tianchi_nl2sql
1.0.0
Конкурсная ссылка
Организатор набора данных был обнародован и может быть загружен по адресу https://github.com/zhuiyitechnology/tableqa
Среда запуска кода до конца статьи
План, принятый в этом проекте, занимает пятое онлайн в реванше и третьем в окончательных результатах.
Код под основной филиалом представлен в форме ноутбука Юпитера. В целях обучения и общения исходный код был отсортирован на определенную сумму и не будет полностью воспроизводит результаты онлайн, но эффект не будет намного хуже.
Model1.ipynb и model2.ipynb в каталоге кода - это процессы моделирования, а каталог nl2sql/utils содержит некоторые основные функции и структуры данных, необходимые для этой задачи.
BERT-wwm, Chinese предварительно обученные параметры модели в этом конкуренте. Первая китайская задача NL2SQL использует табличные данные из финансов и общих областей в качестве источников данных для обеспечения соответствующих пар между естественным языком и операторами SQL, отмеченными на этой основе. Мы надеемся, что игроки могут использовать данные для обучения моделей, которые могут точно преобразовать естественный язык в SQL.
Вход в модель - это таблица «Вопрос +», а структура SQL - вывод, которая соответствует оператору SQL.
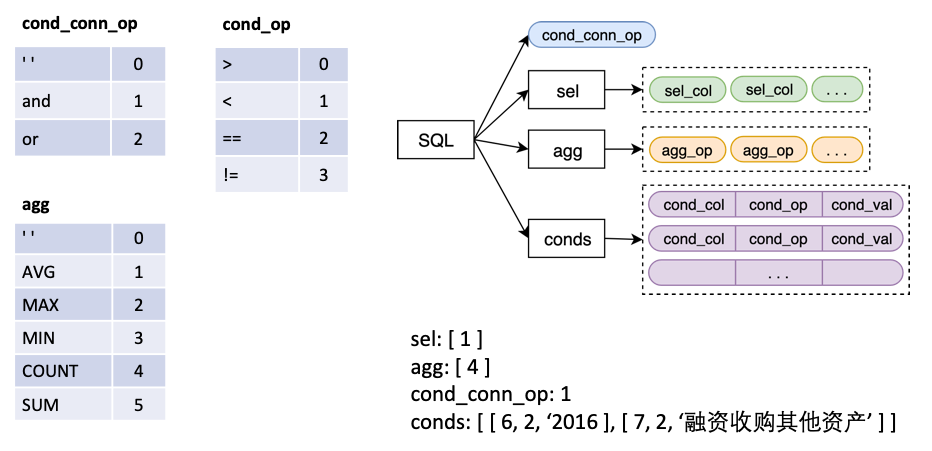
в
