Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
O Octopii é um scanner de informações pessoalmente identificáveis (PII) que usa o reconhecimento óptico de caracteres (OCR), listas de expressão regular e processamento de linguagem natural (PNL) para pesquisar localizações públicas para identificação do governo, endereços, e-mails em imagens, PDFs e documentos.
Os vazamentos de PII são frequentemente negligenciados no espaço de segurança cibernética. Na Redd Labs, sempre procuramos maneiras diferentes e inovadoras de apresentar soluções de segurança cibernética que as organizações e serviços precisam. Nós encontramos um número substancial de organizações que têm seus servidores configurados incorretamente. Isso faz com que o PII do Empregar e do Cliente vaze o tempo todo, dando a festas maliciosas informações confidenciais sobre suas origens, números de identificação, informações de contato e sua localização.
É por isso que somos criados Octopii, uma ferramenta para demonstrar e detectar como é fácil automatizar a descoberta e extração de PII vazado e documentos sensíveis na Internet.
pip install -r requirements.txt .sudo apt install tesseract-ocr -y no ubuntu ou sudo pacman -Syu tesseract no arch linux.python -m spacy download en_core_web_sm .Depois de instalar o acima, você está pronto.
Para executar o Octopii, digite
python3 octopii.py <location to scan>
Onde <location to scan> é um arquivo ou um diretório.
Atualmente, a Octopii suporta a digitalização local por meio do caminho do sistema de arquivos, URLs S3 e listagens de diretórios abertos do Apache. Você também pode fornecer URLs ou arquivos de imagem individuais como argumento.
Fornecemos uma pasta dummy-pii/ contendo PII da amostra para você testar o Octopii. Passe como um argumento e você obterá a seguinte saída
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
Um arquivo chamado output.txt é criado, contendo saída da ferramenta. Este arquivo é anexado a sequencialmente em tempo real.
O Octopii usa o TESSERACT para reconhecimento óptico de caracteres (OCR) e NLTK para processamento de linguagem natural (PNL) para detectar seqüências de informações de informações identificáveis pessoais. Isso é feito através das seguintes etapas:
OCCOPII Scanns para imagens (JPG e PNG) e documentos (PDF, Doc, TXT etc). Ele suporta 3 fontes:
As imagens são detectadas via Python Imaging Library (PIL) e estão abertas com o OpenCV. Os PDFs são convertidos em uma lista de imagens e são digitalizados via OCR. Os tipos de arquivos baseados em texto são lidos em strings e são digitalizados sem OCR.
Uma técnica de detecção de imagem de classificação binária - conhecida como "cascata de haar" - é usada para detectar faces dentro das imagens. Um modelo em cascata pré-treinado é fornecido neste repositório, que contém dados em cascata para o OpenCV usar. Várias faces podem ser detectadas dentro da mesma imagem PII, e o número de faces detectadas é reaplorado.
As imagens são então "revestidas" para extração de texto com as seguintes etapas de transformação da imagem:
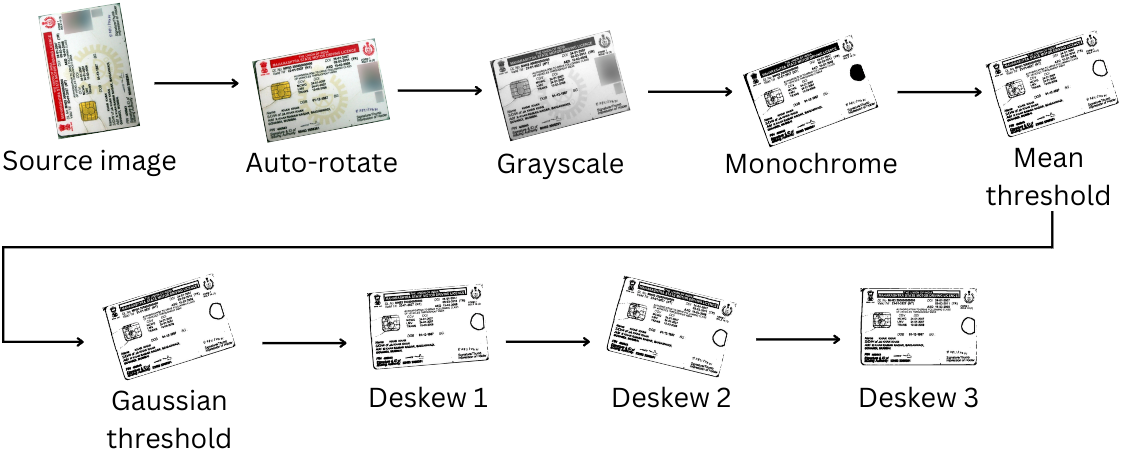
Como essas etapas retiram os dados da imagem (incluindo cores nas fotografias), esse processo de limpeza de imagens ocorre após a tentativa de detecção de rosto.
O TESSERACT é usado para pegar todas as seqüências de texto de uma imagem/arquivo. É então tokenizado em uma lista de strings, dividida por Newline Character (' n') e espaços (''). O texto iluminado, como cordas null e caracteres únicos, é descartada desta lista, resultando em uma lista "inteligível" de palavras em potencial.
Esta lista de palavras é então alimentada em uma função de verificador semelhante. Esta função usa a correspondência do padrão da gestalt para comparar cada palavra extraída do documento PII com uma lista de palavras -chave, presente em definitions.json . Esta verificação acontece uma vez por limpeza. O número de vezes que uma palavra das palavras -chave é contada e isso é usado para derivar uma pontuação de confiança. Quando as palavras -chave de uma definição específica aparecem repetidas nessas varreduras, essa definição obtém a pontuação mais alta e é escolhida como a classe PII prevista.
O Octopii também verifica substidades PII sensíveis, como e -mails, números de telefone e identificadores exclusivos de ID do governo comuns usando expressões regulares. Também pode extrair dados de geolocalização, como endereços e países, usando processamento de linguagem natural.
A saída consiste no seguinte:
file_path : onde o arquivo que contém PII pode ser encontradopii_class : o tipo de pii que este arquivo contémcountry_of_origin : de onde este pii se origina.identifiers : identificadores, códigos ou números exclusivos que podem ser usados para direcionar o indivíduo mencionado no PII.emails e phone_numbers : informações de contato no arquivo.addresses : qualquer forma de dados de geolocalização no PII. Isso pode ser usado para triangular a localização de um indivíduo. Clique aqui para ler sobre como você pode disputar o Octopii.
... e inúmeros outros
Esta ferramenta é destinada apenas a fins de pesquisa e educação. Red Labs e outros colaboradores deste projeto não assumem responsabilidades por altos maliciosos
MIT Licença
Copyright © 2023 Rend Labs Private Limited.
Por Owais Shaikh


