Octopii
v2.2
⠀⠀⠀⠀⠀⠀⠀⣤⣤⣄⣀⡀⠀⠀⠀⢀⣠⣤⣤⣄⡀⠀⠀⠀⢀⣀⣠⣤⣤⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠸⣿⣿⡿⠿⢿⣷⡄⢠⣿⣿⣿⣿⣿⣿⡄⢀⣾⡿⠿⢿⣿⣿⠇⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠈⠉⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠉⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⣠⣤⡀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⠀⠀⠀⠀⠀⠀⢀⣤⣄⠀⠀⠀
⠸⣿⣿⣿⣿⣿⣿⣿⣿⣦⠀⢸⣿⡇⢸⣿⣿⣿⣿⣿⣿⡇⢸⣿⡇⠀⣴⣿⣿⣿⣿⣿⣿⣿⣿⠇⠀⠀
⠀⠉⠉⠁⠀⠀⠀⠀⣿⣿⠀⢸⣿⡇⠀⠉⣿⣿⣿⣿⠉⠀⢸⣿⡇⠀⣿⣿⠀⠀⠀⠀⠈⠉⠉⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣀⣈⣻⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣟⣁⣀⣿⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠘⠿⠿⠿⠿⠿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠿⠿⠿⠃⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢀⣤⣤⣤⣤⣤⣤⣴⣿⣿⣿⡇⢸⣿⡿⣿⣦⣤⣤⣤⣤⣤⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⢸⣿⠋⠉⠉⠉⠉⠉⠉⢸⣿⡇⢸⣿⡇⠈⠉⠉⠉⠉⠉⠙⣿⣧⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⢰⣿⣿⣦⠀⢰⣿⣿⣦⠀⢸⣿⡇⢸⣿⡇⠀⣰⣿⣿⡆⠀⣴⣿⣿⡆⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠈⠻⠿⠋⠀⠘⣿⣿⠃⠀⢸⣿⡇⢸⣿⡇⠀⠘⣿⣿⠃⠀⠙⠿⠟⠁⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢻⣿⣦⣤⣼⣿⠃⠘⣿⣧⣄⣤⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠛⠛⠛⠁⠀⠀⠈⠛⠛⠛⠋⠀⠀⠀
⠀⠀⠀⠀⠀⠀ ⠀O C T O P I I⠀⠀⠀⠀
Copyright © 2023 RedHunt Labs Private Limited
Octopiiは、光学文字認識(OCR)、正規表現リスト、および自然言語処理(NLP)を使用して、政府ID、アドレス、画像のメール、PDF、ドキュメントの公開場所を検索する個人的に識別可能な情報(PII)スキャナーです。
PIIリークは、サイバーセキュリティ分野で見落とされがちです。 Redd Labsでは、組織やサービスに必要なサイバーセキュリティソリューションを考案するためのさまざまな革新的な方法を常に探しています。私たちは、サーバーを誤って構成しているかなりの数の組織に遭遇しました。これにより、Employeと顧客のPIIは常に漏洩し、悪意のあるパーティーに起源、ID番号、連絡先情報、および場所に関する機密情報が与えられます。
これが、インターネット上のリークされたPIIおよび敏感なドキュメントの発見と抽出を自動化することがどれほど簡単かを実証および検出するツールであるOctopiiを作成する理由です。
pip install -r requirements.txtを介してすべての依存関係をインストールします。sudo apt install tesseract-ocr -y on ubuntuまたはsudo pacman -Syu tesseract on arch linuxを介してTesseractヘルパーをローカルに取り付けます。python -m spacy download en_core_web_smを介してスペイシー言語の定義をローカルにインストールします。上記をインストールすると、すべて設定されます。
Octopiiを実行するには、タイプ
python3 octopii.py <location to scan>
ここで、 <location to scan>はファイルまたはディレクトリです。
Octopiiは現在、ファイルシステムパス、S3 URL、Apacheオープンディレクトリリストを介してローカルスキャンをサポートしています。個々の画像URLまたはファイルを引数として提供することもできます。
Octopiiをテストするために、サンプルPIIを含むdummy-pii/フォルダーを提供しました。引数として渡すと、次の出力が得られます
owais@artemis ~ $ python3 octopii.py dummy-pii/
Searching for PII in dummy-pii/dummy-drivers-license-nebraska-us.jpg
{
"file_path": "dummy-pii/dummy-drivers-license-nebraska-us.jpg",
"pii_class": "Nebraska Driver's License",
"country_of_origin": "United States",
"faces": 1,
"identifiers": [],
"emails": [],
"phone_numbers": [
"4000002170"
],
"addresses": [
"Nebraska"
]
}
Searching for PII in dummy-pii/dummy-PAN-India.jpg
{
"file_path": "dummy-pii/dummy-PAN-India.jpg",
"pii_class": "Permanent Account Number",
"country_of_origin": "India",
"faces": 0,
"identifiers": [],
"emails": [],
"phone_numbers": [],
"addresses": [
"INDIA"
]
}
...
