Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopii เป็นสแกนเนอร์ข้อมูลส่วนบุคคล (PII) ที่ใช้การจดจำอักขระแบบออพติคอล (OCR) รายการนิพจน์ทั่วไปและการประมวลผลภาษาธรรมชาติ (NLP) เพื่อค้นหาสถานที่ตั้งของสาธารณะสำหรับ ID ของรัฐบาลที่อยู่อีเมลในรูปภาพ PDFS และเอกสาร
การรั่วไหลของ PII มักถูกมองข้ามในพื้นที่รักษาความปลอดภัยทางไซเบอร์ ที่ Redd Labs เรามักจะมองหาวิธีที่แตกต่างและเป็นนวัตกรรมในการหาโซลูชั่นความปลอดภัยทางไซเบอร์ที่องค์กรและบริการต้องการ เรา 'เราได้พบกับองค์กรจำนวนมากที่มีเซิร์ฟเวอร์ของพวกเขากำหนดค่าไม่ถูกต้อง สิ่งนี้ทำให้พนักงานและลูกค้า PII รั่วไหลตลอดเวลาให้ข้อมูลที่ละเอียดอ่อนเกี่ยวกับต้นกำเนิดหมายเลขรหัสข้อมูลการติดต่อและที่ตั้งของพวกเขา
นี่คือเหตุผลที่เราสร้าง Octopii ซึ่งเป็นเครื่องมือในการสาธิตและตรวจสอบว่าการค้นพบและการสกัด PII ที่รั่วไหลออกมาโดยอัตโนมัติและเอกสารที่ละเอียดอ่อนบนอินเทอร์เน็ตเป็นเรื่องง่ายเพียงใด
pip install -r requirements.txtsudo apt install tesseract-ocr -y บน ubuntu หรือ sudo pacman -Syu tesseract บน arch linuxpython -m spacy download en_core_web_smเมื่อคุณติดตั้งด้านบนแล้วคุณก็พร้อมแล้ว
ในการเรียกใช้ Octopii พิมพ์
python3 octopii.py <location to scan>
โดยที่ <location to scan> เป็นไฟล์หรือไดเรกทอรี
ปัจจุบัน Octopii รองรับการสแกนท้องถิ่นผ่านเส้นทางระบบไฟล์, URL S3 และรายชื่อ Apache Open Directory นอกจากนี้คุณยังสามารถให้ URL หรือไฟล์ภาพบุคคลเป็นอาร์กิวเมนต์
เราได้จัดทำ dummy-pii/ โฟลเดอร์ที่มีตัวอย่าง PII ให้คุณทดสอบ Octopii ด้วย ส่งผ่านเป็นอาร์กิวเมนต์และคุณจะได้รับผลลัพธ์ต่อไปนี้
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
ไฟล์ชื่อ output.txt ถูกสร้างขึ้นซึ่งมีเอาต์พุตจากเครื่องมือ ไฟล์นี้ต่อท้ายเป็นลำดับแบบเรียลไทม์
Octopii ใช้ Tesseract สำหรับการจดจำอักขระแบบออพติคอล (OCR) และ NLTK สำหรับการประมวลผลภาษาธรรมชาติ (NLP) เพื่อตรวจจับสตริงของข้อมูลส่วนบุคคลที่สามารถระบุตัวตนได้ สิ่งนี้ทำได้ผ่านขั้นตอนต่อไปนี้:
Octopii สแกนสำหรับรูปภาพ (JPG และ PNG) และเอกสาร (PDF, DOC, TXT ฯลฯ ) รองรับ 3 แหล่ง:
ตรวจพบรูปภาพผ่าน Python Imaging Library (PIL) และเปิดด้วย OpenCV PDF จะถูกแปลงเป็นรายการรูปภาพและสแกนผ่าน OCR ประเภทไฟล์ที่ใช้ข้อความจะถูกอ่านเป็นสตริงและสแกนโดยไม่มี OCR
