Ejecutando LLAMA 2 y otros LLM de código abierto en la inferencia de CPU localmente para preguntas y respuestas de documentos
Guía claramente explicada para ejecutar aplicaciones LLM cuantificadas de código abierto en CPU usando Llama 2, C Transformers, GGML y Langchain
Guía paso a paso de paso en DataScience : https://towardsdatascience.com/running-llama-2-on-cpu-inference-for-document-qa-3d636037a3d8
Contexto
- Los proveedores de modelos de idiomas grandes comerciales de terceros (LLM) como el GPT4 de OpenAI han democratizado el uso de LLM a través de simples llamadas de API.
- Sin embargo, hay casos en los que los equipos requerirían una implementación de modelos autogestionados o privados por razones como la privacidad de los datos y las reglas de residencia.
- La proliferación de LLM de código abierto ha abierto una amplia gama de opciones para nosotros, reduciendo así nuestra dependencia de estos proveedores de terceros.
- Cuando alojamos LLM de código abierto localmente en las instalaciones o en la nube, la capacidad de cómputo dedicada se convierte en un tema clave. Si bien las instancias de GPU pueden parecer la opción obvia, los costos pueden dispararse fácilmente más allá del presupuesto.
- En este proyecto, descubriremos cómo ejecutar versiones cuantificadas de LLM de código abierto en la inferencia local de CPU para el documento de preguntas y respuestas (preguntas y respuestas).
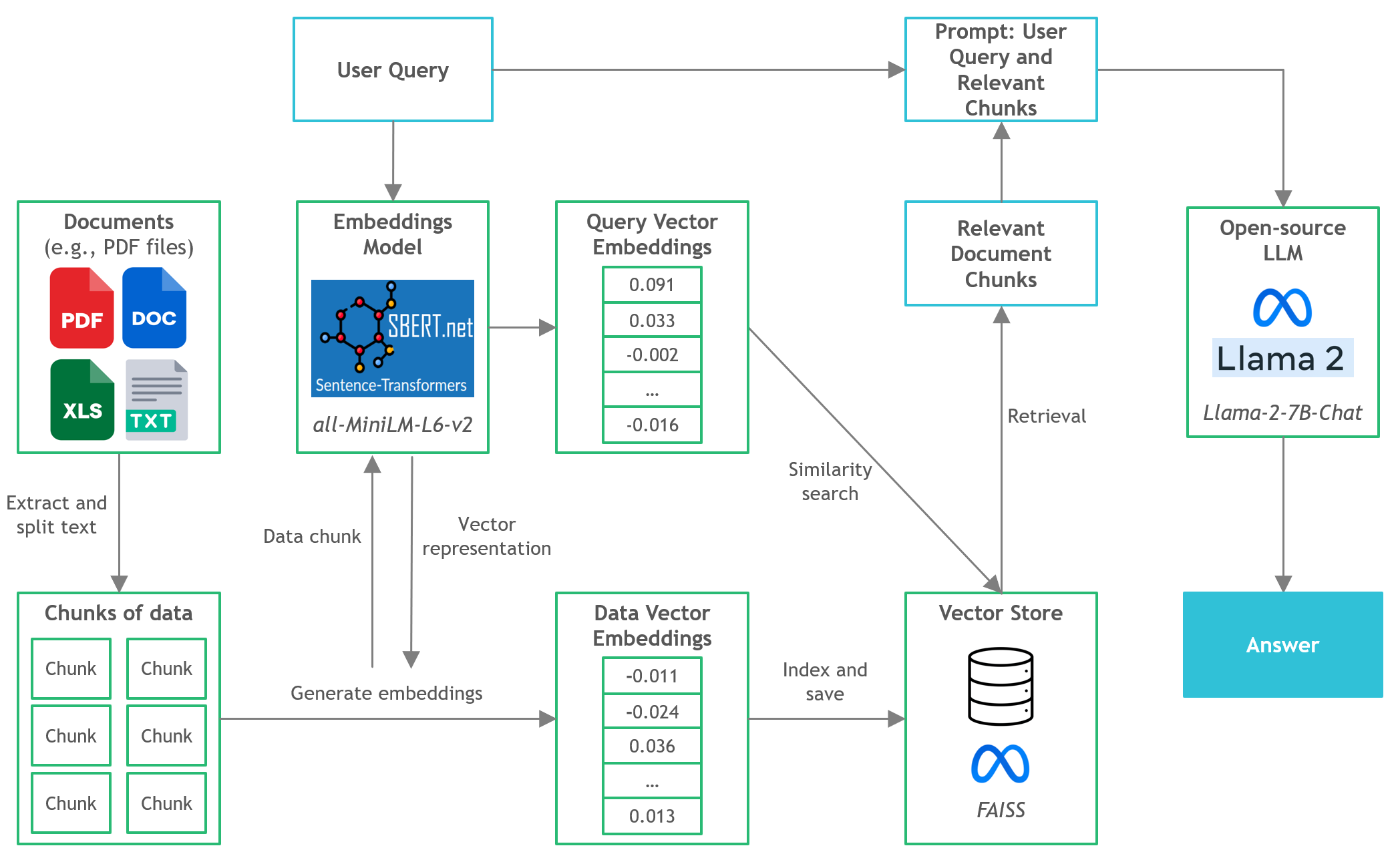
Inicio rápido
- Asegúrese de haber descargado el archivo binario GGML de https://huggingface.co/thebloke/llama-2-7b-chat-ggml y lo colocó en los
models/ carpeta - Para comenzar a analizar las consultas de los usuarios en la aplicación, inicie el terminal desde el directorio del proyecto y ejecute el siguiente comando:
poetry run python main.py "<user query>" - Por ejemplo,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - Nota: omita la
poetry run prependida si no está usando poesía

Herramientas
- Langchain : Marco para desarrollar aplicaciones alimentadas por modelos de idiomas
- C Transformadores : enlaces de pitón para los modelos de transformador implementados en C/C ++ utilizando la biblioteca GGML
- FAISS : biblioteca de código abierto para una búsqueda de similitud eficiente y agrupación de vectores densos.
- Transformadores de oraciones (All-Minilm-L6-V2) : modelo de transformador previamente capacitado de código abierto para incrustar texto a un espacio vectorial denso de 384 dimensiones para tareas como la agrupación o la búsqueda semántica.
- LLAMA-2-7B-CHAT : modelo de Llama 2 de código abierto 2 diseñado para el diálogo de chat. Aprovecha los conjuntos de datos de instrucciones disponibles públicamente y más de 1 millón de anotaciones humanas.
- Poesía : Herramienta para la gestión de dependencias y empaque de Python
Archivos y contenido
-
/assets : imágenes relevantes para el proyecto -
/config : archivos de configuración para la aplicación LLM -
/data : conjunto de datos utilizado para este proyecto (es decir, Manchester United FC 2022 Informe anual - documento PDF de 177 páginas) -
/models : archivo binario del modelo GGML Quantized LLM (es decir, LLAMA-2-7B-CHAT) -
/src : Códigos de Python de componentes clave de la aplicación LLM, a saber, llm.py , utils.py , y prompts.py -
/vectorstore : Faiss Vector Store para documentos -
db_build.py : script de python para ingerir el conjunto de datos y generar faiss vector store -
main.py : Script de Python principal para iniciar la aplicación y aprobar la consulta de usuario a través de la línea de comandos -
pyproject.toml : Toml File para especificar qué versiones de las dependencias utilizadas (poesía) -
requirements.txt : lista de dependencias de Python (y versión)
Referencias
- https://github.com/marella/ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


