Running Llama 2 และ LLMs โอเพนซอร์สอื่น ๆ ในการอนุมาน CPU ในพื้นที่สำหรับ Document Q&A
คู่มืออธิบายอย่างชัดเจนสำหรับการใช้แอปพลิเคชัน LLM โอเพนซอร์สเชิงปริมาณบนซีพียูโดยใช้ Llama 2, C Transformers, GGML และ Langchain
คำแนะนำทีละขั้นตอนเกี่ยวกับไปสู่การศึกษา : https://towardsdatascience.com/running-llama-2-on-cpu-inference-for-document-qa-3d636037a3d8
บริบท
- ผู้ให้บริการโมเดลภาษาขนาดใหญ่เชิงพาณิชย์ (LLM) ของบุคคลที่สามเช่น GPT4 ของ OpenAI มีการใช้ LLM แบบประชาธิปไตยผ่านการโทร API อย่างง่าย
- อย่างไรก็ตามมีกรณีที่ทีมจะต้องมีการปรับใช้รูปแบบการจัดการตนเองหรือส่วนตัวด้วยเหตุผลเช่นความเป็นส่วนตัวของข้อมูลและกฎการอยู่อาศัย
- การแพร่กระจายของ LLMs โอเพนซอร์ซได้เปิดตัวเลือกที่หลากหลายสำหรับเราซึ่งจะช่วยลดการพึ่งพาผู้ให้บริการบุคคลที่สามเหล่านี้
- เมื่อเราโฮสต์ LLM โอเพ่นซอร์สในพื้นที่ในสถานที่หรือในคลาวด์ความสามารถในการคำนวณโดยเฉพาะจะกลายเป็นปัญหาสำคัญ ในขณะที่อินสแตนซ์ GPU อาจดูเหมือนเป็นตัวเลือกที่ชัดเจนค่าใช้จ่ายสามารถพุ่งสูงเกินกว่างบประมาณได้อย่างง่ายดาย
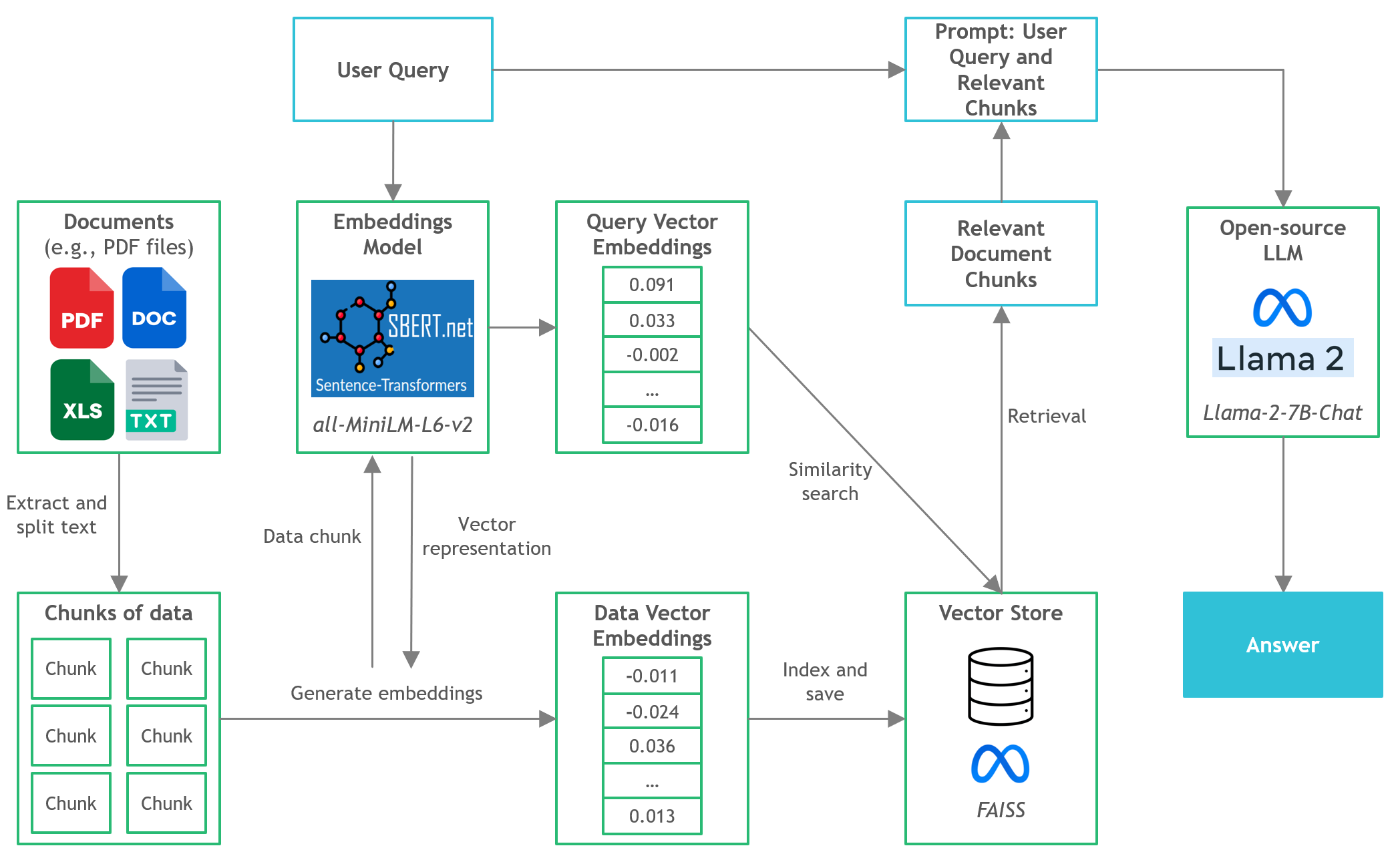
- ในโครงการนี้เราจะค้นพบวิธีเรียกใช้ LLM แบบโอเพนซอร์ซเวอร์ชันเชิงปริมาณในการอนุมาน CPU ในท้องถิ่นสำหรับเอกสารคำถามและคำตอบ (Q&A)
เร็ว
- ตรวจสอบให้แน่ใจว่าคุณได้ดาวน์โหลดไฟล์ไบนารี ggml จาก https://huggingface.co/thebloke/llama-2-7b-chat-ggml และวางลงใน
models/ โฟลเดอร์ - ในการเริ่มการแยกการสอบถามผู้ใช้ลงในแอปพลิเคชันให้เรียกใช้เทอร์มินัลจากไดเรกทอรีโครงการและเรียกใช้คำสั่งต่อไปนี้:
poetry run python main.py "<user query>" - ตัวอย่างเช่น
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - หมายเหตุ: ละเว้น
poetry run ที่ทำไว้ล่วงหน้าหากคุณไม่ได้ใช้บทกวี