sel - это список, представляющий столбец, выбранный оператором SELECTagg - это список, соответствующий sel , указывающий, какая операция агрегации выполняется в столбце, например, сумме, максимум, мин и т. Д.conds - это список, представляющий серию условий в утверждении WHERE . Каждое условие состоит из тройного, состоящего из (столбцов условий, операторов состояния, значений условий).cond_conn_op - это int, представляющий параллельные отношения между условиями в conds , которые могут быть и или или или или или Мы делаем простое преобразование оригинальной этикетки
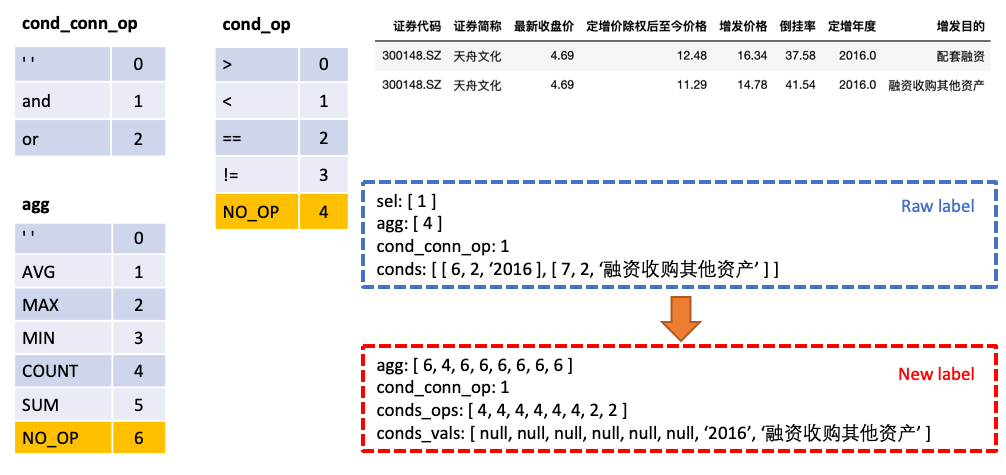
agg с sel , делайте прогнозы для каждого столбца в таблице в agg , а новая категория NO_OP указывает, что столбец не выбранconds на две части: conds_ops и conds_vals . Причина этого состоит в том, чтобы сделать прогнозы в двух шагах. Модель сначала предсказывает, какие столбцы и операторы будут выбраны conds , а затем другая модель предсказывает значение сравнения выбранных столбцов. 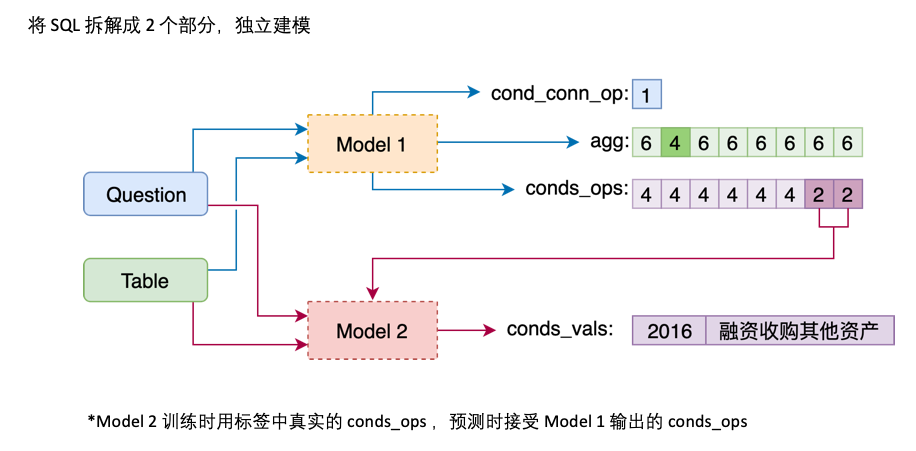
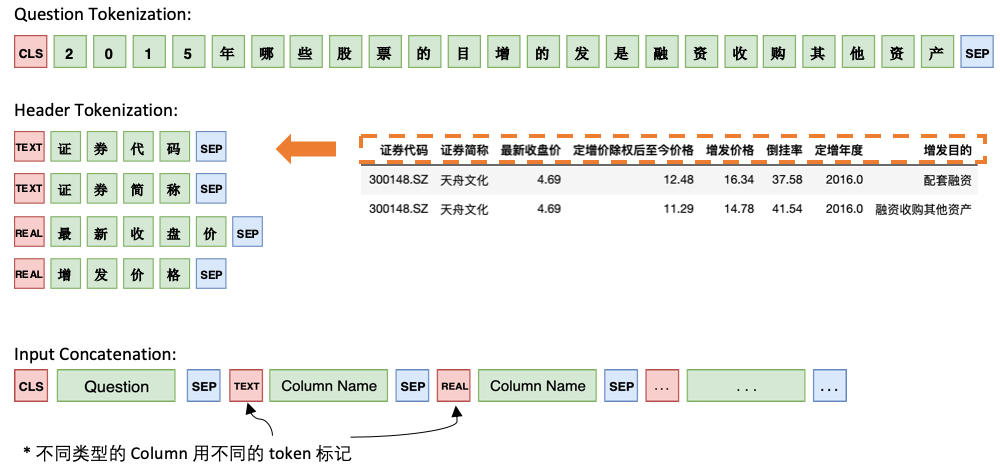
Модель 1 Подключите вопрос с последовательным заголовком, добавив специальный маркер, TEXT или REAL перед каждым столбцом. Эти два специальных токена могут быть заменены двумя неподготовленными токенами, зарезервированными Бертом.
