tianchi_nl2sql
1.0.0
경쟁 링크
데이터 세트 주최자는 공개되었으며 https://github.com/zhuiyitechnology/tableqa에서 다운로드 할 수 있습니다.
기사 끝까지 환경 실행 코드
이 프로젝트에 채택 된 계획은 재 대결에서 온라인으로 5 위, 최종 결과에서 3 위를 차지합니다.
메인 브랜치 아래의 코드는 Jupyter 노트북 형태로 표시됩니다. 학습 및 커뮤니케이션을 위해 원래 코드는 일정 금액으로 정렬되었으며 온라인 결과를 완전히 재현하지는 않지만 그 효과는별로 나쁘지 않습니다.
코드 디렉토리의 model1.ipynb 및 model2.ipynb는 모델링 프로세스이며 nl2sql/utils 디렉토리에는이 작업에 필요한 몇 가지 기본 기능 및 데이터 구조가 포함되어 있습니다.
BERT-wwm, Chinese 미리 훈련 된 모델 매개 변수를 사용했습니다. 최초의 중국 NL2SQL 챌린지는 금융 및 일반 필드의 표식 데이터를 데이터 소스로 사용하여 자연어와 SQL 문 사이의 일치하는 쌍을 제공합니다. 우리는 플레이어가 데이터를 사용하여 자연어를 SQL로 정확하게 변환 할 수있는 모델을 훈련시킬 수 있기를 바랍니다.
모델에 대한 입력은 질문 + 테이블이며 SQL 구조는 출력이며 SQL 문에 해당합니다.
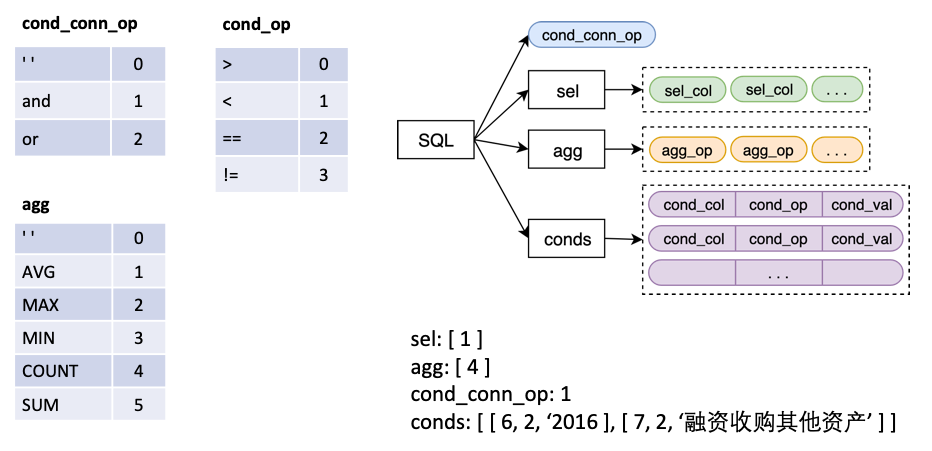
~에