เครื่องมือ
- Langchain : เฟรมเวิร์กสำหรับการพัฒนาแอพพลิเคชั่นที่ขับเคลื่อนด้วยโมเดลภาษา
- C Transformers : การผูก Python สำหรับรุ่นหม้อแปลงที่ใช้ใน C/C ++ โดยใช้ไลบรารี GGML
- FAISS : ไลบรารีโอเพ่นซอร์สสำหรับการค้นหาความคล้ายคลึงกันอย่างมีประสิทธิภาพและการจัดกลุ่มของเวกเตอร์หนาแน่น
- SENTENCE-TRANSFORMERS (All-MINILM-L6-V2) : โมเดลหม้อแปลงโอเพนซอร์ซที่ได้รับการฝึกฝนมาก่อนสำหรับการฝังข้อความไปยังพื้นที่เวกเตอร์หนาแน่น 384 มิติสำหรับงานเช่นการจัดกลุ่มหรือการค้นหาความหมาย
- LLAMA-2-7B-Chat : โมเดล Llama 2 ที่ได้รับการปรับแต่งแบบโอเพนซอร์ซออกแบบสำหรับบทสนทนาแชท ใช้ประโยชน์จากชุดข้อมูลการเรียนการสอนที่เปิดเผยต่อสาธารณชนและมีคำอธิบายประกอบของมนุษย์มากกว่า 1 ล้านรายการ
- บทกวี : เครื่องมือสำหรับการจัดการการพึ่งพาและบรรจุภัณฑ์ Python
ไฟล์และเนื้อหา
-
/assets : รูปภาพที่เกี่ยวข้องกับโครงการ -
/config : ไฟล์การกำหนดค่าสำหรับแอปพลิเคชัน LLM -
/data : ชุดข้อมูลที่ใช้สำหรับโครงการนี้ (เช่นแมนเชสเตอร์ยูไนเต็ดเอฟซี 2022 รายงานประจำปี - เอกสาร PDF 177 หน้า) -
/models : ไฟล์ไบนารีของรุ่น LLM เชิงปริมาณ GGML (เช่น, LLAMA-2-7B-Chat) -
/src : รหัส Python ของส่วนประกอบสำคัญของแอปพลิเคชัน LLM คือ llm.py , utils.py และ prompts.py -
/vectorstore : Faiss Vector Store สำหรับเอกสาร -
db_build.py : Python Script ไปยังชุดข้อมูล Ingest และสร้าง Faiss Vector Store -
main.py : Main Python Script เพื่อเปิดแอปพลิเคชันและส่งผ่านการค้นหาผู้ใช้ผ่านบรรทัดคำสั่ง -
pyproject.toml : ไฟล์ toml เพื่อระบุเวอร์ชันของการพึ่งพาที่ใช้ (บทกวี) -
requirements.txt : รายการของ Python Dependencies (และเวอร์ชัน)
การอ้างอิง
- https://github.com/marella/Ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


