Running llama 2 e outros LLMs de código aberto na inferência da CPU localmente para perguntas e respostas do documento
Guia claramente explicado para executar aplicativos Quantized Open-Source LLM nas CPUs usando LLAMA 2, C Transformers, GGML e Langchain
Guia passo a passo para a DataScience : https://towardsdatascience.com/running-llama-2-on-cpu-inference-for-document-qa-3d636037a3d8
Contexto
- Fornecedores de modelo de grande idioma comercial de terceiros (LLM), como o GPT4 do Openai, o uso democratizado por LLM por meio de chamadas de API simples.
- No entanto, há casos em que as equipes exigiriam implantação de modelos auto-gerenciados ou privados por razões como privacidade de dados e regras de residência.
- A proliferação de LLMs de código aberto abriu uma vasta gama de opções para nós, reduzindo assim nossa dependência desses fornecedores de terceiros.
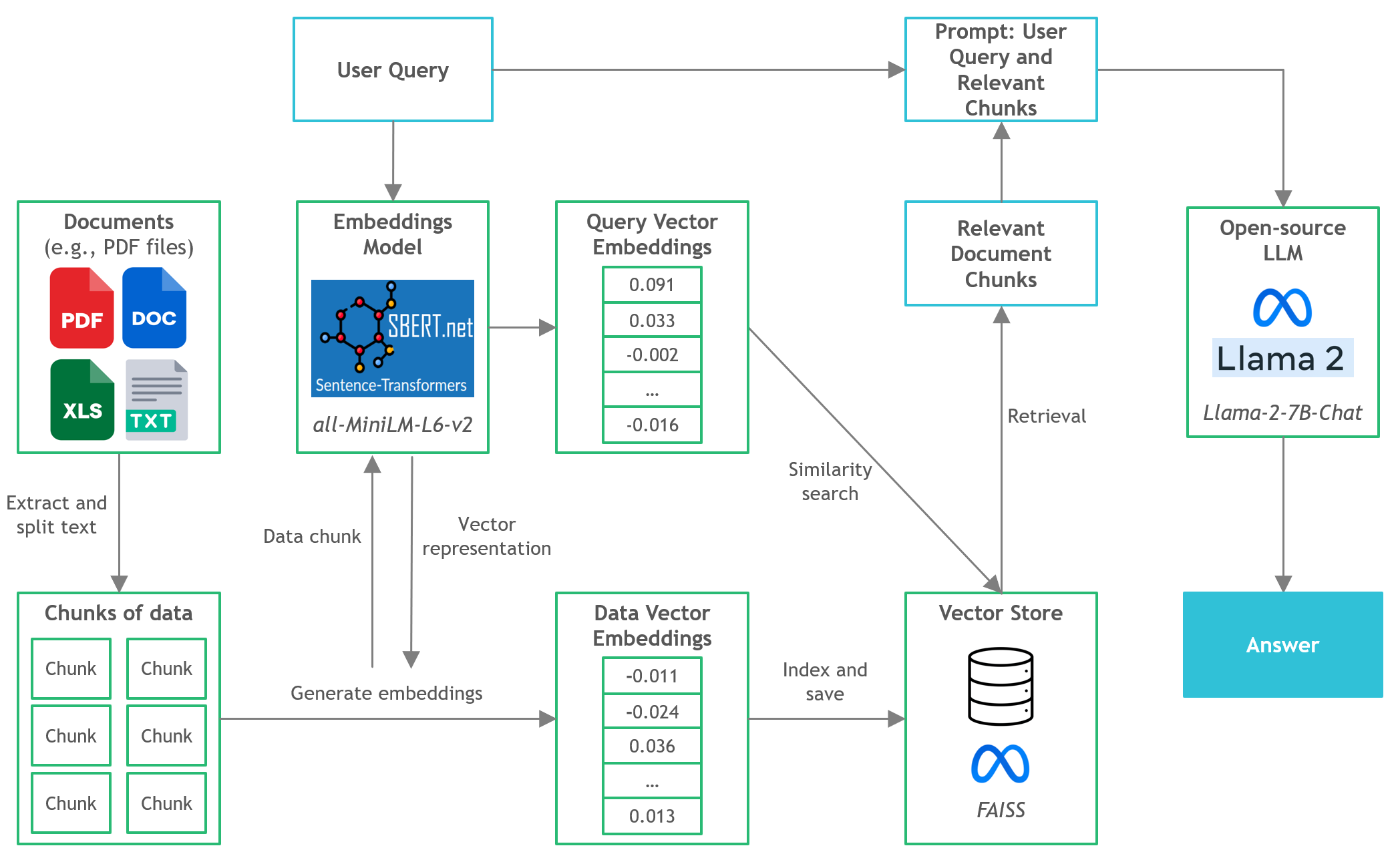
- Quando hospedamos LLMs de código aberto localmente no local ou na nuvem, a capacidade de computação dedicada se torna uma questão-chave. Embora as instâncias da GPU possam parecer a escolha óbvia, os custos podem disparar facilmente além do orçamento.
- Neste projeto, descobriremos como executar versões quantizadas dos LLMs de código aberto na inferência local da CPU para documentos de perguntas e respostas (perguntas e respostas).
Investir rápido
- Certifique-se de baixar o arquivo binário GGML de https://huggingface.co/thebloke/llama-2-7b-chat-ggml e colocado-o nos
models/ pasta - Para iniciar a análise de consultas do usuário no aplicativo, inicie o terminal do diretório do projeto e execute o seguinte comando:
poetry run python main.py "<user query>" - Por exemplo,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - NOTA: omite a
poetry run presa se você não estiver usando poesia

Ferramentas
- Langchain : estrutura para o desenvolvimento de aplicativos alimentados por modelos de idiomas
- C Transformadores : ligações Python para os modelos de transformador implementados em C/C ++ usando a biblioteca GGML
- FAISS : Biblioteca de código aberto para busca eficiente de similaridade e agrupamento de vetores densos.
- Transformadores de frases (Minilm-L6-V2) : modelo de transformador pré-treinado de código aberto para incorporar texto a um espaço vetorial denso dense 384 dimensionais para tarefas como clustering ou pesquisa semântica.
- LLAMA-2-7B-CHAT : Modelo Llama 2 ajustado de código aberto projetado para o diálogo de bate-papo. Aproveita os conjuntos de dados de instruções disponíveis publicamente e mais de 1 milhão de anotações humanas.
- Poesia : ferramenta para gerenciamento de dependência e embalagem Python
Arquivos e conteúdo
-
/assets : imagens relevantes para o projeto -
/config : arquivos de configuração para aplicativo LLM -
/data : DataSet usado para este projeto (ou seja, Relatório Anual do Manchester United FC 2022 - documento PDF de 177 páginas) -
/models : arquivo binário do modelo GGML Quantized LLM (IE, llama-2-7b-chat) -
/src : Códigos Python de componentes -chave do aplicativo LLM, a saber, llm.py , utils.py e prompts.py -
/vectorstore : FAISS Vector Store para documentos -
db_build.py : script python para ingerir o conjunto de dados e gerar o FAISS Vector Store -
main.py : Script Python principal para iniciar o aplicativo e passar à consulta do usuário via linha de comando -
pyproject.toml : arquivo Toml para especificar quais versões das dependências utilizadas (poesia) -
requirements.txt : Lista de dependências Python (e versão)
Referências
- https://github.com/marella/ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrações/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrações/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrações/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


