Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopii是一种个人识别信息(PII)扫描仪,使用光学角色识别(OCR),正则表达式列表和自然语言处理(NLP)来搜索政府ID的公共面向公共位置,地址,图像,PDFS和文档中的电子邮件,电子邮件。
在网络安全空间中,PII泄漏经常被忽略。在Redd Labs,我们始终寻找不同和创新的方法来提出组织和服务所需的网络安全解决方案。我们遇到了大量的组织,这些组织的配置不正确。这导致雇员和客户PII一直泄漏,提供有关其起源,ID号,联系信息及其位置的恶意派对敏感信息。
这就是为什么我们被创建的章鱼是一种工具,该工具可以演示和检测到自动化Internet上泄漏的PII和敏感文档的发现和提取的容易。
pip install -r requirements.txt安装所有依赖项。sudo pacman -Syu tesseract上sudo apt install tesseract-ocr -y 。python -m spacy download en_core_web_sm在本地安装Spacy语言定义。安装上述内容后,您将全部设置。
要运行章鱼,类型
python3 octopii.py <location to scan>
<location to scan>是文件或目录。
Octopii目前通过文件系统路径,S3 URL和Apache Open Directory列表支持本地扫描。您还可以作为参数提供单个图像URL或文件。
我们为您提供了一个包含样品PII的dummy-pii/文件夹,供您测试章鱼。作为参数传递,您将获得以下输出
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
创建了一个名为output.txt的文件,其中包含工具的输出。该文件是实时附加的。
Octopii使用Tesseract进行光学特征识别(OCR)和NLTK进行自然语言处理(NLP)来检测个人可识别信息的字符串。这是通过以下步骤完成的:
章鱼扫描图像(JPG和PNG)和文档(PDF,DOC,TXT等)。它支持3个来源:
图像是通过Python Imaging库(PIL)检测到的,并使用OpenCV打开。 PDF被转换为图像列表,并通过OCR进行扫描。基于文本的文件类型被读取为字符串,并在没有OCR的情况下进行扫描。
二进制分类图像检测技术(称为“ Haar Cascade”)用于检测图像中的面孔。此存储库中提供了预训练的级联模型,其中包含用于使用OpenCV的级联数据。可以在同一PII图像中检测到多个面孔,并重新播放检测到的面数。
然后将图像“固定”以进行文本提取,并通过以下图像转换步骤:
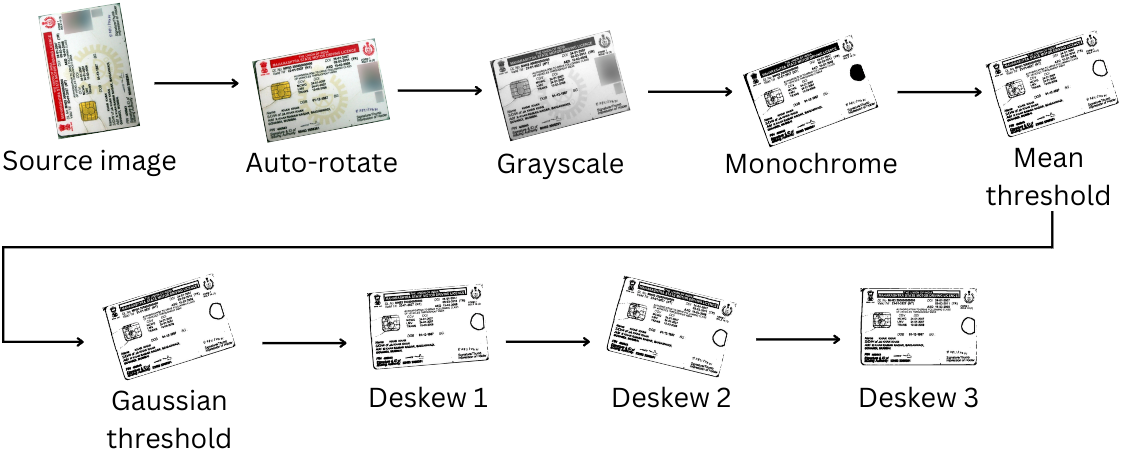
由于这些步骤剥离了图像数据(包括照片中的颜色),因此此图像清洁过程在尝试检测后发生。
Tesseract用于从图像/文件中获取所有文本字符串。然后将其归为字符串列表,由newline字符( n')和Space('')划分。乱七八糟的文本(例如null字符串和单个字符)从此列表中丢弃,从而导致潜在单词的“可理解”列表。
然后将此单词列表馈送到类似的检查器功能中。此功能使用格式塔模式匹配来比较从PII文档中提取的每个单词与definitions.json中的关键字列表。每次清洁一次一次检查一次。计数关键字的单词的次数,用于得出置信度得分。当在这些扫描中重复出现特定定义的关键字时,该定义将获得最高分数并被选为预测的PII类。
Octopii还使用正则表达式检查了敏感的PII材料,例如电子邮件,电话号码和普通政府ID唯一标识符。它还可以使用自然语言处理提取地理位置数据,例如地址和国家。
输出包括以下内容:
file_path :找到包含pii的文件的位置pii_class :PII的类型此文件包含country_of_origin :此pii起源于哪里。identifiers :可用于针对PII中提到的个体的唯一标识符,代码或数字。emails和phone_numbers :联系文件中的信息。addresses :PII中的任何形式的地理位置数据。这可以用来对个人的位置进行三角测量。 单击此处以了解如何参考章鱼。
...还有无数的
该工具仅用于研究和教育目的。红色实验室和该项目的其他贡献者不承担任何恶意UP的责任
麻省理工学院许可证
版权所有©2023 Rend Labs Private Limited。
由Owais Shaikh


