Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopii는 광학 문자 인식 (OCR), 정규 표현 목록 및 자연 언어 처리 (NLP)를 사용하여 정부 ID, 주소, 이미지, PDF 및 문서에 대한 공개 위치를 검색하는 개인 식별 정보 (PII) 스캐너입니다.
PII 누출은 종종 사이버 보안 공간에서 간과됩니다. Redd Labs에서는 조직과 서비스가 필요로하는 사이버 보안 솔루션을 제시 할 수있는 다양한 혁신적인 방법을 찾고 있습니다. 우리는 서버가 잘못 구성된 상당수의 조직을 만났습니다. 이로 인해 Employe와 고객 PII가 항상 누출되어 악의적 인 당사자에게 기원, ID 번호, 연락처 정보 및 위치에 대한 민감한 정보를 제공합니다.
그렇기 때문에 우리는 인터넷에서 유출 된 PII 및 민감한 문서의 발견 및 추출을 자동화하는 것이 얼마나 쉬운 지 입증하고 감지하는 도구 인 Octopii를 만들어냅니다.
pip install -r requirements.txt 통해 모든 종속성을 설치하십시오.sudo apt install tesseract-ocr -y 를 통해 Ubuntu 또는 sudo pacman -Syu tesseract 아치 Linux의 Tesseract 도우미를 로컬로 설치하십시오.python -m spacy download en_core_web_sm 통해 스파크 언어 정의를 로컬로 설치하십시오.위를 설치하면 모두 설정됩니다.
Octopii를 실행하려면 입력하십시오
python3 octopii.py <location to scan>
여기서 <location to scan> 파일 또는 디렉토리입니다.
Octopii는 현재 파일 시스템 경로, S3 URL 및 Apache Open Directory 목록을 통해 로컬 스캔을 지원합니다. 또한 개별 이미지 URL 또는 파일을 인수로 제공 할 수도 있습니다.
Octopii를 테스트 할 수있는 샘플 pii가 포함 된 dummy-pii/ 폴더를 제공했습니다. 인수로 전달하면 다음 출력을 얻을 수 있습니다.
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
output.txt 라는 파일이 도구에서 출력을 포함하여 작성되었습니다. 이 파일은 실시간으로 순차적으로 추가됩니다.
Octopii는 광학 문자 인식 (OCR)을 위해 TesserAct를 사용하고 NLP (Natural Language Processing)를 위해 NLTK를 사용하여 개인 식별 정보의 문자열을 감지합니다. 이것은 다음 단계를 통해 수행됩니다.
이미지 (JPG 및 PNG) 및 문서 (PDF, DOC, TXT 등)에 대한 Octopii 스캔. 3 가지 소스를 지원합니다.
이미지는 Python Imaging Library (PIL)를 통해 감지되며 OpenCV로 열려 있습니다. PDF는 이미지 목록으로 변환되며 OCR을 통해 스캔됩니다. 텍스트 기반 파일 유형은 문자열로 읽히고 OCR없이 스캔됩니다.
"Haar Cascade"라고 알려진 이진 분류 이미지 탐지 기술은 이미지 내면을 감지하는 데 사용됩니다. OpenCV를 사용하기위한 캐스케이드 데이터가 포함 된이 리포지트에는 미리 훈련 된 캐스케이드 모델이 제공됩니다. 동일한 PII 이미지 내에서 여러면을 감지 할 수 있으며 감지 된면 수가 다시 나타납니다.
그런 다음 다음 이미지 변환 단계와 함께 텍스트 추출을 위해 이미지가 "Clened"됩니다.