sel SELECT 문으로 선택한 열을 나타내는 목록입니다.agg sel 에 해당하는 목록이며, SUM, MAX, MIN 등과 같은 열에서 어떤 집계 작업이 수행되는지를 나타냅니다.conds WHERE 문에서 일련의 조건을 나타내는 목록입니다. 각 조건은 트리플로 구성됩니다 (조건 열, 조건 연산자, 조건 값).cond_conn_op 는 int이며, conds 의 조건들 사이의 평행 관계를 나타내는 것입니다. 우리는 원래 레이블을 간단하게 변환합니다
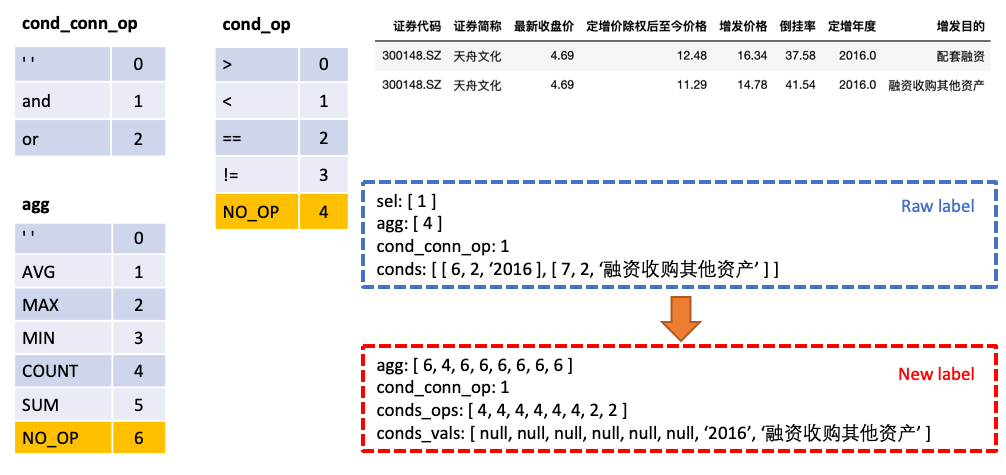
agg sel 과 병합하고 agg 의 테이블에있는 각 열을 예측하고 새로운 카테고리 NO_OP 는 열이 선택되지 않았 음을 나타냅니다.conds conds_ops 와 conds_vals 두 부분으로 나눕니다. 그 이유는 두 단계로 예측을하는 것입니다. 모델은 먼저 conds 어떤 열과 연산자가 선택 될지 예측 한 다음 다른 모델은 선택된 열의 비교 값을 예측합니다. 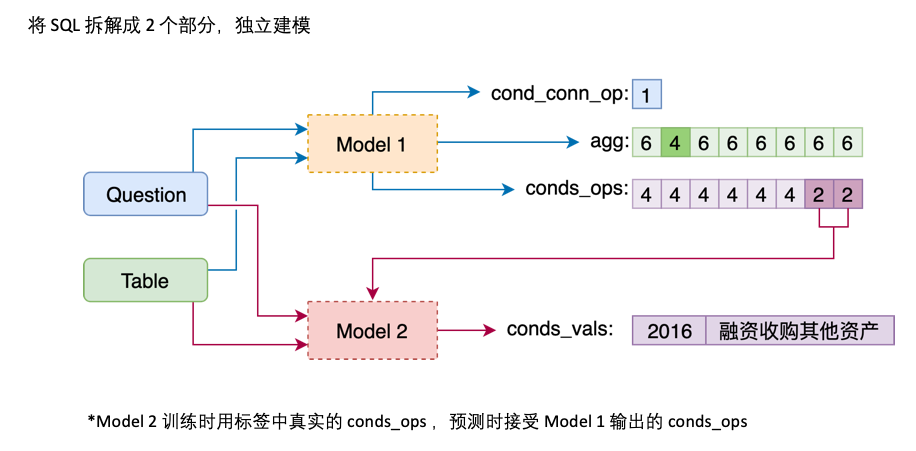
Model 1 각 열에 특수 마커, TEXT 또는 REAL 를 추가하여 질문을 헤더와 순차적으로 연결합니다. 이 두 특수 토큰은 Bert가 예약 한 훈련되지 않은 두 가지 토큰으로 교체 할 수 있습니다.
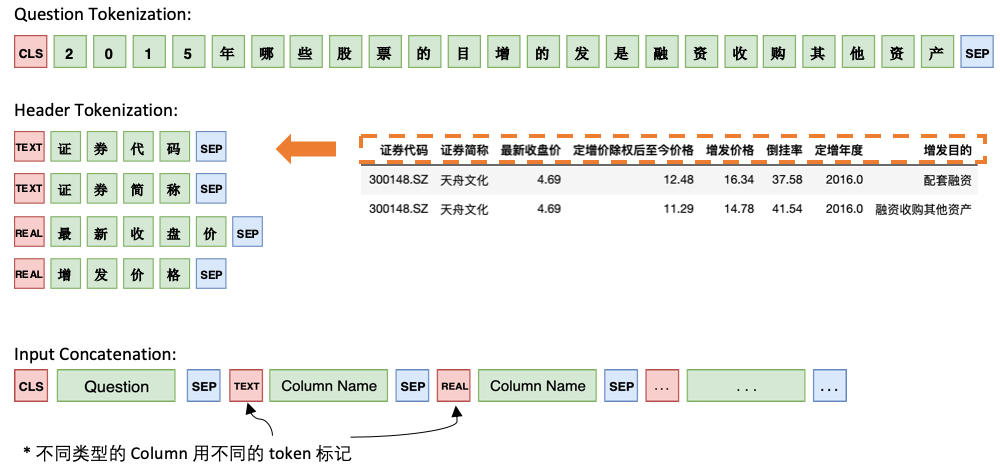
모델 1의 아키텍처는 다음과 같습니다.
