Laufen Lama 2 und andere Open-Source-LLMs auf CPU-Inferenz lokal für Dokument Q & A
Eindeutig erklärt Leitfaden für das Ausführen von quantisierten Open-Source-LLM-Anwendungen auf CPUs unter Verwendung von Lama 2, C-Transformatoren, GGML und Langchain
Schritt-nach-Step-Anleitung zudatascience : https://towardsdatascience.com/running-lama-2-on-cpu-inference-ford-document-qa-3d636037a3d8
Kontext
- Anbieter von Drittanbietern (Drittanbieter kommerzielles großes Sprachmodell) wie OpenAIs GPT4 haben die LLM-Verwendung über einfache API-Anrufe demokratisiert.
- Es gibt jedoch Fälle, in denen Teams aus Gründen wie Datenschutz- und Residency-Regeln eine selbstverwaltete oder private Modellbereitstellung erfordern würden.
- Die Verbreitung von Open-Source-LLMs hat uns eine Vielzahl von Optionen eröffnet, wodurch unser Vertrauen in diese Drittanbieter verringert wird.
- Wenn wir Open-Source-LLMs lokal vor Ort oder in der Cloud veranstalten, wird die dedizierte Rechenkapazität zu einem zentralen Problem. Während GPU -Instanzen die offensichtliche Wahl erscheinen mögen, können die Kosten leicht über das Budget hinaus in die Höhe schnellen.
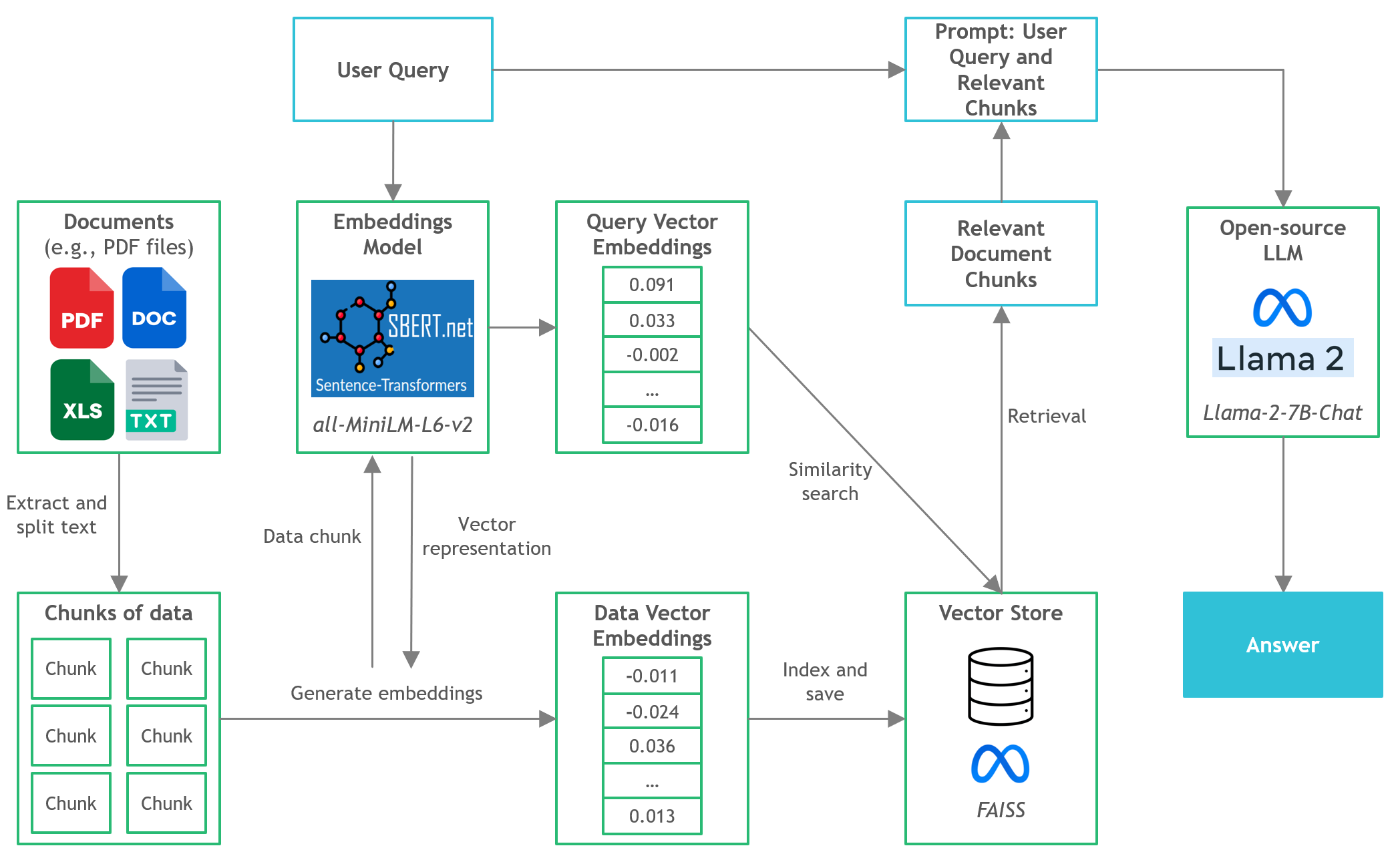
- In diesem Projekt werden wir feststellen, wie quantisierte Versionen von Open-Source LLMs über die lokale CPU-Inferenz für Dokumentfragen-und-Antwort (Q & A) ausgeführt werden.
QuickStart
- Stellen Sie
models/ - Starten Sie das Terminal aus dem Projektverzeichnis und führen Sie den folgenden Befehl aus:
poetry run python main.py "<user query>" - Zum Beispiel
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - HINWEIS: Lassen Sie den Preped
poetry run aus, wenn Sie keine Poesie verwenden

Werkzeuge
- Langchain : Framework für die Entwicklung von Anwendungen, die von Sprachmodellen betrieben werden
