Menjalankan Llama 2 dan LLMS Open-Source lainnya tentang Inferensi CPU secara lokal untuk Dokumen Tanya Jawab
Panduan yang dijelaskan dengan jelas untuk menjalankan aplikasi LLM open-source terkuantisasi pada CPU menggunakan LLAMA 2, C Transformers, GGML, dan Langchain
Panduan Langkah-demi-Langkah Tentang Overdatacience : https://towardsdatacience.com/running-llama-2-on-cpu-inference-for-document-qa-3d636037a3d8
Konteks
- Penyedia Model Bahasa Besar (LLM) pihak ketiga seperti Openai GPT4 telah menggunakan LLM yang didemokratisasi melalui panggilan API sederhana.
- Namun, ada contoh di mana tim akan membutuhkan penyebaran model yang dikelola sendiri atau pribadi untuk alasan seperti privasi data dan aturan residensi.
- Proliferasi Open-Source LLMS telah membuka berbagai pilihan bagi kami, sehingga mengurangi ketergantungan kami pada penyedia pihak ketiga ini.
- Ketika kami meng-host open-source LLMS secara lokal di tempat atau di cloud, kapasitas komputasi khusus menjadi masalah utama. Sementara instance GPU mungkin tampak pilihan yang jelas, biaya dapat dengan mudah meroket di luar anggaran.
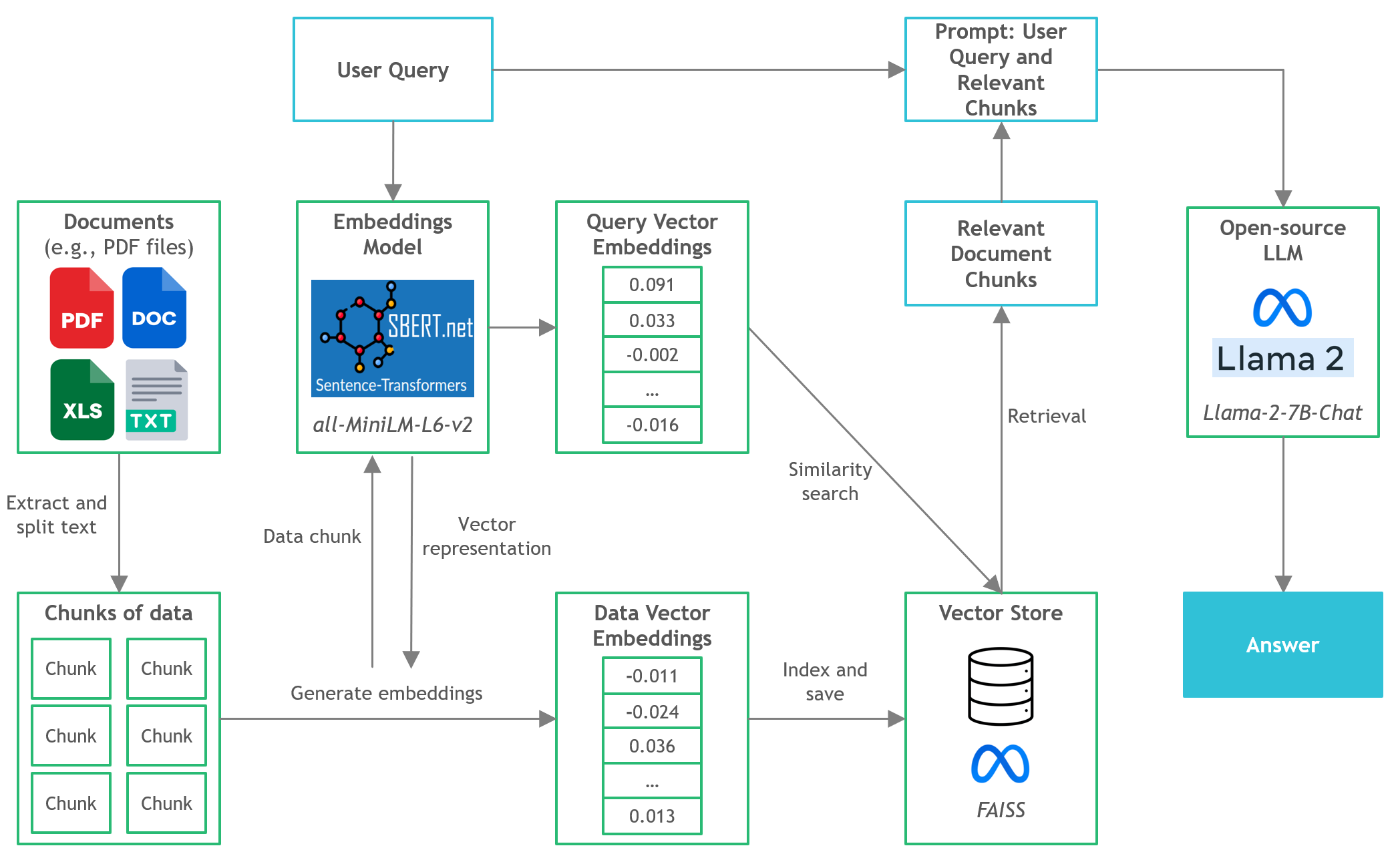
- Dalam proyek ini, kami akan menemukan cara menjalankan versi kuantisasi llms open-source pada inferensi CPU lokal untuk dokumen tanya jawab (T&J).
QuickStart
- Pastikan Anda telah mengunduh file biner GGML dari https://huggingface.co/thebloke/llama-2-7b-cat-ggml dan menempatkannya ke dalam
models/ folder - Untuk memulai parsing kueri pengguna ke dalam aplikasi, luncurkan terminal dari direktori proyek dan jalankan perintah berikut:
poetry run python main.py "<user query>" - Misalnya,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - CATATAN: Hilangkan
poetry run yang diisi sebelumnya jika Anda tidak menggunakan puisi

Peralatan