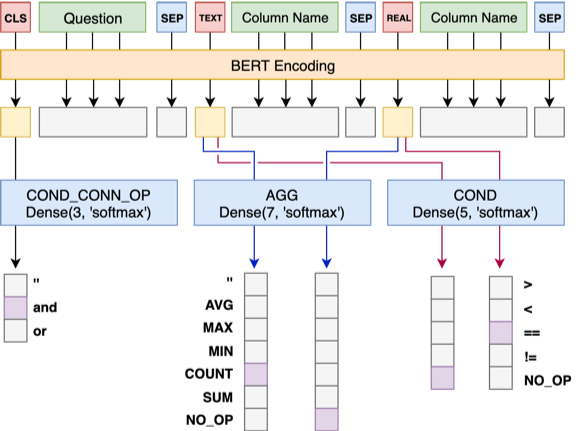
모델 2는 cond_val 의 예측을 담당합니다. 우리의 아이디어는 모델 1에서 선택한 cond_col 기반으로 cond_op 및 cond_val 열거하고 일련의 후보 조합을 생성하여 이러한 조합을 여러 이진 분류 문제로 취급하는 것입니다.
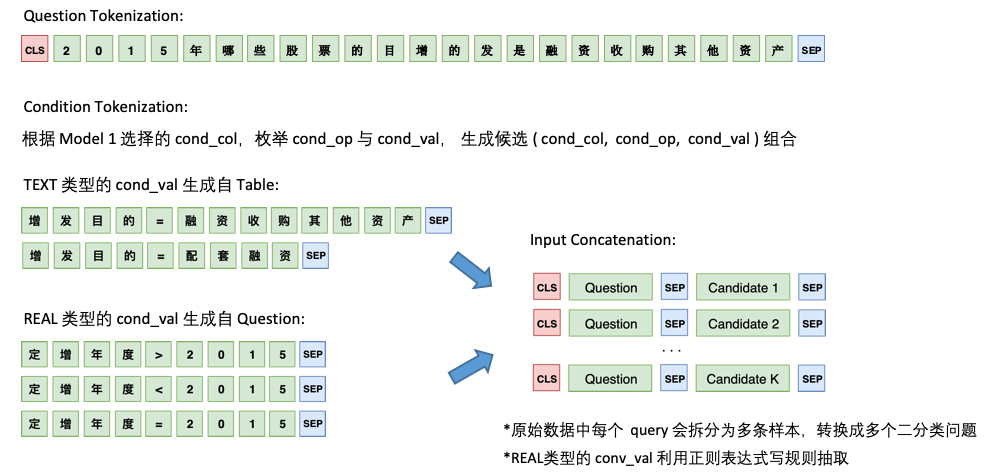
모델 2의 아키텍처는 다음과 같습니다.

마지막으로 일부 후보 조합에 대한 모델 2의 예측을 병합하십시오.
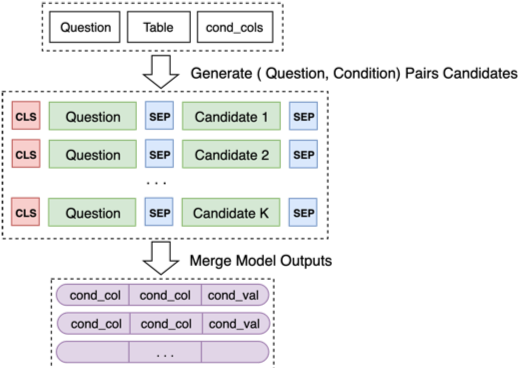
자세한 내용은 모델 교육 최적화와 성공적이고 실패한 아이디어에 대한 최종 Defense PPT를 참조하십시오.
딥 러닝 프레임 워크 : Tensorflow, Keras
특정 버전은 요구 사항을 참조하십시오
더 편리한 방법은 Docker에서 실행하는 것입니다. 다음과 같은 도커 이미지가 경쟁에서 사용되었습니다
| 저장소 | 꼬리표 | 이미지 ID |
|---|---|---|
| 텐서 플로우/텐서 플로우 | 야간 GPU-PY3-JUPYTER | 6E60684E9AA4 |
Python3.6을 사용해야하므로 Tensorflow Nightly Build의 이미지를 사용합니다. 경쟁 중에 사용한 이미지를 Docker Hub와 전달했습니다.이 이미지는 다음 명령을 통해 얻을 수 있습니다.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

