivante a été utilisée dans la compétition
| DÉPÔT | ÉTIQUETER | ID d'image |
|---|---|---|
| Tensorflow / Tensorflow | nocturne-gpu-py3-jupyter | 6E60684E9AA4 |
Comme j'ai besoin d'utiliser Python3.6, j'utilise l'image de TensorFlow Nightly Build. J'ai passé l'image que j'ai utilisée lors de la compétition au Docker Hub, qui peut être obtenue via la commande suivante.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

