tianchi_nl2sql
1.0.0
Competition link
The dataset organizer has been made public and can be downloaded at https://github.com/ZhuiyiTechnology/TableQA
Code running environment to the end of the article
The plan adopted in this project ranks fifth online in the rematch and third in the final results.
The code under the main branch is presented in the form of a jupyter notebook. For the purpose of learning and communication, the original code has been sorted out for a certain amount and will not completely reproduce the online results, but the effect will not be much worse.
Model1.ipynb and model2.ipynb in the code directory are modeling processes, and nl2sql/utils directory contains some basic functions and data structures required for this task.
BERT-wwm, Chinese pre-trained model parameters in this competition. The first Chinese NL2SQL Challenge uses tabular data from finance and general fields as data sources to provide matching pairs between natural language and SQL statements marked on this basis. We hope that players can use data to train models that can accurately convert natural language to SQL.
The input to the model is a Question + Table, and an SQL structure is output, which corresponds to a SQL statement.
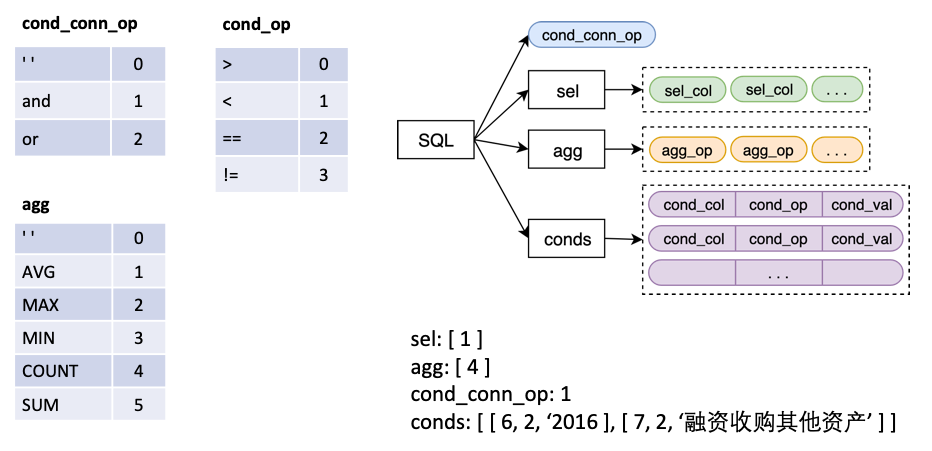
