Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopii هو ماسح ضوئي مخصص للمعرفة (PII) يستخدم التعرف على الأحرف البصرية (OCR) ، وقوائم التعبير العادية ومعالجة اللغة الطبيعية (NLP) للبحث عن مواقع تواجه الجمهور لمعرف الحكومة ، والعناوين ، ورسائل البريد الإلكتروني في الصور ، و PDFs والمستندات.
غالبًا ما يتم التغاضي عن تسرب PII في مساحة الأمن السيبراني. في Redd Labs ، نبحث دائمًا عن طرق مختلفة ومبتكرة للتوصل إلى حلول للأمن السيبراني تحتاج المنظمات والخدمات. لقد واجهنا عددًا كبيرًا من المؤسسات التي تم تكوين خوادمها بشكل غير صحيح. هذا يتسبب في تسرب العمل والعميل PII طوال الوقت ، مما يمنح الأطراف الخبيثة معلومات حساسة حول أصولها وأرقام الهوية ومعلومات الاتصال وموقعها.
هذا هو السبب في أننا قد أنشأنا Octopii ، وهي أداة لإظهار واكتشاف مدى سهولة أتمتة اكتشاف واستخراج PII المتسرب والوثائق الحساسة على الإنترنت.
pip install -r requirements.txt .sudo apt install tesseract-ocr -y على Ubuntu أو sudo pacman -Syu tesseract على قوس Linux.python -m spacy download en_core_web_sm .بمجرد تثبيت ما ورد أعلاه ، فأنت جميعًا تم تعيينك.
لتشغيل Octopii ، اكتب
python3 octopii.py <location to scan>
حيث يكون <location to scan> ملفًا أو دليلًا.
يدعم Octopii حاليًا المسح المحلي عبر مسار نظام الملفات وعنوان S3 وقوائم دليل Apache Open Directory. يمكنك أيضًا توفير عناوين URL الفردية أو الملفات كوسيطة.
لقد قدمنا مجلدًا dummy-pii/ يحتوي على عينة PII لك لاختبار Octopii مع. تمريرها كوسيطة وستحصل على الإخراج التالي
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
يتم إنشاء ملف يسمى output.txt ، يحتوي على الإخراج من الأداة. يتم إلحاق هذا الملف بالتتابع في الوقت الفعلي.
يستخدم Octopii tesseract للتعرف على الأحرف البصرية (OCR) و NLTK لمعالجة اللغة الطبيعية (NLP) للكشف عن سلاسل من المعلومات الشخصية. يتم ذلك عبر الخطوات التالية:
يقوم Octopii بمسح الصور (JPG و PNG) والمستندات (PDF ، DOC ، TXT إلخ). يدعم 3 مصادر:
يتم اكتشاف الصور عبر مكتبة Python Imaging (PIL) وهي مفتوحة مع OpenCV. يتم تحويل PDFs إلى قائمة بالصور ويتم مسحها ضوئيًا عبر OCR. تتم قراءة أنواع الملفات المستندة إلى النصوص في سلاسل ويتم مسحها ضوئيًا بدون OCR.
يتم استخدام تقنية الكشف عن صور التصنيف الثنائي - المعروفة باسم "Haar Cascade" - للكشف عن الوجوه داخل الصور. يتم توفير نموذج سلسلة تدريب مسبقًا في هذا الريبو ، والذي يحتوي على بيانات Cascade لـ OpenCV لاستخدامها. يمكن اكتشاف وجوه متعددة داخل نفس صورة PII ، ويتم ترميم عدد الوجوه المكتشفة.