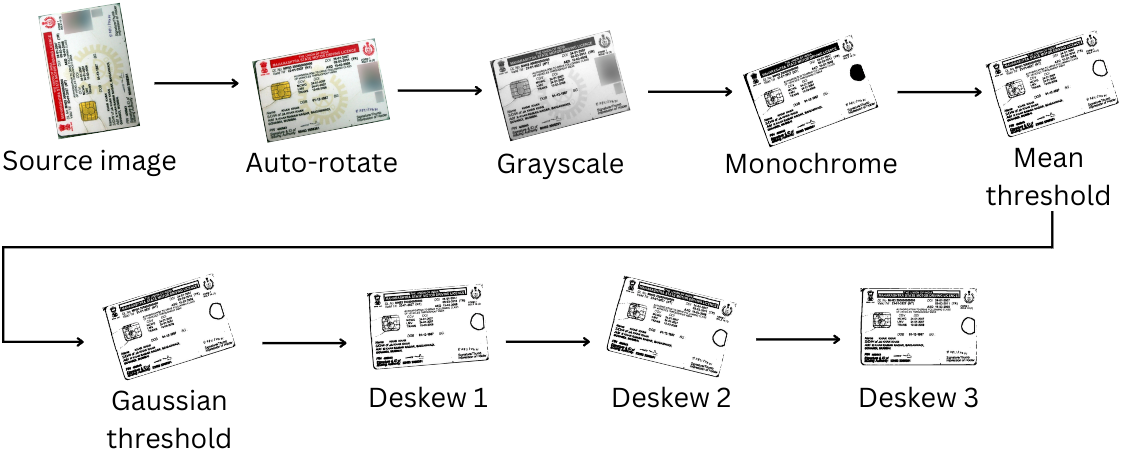
이 단계는 이미지 데이터를 제거하기 때문에 (사진의 색상 포함),이 이미지 청소 과정은 시도 얼굴 감지 후에 발생합니다.
TesserAct는 이미지/파일에서 모든 텍스트 문자열을 가져 오는 데 사용됩니다. 그런 다음 Newline 캐릭터 ( ' n')와 공백 ( '')으로 나뉘어 문자열 목록으로 토큰 화됩니다. null 문자열 및 단일 문자와 같은 garbled 텍스트는이 목록에서 폐기되어 잠재적 인 단어의 '이해하기 쉬운'목록이 생깁니다.
이 단어 목록은 유사한 체커 함수로 공급됩니다. 이 기능은 Gestalt 패턴 매칭을 사용하여 PII 문서에서 추출한 각 단어를 definitions.json 에있는 키워드 목록과 비교합니다. 이 점검은 청소 당 한 번 발생합니다. 키워드의 단어가 계산되고 신뢰 점수를 도출하는 데 사용됩니다. 이러한 스캔에서 특정 정의의 키워드가 반복되는 경우 해당 정의는 가장 높은 점수를 얻고 예측 된 PII 클래스로 선택됩니다.
Octopii는 또한 정규 표현식을 사용하여 이메일, 전화 번호 및 공통 정부 ID 고유 식별자와 같은 민감한 PII 시체를 확인합니다. 또한 자연어 처리를 사용하는 주소 및 국가와 같은 지리적 위치 데이터를 추출 할 수도 있습니다.
출력은 다음으로 구성됩니다.
file_path : pii가 포함 된 파일을 찾을 수있는 곳pii_class :이 파일에 포함 된 pii 유형country_of_origin :이 PII가 시작된 곳.identifiers : PII에 언급 된 개인을 타겟팅하는 데 사용될 수있는 고유 식별자, 코드 또는 숫자.emails 및 phone_numbers : 파일의 연락처 정보.addresses : PII의 모든 형태의 지리적 위치 데이터. 이것은 개인의 위치를 삼각 측량하는 데 사용될 수 있습니다. Octopii에 대한 관점에 대해 읽으려면 여기를 클릭하십시오.
... 그리고 수많은 다른 사람들
이 도구는 연구 및 교육 목적을위한 것입니다. 이 프로젝트에 대한 Red Labs 및 기타 기여자는 악의적 인 UPS에 대한 책임이 없습니다.
MIT 라이센스
Copyright © 2023 Rend Labs Private Limited.
Owais Shaikh