in
sel is a list, representing the column selected by the SELECT statementagg is a list, corresponding to sel , indicating which aggregation operation is performed on the column, such as sum, max, min, etc.conds is a list, representing a series of conditions in the WHERE statement. Each condition is a triple composed of (condition columns, condition operators, condition values).cond_conn_op is an int, representing the parallel relationship between the conditions in conds , which can be and or We make a simple transformation of the original Label
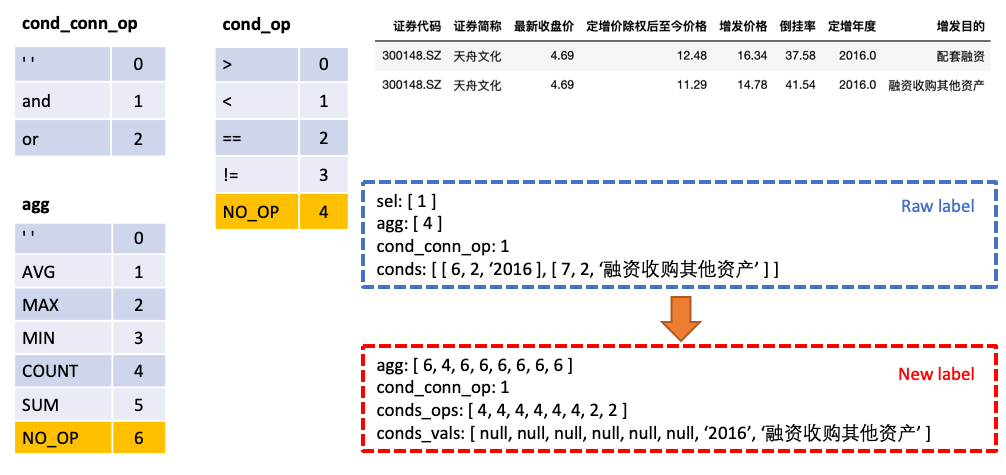
agg with sel , make predictions for each column in the table in agg , and the new category NO_OP indicates that the column is not selectedconds into two parts: conds_ops and conds_vals . The reason for this is to make predictions in two steps. A model first predicts which columns and operators to be selected conds , and then another model predicts the comparison value of the selected columns. 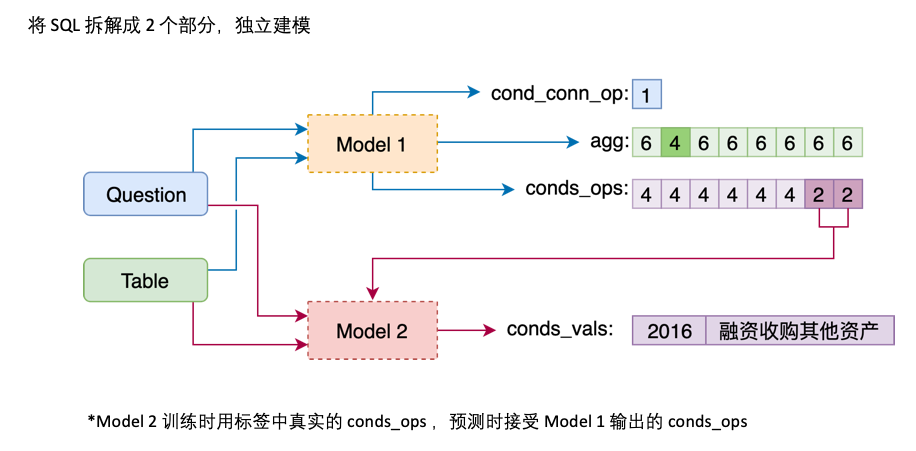
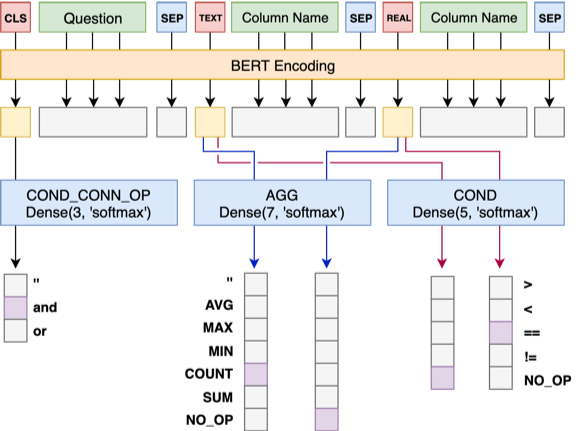
Model 1 Connect the Question with the Header sequentially, adding a special marker, TEXT or REAL before each Column. These two special tokens can be replaced by two of the untrained tokens reserved by BERT.