- Langchain : Kerangka kerja untuk mengembangkan aplikasi yang didukung oleh model bahasa
- C Transformers : Binding Python untuk model transformator yang diimplementasikan dalam C/C ++ menggunakan pustaka GGML
- FAISS : Perpustakaan open-source untuk pencarian kesamaan yang efisien dan pengelompokan vektor padat.
- Transformer kalimat (All-Minilm-L6-V2) : Model transformator pra-terlatih open-source untuk menanamkan teks ke ruang vektor padat 384 dimensi untuk tugas-tugas seperti pengelompokan atau pencarian semantik.
- LLAMA-2-7B-CHAT : Model Llama 2 yang disesuaikan dengan sumber terbuka yang dirancang untuk dialog obrolan. Memanfaatkan set data instruksi yang tersedia untuk umum dan lebih dari 1 juta anotasi manusia.
- Puisi : Alat untuk Manajemen Ketergantungan dan Kemasan Python
File dan konten
-
/assets : gambar yang relevan dengan proyek -
/config : File konfigurasi untuk aplikasi LLM -
/data : Dataset yang digunakan untuk proyek ini (yaitu, Laporan Tahunan Manchester United FC 2022 - Dokumen PDF 177 halaman) -
/models : File Biner Model LLM Kuantisasi GGML (IE, LLAMA-2-7B-CHAT) -
/src : Kode Python dari komponen utama aplikasi LLM, yaitu llm.py , utils.py , dan prompts.py -
/vectorstore : Faiss Vector Store untuk dokumen -
db_build.py : skrip python untuk menelan dataset dan menghasilkan faiss vector store -
main.py : skrip python utama untuk meluncurkan aplikasi dan untuk meneruskan permintaan pengguna melalui baris perintah -
pyproject.toml : file toml untuk menentukan versi mana dari dependensi yang digunakan (puisi) -
requirements.txt : Daftar dependensi Python (dan versi)
Referensi
- https://github.com/marella/ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-cat-ggml
- https://python.langchain.com/en/latest/integations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrasi/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