ثم يتم "التخلص من الصور" لاستخراج النص مع خطوات تحويل الصورة التالية:
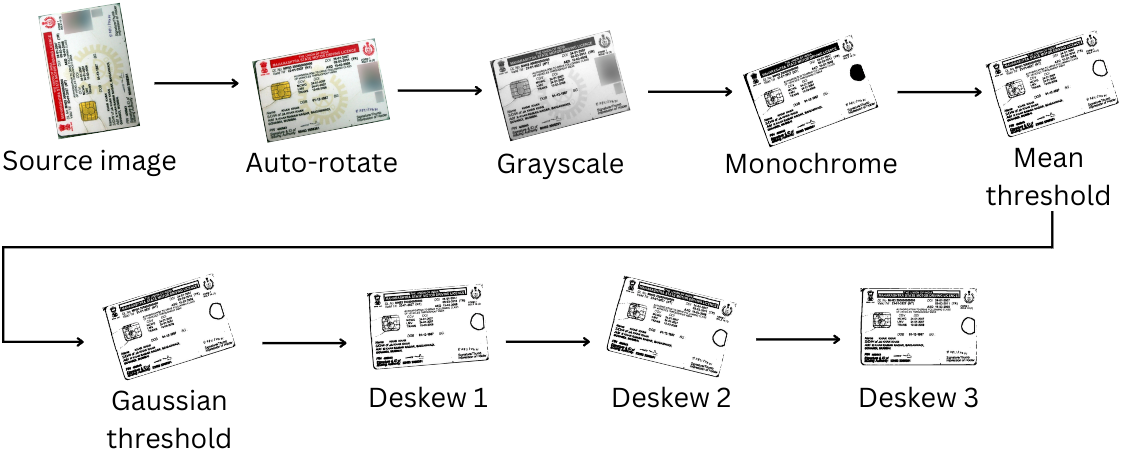
نظرًا لأن هذه الخطوات تقوم بتجريد بيانات الصورة (بما في ذلك الألوان في الصور الفوتوغرافية) ، تحدث عملية تنظيف الصور هذه بعد محاولة اكتشاف الوجه.
يستخدم Tesseract للاستيلاء على جميع سلاسل النص من صورة/ملف. ثم يتم رمزها في قائمة الأوتار ، مقسمة بواسطة حرف NewLine (' n') والمساحات (''). يتم التخلص من النص المشوه ، مثل الأوتار null والأحرف الفردية من هذه القائمة ، مما يؤدي إلى قائمة "واضحة" من الكلمات المحتملة.
ثم يتم تغذية قائمة الكلمات هذه في وظيفة مدقق مماثلة. تستخدم هذه الوظيفة مطابقة نمط Gestalt لمقارنة كل كلمة مستخرجة من مستند PII مع قائمة بالكلمات الرئيسية ، الموجودة في definitions.json . يحدث هذا الشيك مرة واحدة لكل تنظيف. يتم حساب عدد المرات التي يتم فيها حساب الكلمة من الكلمات الرئيسية ويستخدم هذا لاستخلاص درجة الثقة. عندما تظهر الكلمات الرئيسية لتعريف معين متكررة في هذه عمليات المسح ، يحصل هذا التعريف على أعلى درجة ويتم اختياره كفئة PII المتوقعة.
يتحقق Octopii أيضًا من الحصول على بديلات PII الحساسة مثل رسائل البريد الإلكتروني وأرقام الهواتف والمعرفات الحكومية الشائعة التي تستخدم التعبيرات العادية. يمكنه أيضًا استخراج بيانات تحديد الموقع الجغرافي مثل العناوين والبلدان التي تستخدم معالجة اللغة الطبيعية.
يتكون الإخراج من ما يلي:
file_path : حيث يمكن العثور على الملف الذي يحتوي على PIIpii_class : نوع pii يحتوي هذا الملفcountry_of_origin : حيث ينشأ هذا PII من.identifiers : معرفات فريدة أو رموز أو أرقام يمكن استخدامها لاستهداف الفرد المذكور في PII.emails و phone_numbers : معلومات الاتصال في الملف.addresses : أي شكل من أشكال بيانات تحديد الموقع الجغرافي في PII. يمكن استخدام هذا لتثليث موقع الفرد. انقر هنا لقراءة كيف يمكنك أن تتوقف إلى Octopii.
... وعدد لا يحصى من الآخرين
هذه الأداة مخصصة لأغراض البحث والتعليمية فقط. لا تتحمل المختبرات الحمراء وغيرهم من المساهمين في هذا المشروع أي مسؤوليات عن UPS الضارة
رخصة معهد ماساتشوستس للتكنولوجيا
حقوق الطبع والنشر © 2023 Rend Labs Private Limited.
بقلم أويس شيخ