- C -Transformatoren : Python -Bindungen für die in C/C ++ implementierten Transformatormodelle unter Verwendung der GGML -Bibliothek
- FAISS : Open-Source-Bibliothek zur effizienten Ähnlichkeitssuche und Clusterbildung dichter Vektoren.
- Satztransformatoren (All-Minilm-L6-V2) : Vorausgebildeter Transformatormodell zum Einbetten von Text in einen 384-dimensionalen dichten Vektorraum für Aufgaben wie Clustering oder semantische Suche.
- LAMA-2-7B-CHAT : Open-Source Fine-abgestimmtes Lama 2-Modell für den Chat-Dialog. Nutzt öffentlich verfügbare Unterrichtsdatensätze und über 1 Million menschliche Anmerkungen.
- Poesie : Tool für Abhängigkeitsmanagement und Python -Verpackung
Dateien und Inhalte
-
/assets : Bilder, die für das Projekt relevant sind -
/config : Konfigurationsdateien für die LLM -Anwendung -
/data : Datensatz, das für dieses Projekt verwendet wird (dh Manchester United FC 2022 Jahresbericht - 177 -seitiges PDF -Dokument) -
/models : Binärdatei des ggml quantisierten LLM-Modells (IE, LLAMA-2-7B-CHAT) -
/src : Python -Codes von Schlüsselkomponenten der LLM -Anwendung, nämlich llm.py , utils.py und prompts.py -
/vectorstore : Faiss Vector Store für Dokumente -
db_build.py : Python -Skript zur Einnahme des Datensatzes und zum Generieren von Faiss Vector Store -
main.py : Haupt -Python -Skript zum Starten der Anwendung und zum Übergeben von Benutzerabfragen über die Befehlszeile -
pyproject.toml : TOML -Datei, um anzugeben, welche Versionen der verwendeten Abhängigkeiten (Poesie) -
requirements.txt : Liste der Python -Abhängigkeiten (und Version)
Referenzen
- https://github.com/marella/ctransformers
- https://huggingface.co/theBloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