Архитектура модели 1 заключается в следующем:
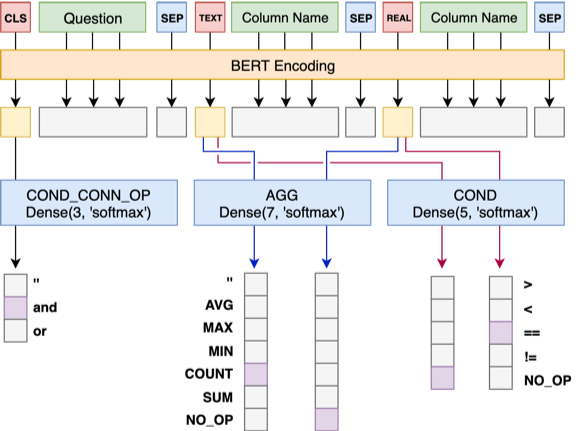
Модель 2 отвечает за прогноз cond_val . Наша идея состоит в том, чтобы перечислить cond_op и cond_val на основе cond_col выбранной моделью 1, и генерировать серию комбинаций кандидатов, рассматривая эти комбинации как проблемы с множественной бинарной классификацией.
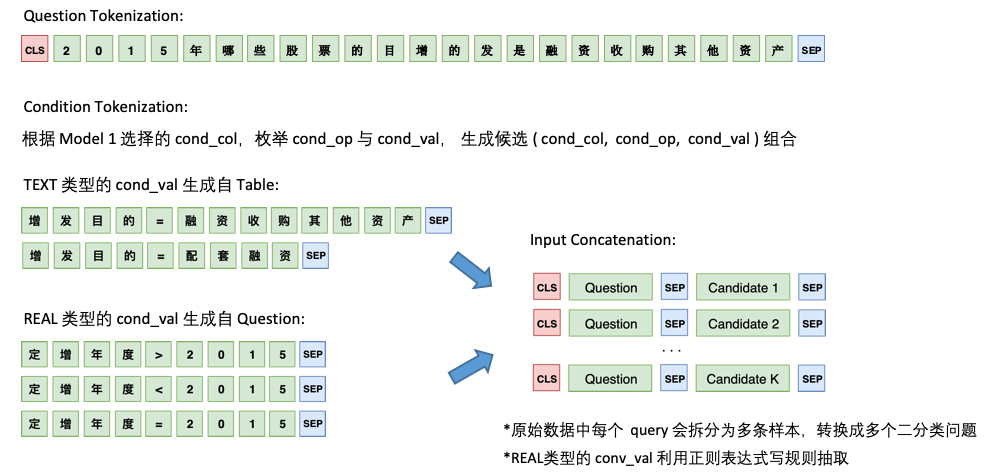
Архитектура модели 2 заключается в следующем:

Наконец, объедините прогнозы модели 2 для некоторых комбинаций кандидатов
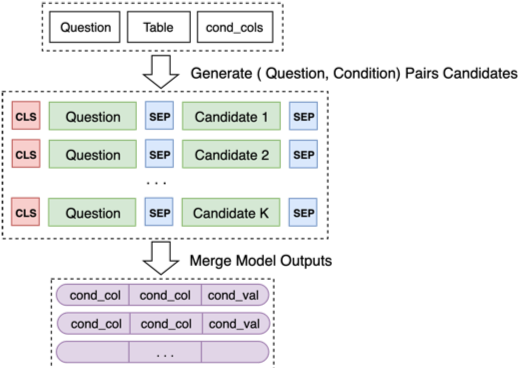
Для получения подробной информации, пожалуйста, смотрите нашу окончательную защиту PPT для оптимизации в модельном обучении и некоторые успешные и неудачные идеи.
Глубокая структура обучения: Tensorflow, Keras
См. TEDS.TXT для конкретных версий
Более удобный способ сделать это - запустить его в Docker. Следующее изображение Docker использовалось в конкурсе
| Репозиторий | ЯРЛЫК | Идентификатор изображения |
|---|---|---|
| Tensorflow/Tensorflow | Ночной-гп-пи-3-юпитер | 6E60684E9AA4 |
Поскольку мне нужно использовать Python3.6, я использую изображение Tensorflow Nightly Build. Я прошел изображение, которое я использовал во время соревнований в концентраторе Docker, который можно получить с помощью следующей команды.
docker pull beader/tensorflow:nightly-gpu-py3-jupyter

