Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopii是一種個人識別信息(PII)掃描儀,使用光學角色識別(OCR),正則表達式列表和自然語言處理(NLP)來搜索政府ID的公共面向公共位置,地址,圖像,PDFS和文檔中的電子郵件,電子郵件。
在網絡安全空間中,PII洩漏經常被忽略。在Redd Labs,我們始終尋找不同和創新的方法來提出組織和服務所需的網絡安全解決方案。我們遇到了大量的組織,這些組織的配置不正確。這導致僱員和客戶PII一直洩漏,提供有關其起源,ID號,聯繫信息及其位置的惡意派對敏感信息。
這就是為什麼我們被創建的章魚是一種工具,該工具可以演示和檢測到自動化Internet上洩漏的PII和敏感文檔的發現和提取的容易。
pip install -r requirements.txt安裝所有依賴項。sudo pacman -Syu tesseract上sudo apt install tesseract-ocr -y 。python -m spacy download en_core_web_sm在本地安裝Spacy語言定義。安裝上述內容後,您將全部設置。
要運行章魚,類型
python3 octopii.py <location to scan>
<location to scan>是文件或目錄。
Octopii目前通過文件系統路徑,S3 URL和Apache Open Directory列表支持本地掃描。您還可以作為參數提供單個圖像URL或文件。
我們為您提供了一個包含樣品PII的dummy-pii/文件夾,供您測試章魚。作為參數傳遞,您將獲得以下輸出
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
創建了一個名為output.txt的文件,其中包含工具的輸出。該文件是實時附加的。
Octopii使用Tesseract進行光學特徵識別(OCR)和NLTK進行自然語言處理(NLP)來檢測個人可識別信息的字符串。這是通過以下步驟完成的:
章魚掃描圖像(JPG和PNG)和文檔(PDF,DOC,TXT等)。它支持3個來源:
圖像是通過Python Imaging庫(PIL)檢測到的,並使用OpenCV打開。 PDF被轉換為圖像列表,並通過OCR進行掃描。基於文本的文件類型被讀取為字符串,並在沒有OCR的情況下進行掃描。
二進制分類圖像檢測技術(稱為“ Haar Cascade”)用於檢測圖像中的面孔。此存儲庫中提供了預訓練的級聯模型,其中包含用於使用OpenCV的級聯數據。可以在同一PII圖像中檢測到多個面孔,並重新播放檢測到的面數。
然後將圖像“固定”以進行文本提取,並通過以下圖像轉換步驟:
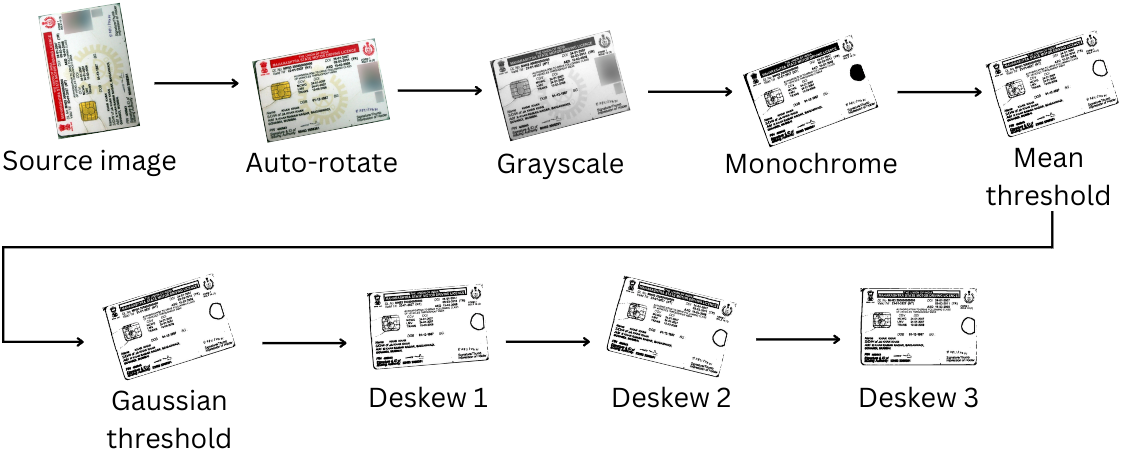
由於這些步驟剝離了圖像數據(包括照片中的顏色),因此此圖像清潔過程在嘗試檢測後發生。
Tesseract用於從圖像/文件中獲取所有文本字符串。然後將其歸為字符串列表,由newline字符( n')和Space('')劃分。亂七八糟的文本(例如null字符串和單個字符)從此列表中丟棄,從而導致潛在單詞的“可理解”列表。
然後將此單詞列表饋送到類似的檢查器功能中。此功能使用格式塔模式匹配來比較從PII文檔中提取的每個單詞與definitions.json中的關鍵字列表。每次清潔一次一次檢查一次。計數關鍵字的單詞的次數,用於得出置信度得分。當在這些掃描中重複出現特定定義的關鍵字時,該定義將獲得最高分數並被選為預測的PII類。
Octopii還使用正則表達式檢查了敏感的PII材料,例如電子郵件,電話號碼和普通政府ID唯一標識符。它還可以使用自然語言處理提取地理位置數據,例如地址和國家。
輸出包括以下內容:
file_path :找到包含pii的文件的位置pii_class :PII的類型此文件包含country_of_origin :此pii起源於哪裡。identifiers :可用於針對PII中提到的個體的唯一標識符,代碼或數字。emails和phone_numbers :聯繫文件中的信息。addresses :PII中的任何形式的地理位置數據。這可以用來對個人的位置進行三角測量。 單擊此處以了解如何參考章魚。
...還有無數的
該工具僅用於研究和教育目的。紅色實驗室和該項目的其他貢獻者不承擔任何惡意UP的責任
麻省理工學院許可證
版權所有©2023 Rend Labs Private Limited。
由Owais Shaikh