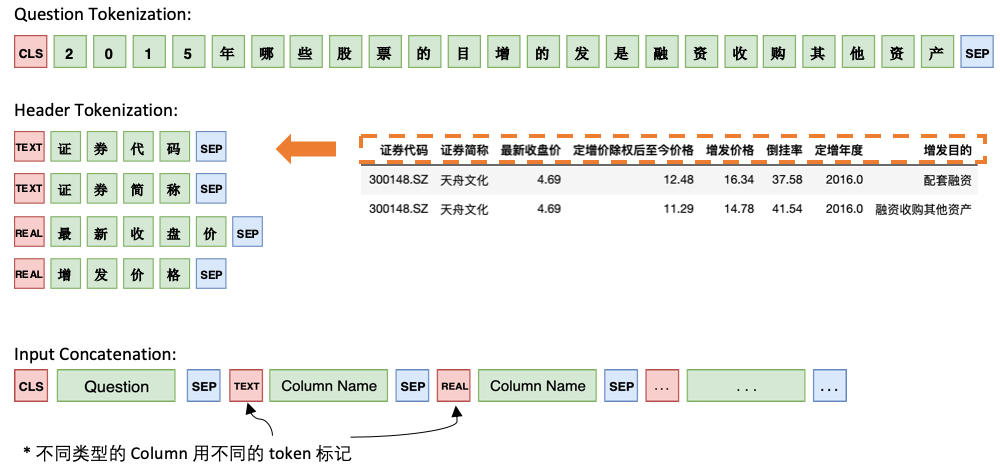
The architecture of Model 1 is as follows:
Model 2 is responsible for the prediction of cond_val . Our idea is to enumerate cond_op and cond_val based on cond_col selected by Model 1, and generate a series of candidate combinations, treating these combinations as multiple binary classification problems.
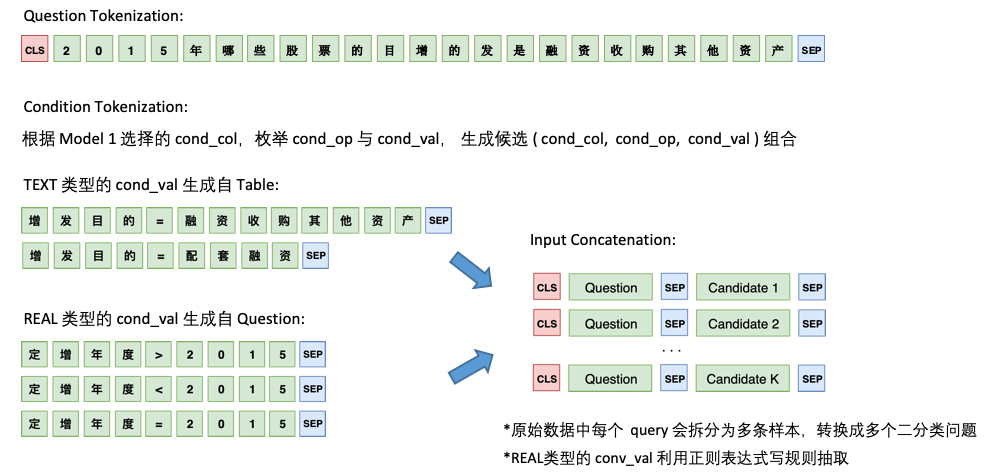
The architecture of Model 2 is as follows:

Finally, merge the predictions of Model 2 for some candidate combinations
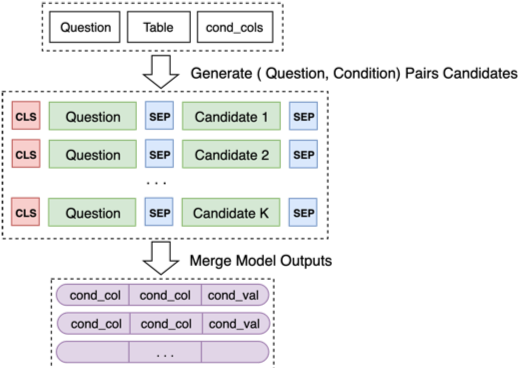
For details, please see our final defense ppt for optimization in model training and some successful and unsuccessful ideas.
Deep learning framework: tensorflow, keras
See requirements.txt for specific versions
A more convenient way to do this is to run it in Docker. The following Docker image was used in the competition
| REPOSITORY | TAG | IMAGE ID |
|---|---|---|
| tensorflow/tensorflow | nightly-gpu-py3-jupyter | 6e60684e9aa4 |
Since I need to use python3.6, I use the image of tensorflow nightly build. I passed the image I used during the competition to the docker hub, which can be obtained through the following command.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

