在本地CPU推理上運行Llama 2和其他開源LLM
清楚地解釋了使用Llama 2,C Transformers,GGML和Langchain在CPU上運行量化開源LLM應用程序的指南
逐步指南todataScience :https://towardsdatascience.com/running-llama-lama-2-on-cpu-inference-for-document-document-qa-3d636037a3d8
情境
- OpenAI的GPT4等第三方商業大型語言模型(LLM)提供商已通過簡單的API呼叫將LLM民主化。
- 但是,在某些情況下,由於數據隱私和居住規則等原因,團隊需要自我管理或私人模型部署。
- 開源LLM的擴散為我們打開了各種各樣的選擇,從而減少了我們對這些第三方提供商的依賴。
- 當我們在本地本地或云中託管開源LLMS時,專用的計算能力將成為關鍵問題。儘管GPU實例似乎是顯而易見的選擇,但成本很容易超越預算。
- 在此項目中,我們將發現如何在本地CPU推理中對文檔問答(Q&A)運行量化版本的開源版本。
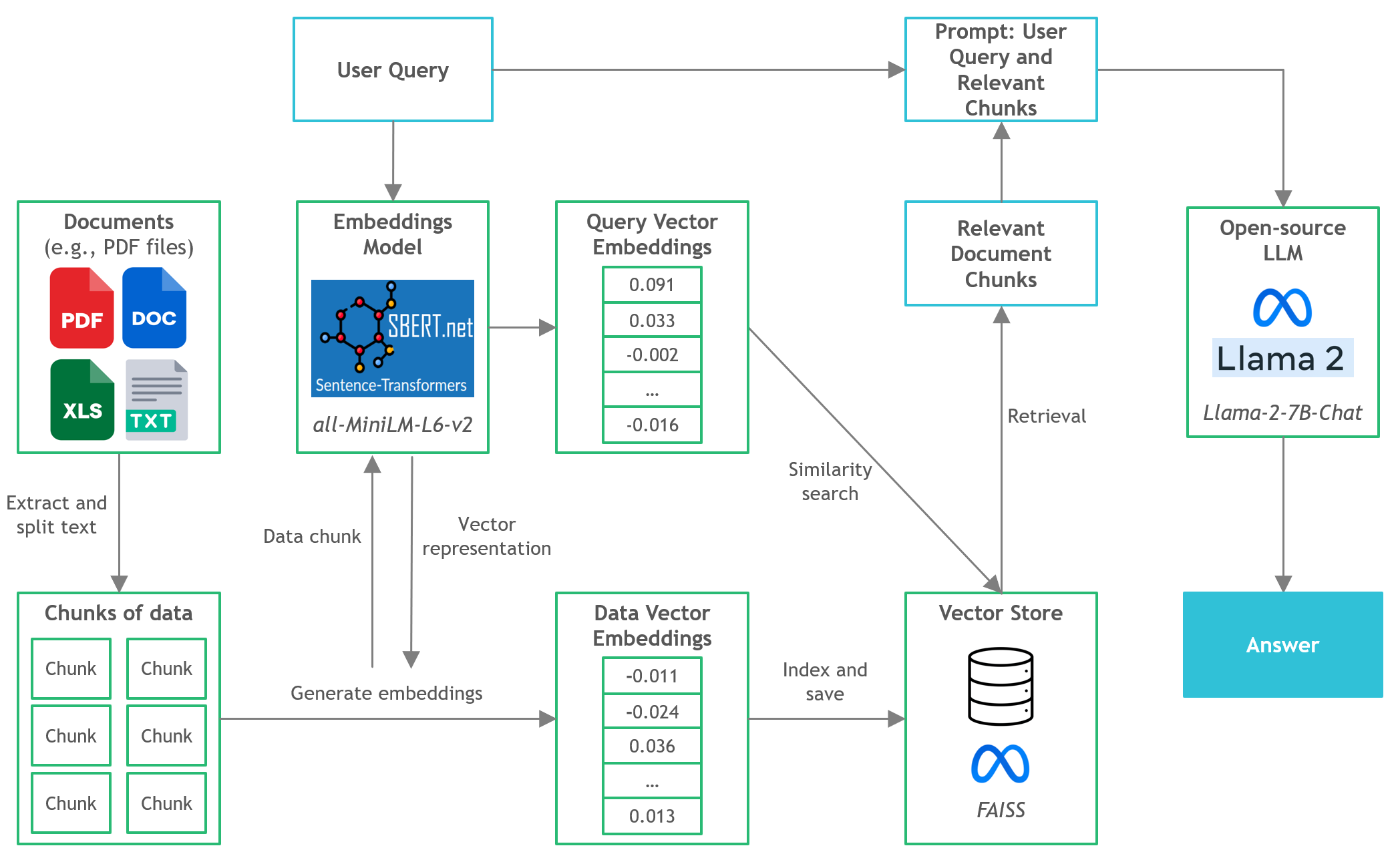
Quickstart
- 確保您從https://huggingface.co/thebloke/llama-2-7b-chat-ggml下載了GGML二進製文件,並將其放入
models/文件夾中 - 要開始將用戶查詢解析到應用程序中,請從項目目錄啟動終端並運行以下命令:
poetry run python main.py "<user query>" - 例如,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - 注意:如果您不使用詩歌,請省略預期
poetry run

工具
- Langchain :開發由語言模型提供支持的應用程序的框架
- C變形金剛:使用GGML庫在C/C ++中實現的變壓器模型的Python綁定
- FAISS :開源庫,用於有效的相似性搜索和密集矢量的聚類。
- 句子轉換器(All-Minilm-L6-V2) :開源預訓練的變壓器模型,用於將文本嵌入到384維密集的矢量空間中,以用於聚類或語義搜索等任務。
- Llama-2-7b-chat :開源微調的Llama 2模型,設計用於聊天對話。利用公開可用的說明數據集和超過100萬的人類註釋。
- 詩歌:依賴性管理和Python包裝工具
文件和內容
/assets :與項目相關的圖像/config :LLM應用程序的配置文件/data :用於此項目的數據集(即,曼聯FC 2022年度報告-177頁PDF文檔)-
/models :GGML的二進製文件量化LLM模型(即,Llama-2-7b-chat) -
/src :LLM應用程序關鍵組件的Python代碼,即llm.py , utils.py和prompts.py -
/vectorstore :文檔的faiss矢量商店 db_build.py腳本到攝入數據集並生成faiss矢量商店main.py :主Python腳本啟動應用程序並通過命令行傳遞用戶查詢pyproject.toml :toml文件以指定使用的依賴項的哪些版本(詩歌)-
requirements.txt :python依賴列表(和版本)
參考
- https://github.com/marella/ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