output.txtという名前のファイルが作成され、ツールからの出力が含まれています。このファイルは、リアルタイムで順番に追加されます。
Octopiiは、Tesseractを使用して光学文字認識(OCR)とNLTKを使用して、自然言語処理(NLP)を使用して、個人の識別可能な情報の文字列を検出します。これは、次の手順で行われます。
Octopiiは、画像(JPGおよびPNG)とドキュメント(PDF、DOC、TXTなど)をスキャンします。 3つのソースをサポートしています:
画像はPython Imaging Library(PIL)を介して検出され、OpenCVで開いています。 PDFは画像のリストに変換され、OCRを介してスキャンされます。テキストベースのファイルタイプは文字列に読み取り、OCRなしでスキャンされます。
「ハールカスケード」として知られるバイナリ分類画像検出手法は、画像内の顔を検出するために使用されます。事前に訓練されたカスケードモデルがこのレポで提供されます。これには、使用するOpenCVのカスケードデータが含まれています。同じPII画像内で複数の面を検出でき、検出された面の数は再び装備されています。
次の画像は、次の画像変換の手順でテキスト抽出のために「クレイン」されます。
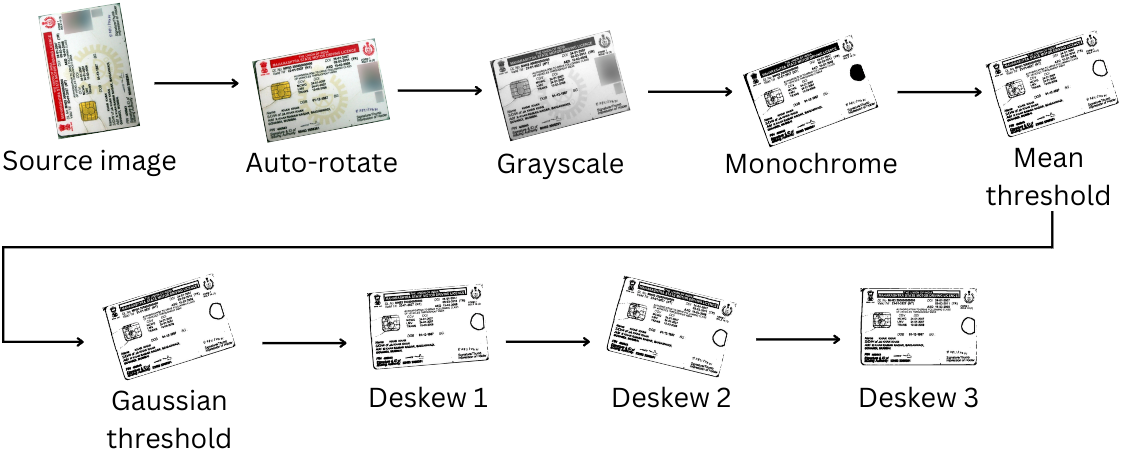
これらの手順は画像データ(写真の色を含む)を剥奪するため、この画像クリーニングプロセスは、顔の検出を試みた後に発生します。
Tesseractは、画像/ファイルからすべてのテキスト文字列をつかむために使用されます。次に、newline文字( ' n')とスペース( '')によって分割された文字列のリストにトークン化されます。 null文字列や単一文字などの文字化けのテキストは、このリストから破棄され、潜在的な単語の「わかりやすい」リストになります。
この単語のリストは、同様のチェッカー関数に供給されます。この関数は、Gestalt Pattern Matchingを使用して、PIIドキュメントから抽出された各単語を、 definitions.jsonに存在するキーワードのリストと比較します。このチェックは、クリーニングごとに1回発生します。キーワードからの単語の回数がカウントされ、これは信頼性スコアを導き出すために使用されます。特定の定義のキーワードがこれらのスキャンで繰り返されるように見えると、その定義は最高スコアを取得し、予測されたPIIクラスとして選択されます。
Octopiiは、電子メール、電話番号、正規表現を使用した一般的な政府IDユニークな識別子などの機密性の高いPIIの実装もチェックしています。また、自然言語処理を使用して、住所や国などの地理的データを抽出することもできます。
出力は次のもので構成されています。
file_path :PIIを含むファイルが見つかる場所pii_class :このファイルに含まれるPIIのタイプcountry_of_origin :このpiiはからです。identifiers :PIIで言及された個人をターゲットにするために使用できる一意の識別子、コード、または数値。emailsとphone_numbers :ファイル内の連絡先情報。addresses :PIIの任意の形式の地理的データ。これは、個人の位置を三角測量するために使用できます。 ここをクリックして、Octopiiにどのように競うことができるかについて読んでください。
...そして無数の他の人
このツールは、研究と教育目的のみを目的としています。このプロジェクトへのRed Labsやその他の貢献者は、悪意のあるUPSに対して責任を負いません
MITライセンス
Copyright©2023 Rend Labs Private Limited。
Owais Shaikhによって