เทคนิคการตรวจจับภาพการจำแนกประเภทไบนารี - เรียกว่า "Haar cascade" - ใช้เพื่อตรวจจับใบหน้าภายในภาพ รูปแบบคาสเคดที่ผ่านการฝึกอบรมมาก่อนมีการจัดหาใน repo นี้ซึ่งมีข้อมูลน้ำตกเพื่อให้ OpenCV ใช้ สามารถตรวจพบใบหน้าได้หลายใบหน้าภายในภาพ PII เดียวกันและจำนวนใบหน้าที่ตรวจพบจะถูกสร้างใหม่
รูปภาพจะถูก "clened" สำหรับการแยกข้อความด้วยขั้นตอนการแปลงภาพต่อไปนี้:
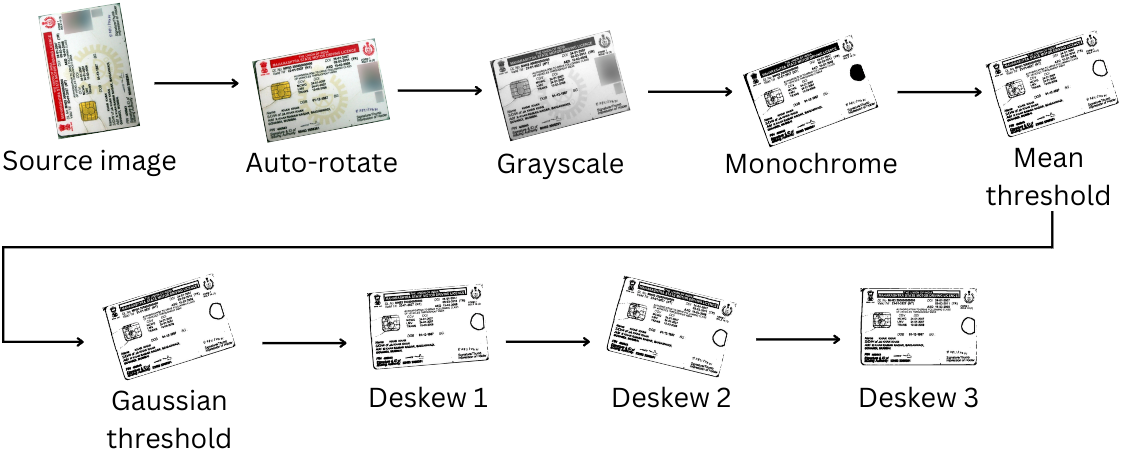
เนื่องจากขั้นตอนเหล่านี้แยกข้อมูลภาพออกไป (รวมถึงสีในภาพถ่าย) กระบวนการทำความสะอาดภาพนี้เกิดขึ้นหลังจากการตรวจจับหน้าพยายาม
Tesseract ใช้เพื่อคว้าสตริงข้อความทั้งหมดจากรูปภาพ/ไฟล์ จากนั้นจะถูกส่งไปยังรายการสตริงแยกด้วยอักขระใหม่ (' n') และช่องว่าง ('') ข้อความที่อ่านไม่ออกเช่นสตริง null และอักขระเดี่ยวจะถูกทิ้งจากรายการนี้ส่งผลให้รายการคำที่มีศักยภาพ 'เข้าใจได้'
รายการคำนี้จะถูกป้อนเข้าสู่ฟังก์ชั่น Checker ที่คล้ายกัน ฟังก์ชั่นนี้ใช้การจับคู่รูปแบบ Gestalt เพื่อเปรียบเทียบแต่ละคำที่แยกออกจากเอกสาร PII กับรายการคำหลักแสดงใน definitions.json json การตรวจสอบนี้เกิดขึ้นครั้งเดียวต่อการทำความสะอาด จำนวนครั้งที่คำจากคำหลักถูกนับและใช้เพื่อให้ได้คะแนนความมั่นใจ เมื่อคำหลักของคำจำกัดความเฉพาะปรากฏซ้ำในการสแกนเหล่านี้คำจำกัดความนั้นจะได้คะแนนสูงสุดและถูกเลือกเป็นคลาส PII ที่คาดการณ์ไว้
Octopii ยังตรวจสอบสาร PII ที่ละเอียดอ่อนเช่นอีเมลหมายเลขโทรศัพท์และ ID ของรัฐบาลทั่วไปตัวระบุที่ไม่ซ้ำกันโดยใช้การแสดงออกปกติ นอกจากนี้ยังสามารถแยกข้อมูลตำแหน่งทางภูมิศาสตร์เช่นที่อยู่และประเทศโดยใช้การประมวลผลภาษาธรรมชาติ
ผลลัพธ์ประกอบด้วยสิ่งต่อไปนี้:
file_path : ไฟล์ที่มี PII สามารถพบได้pii_class : ประเภทของ pii ไฟล์นี้มีcountry_of_origin : ที่ PII นี้มีต้นกำเนิดมาจากidentifiers : ตัวระบุรหัสหรือตัวเลขที่ไม่ซ้ำกันซึ่งอาจใช้ในการกำหนดเป้าหมายบุคคลที่กล่าวถึงใน PIIemails และ phone_numbers : ข้อมูลการติดต่อในไฟล์addresses : รูปแบบของข้อมูลตำแหน่งทางภูมิศาสตร์ใด ๆ ใน PII สิ่งนี้อาจใช้ในการสามเหลี่ยมที่ตั้งของแต่ละบุคคล คลิกที่นี่เพื่ออ่านเกี่ยวกับวิธีที่คุณสามารถจัดเรียงไปยัง Octopii
... และคนอื่น ๆ นับไม่ถ้วน
เครื่องมือนี้มีไว้สำหรับการวิจัยและการศึกษาเท่านั้น Red Labs และผู้มีส่วนร่วมอื่น ๆ ในโครงการนี้ไม่มีความรับผิดชอบสำหรับ UPS ที่เป็นอันตราย
ใบอนุญาต MIT
ลิขสิทธิ์© 2023 Rend Labs Private Limited
โดย Owais Shaikh


