在本地CPU推理上运行Llama 2和其他开源LLM
清楚地解释了使用Llama 2,C Transformers,GGML和Langchain在CPU上运行量化开源LLM应用程序的指南
逐步指南todataScience :https://towardsdatascience.com/running-llama-lama-2-on-cpu-inference-for-document-document-qa-3d636037a3d8
语境
- OpenAI的GPT4等第三方商业大型语言模型(LLM)提供商已通过简单的API呼叫将LLM民主化。
- 但是,在某些情况下,由于数据隐私和居住规则等原因,团队需要自我管理或私人模型部署。
- 开源LLM的扩散为我们打开了各种各样的选择,从而减少了我们对这些第三方提供商的依赖。
- 当我们在本地本地或云中托管开源LLMS时,专用的计算能力将成为关键问题。尽管GPU实例似乎是显而易见的选择,但成本很容易超越预算。
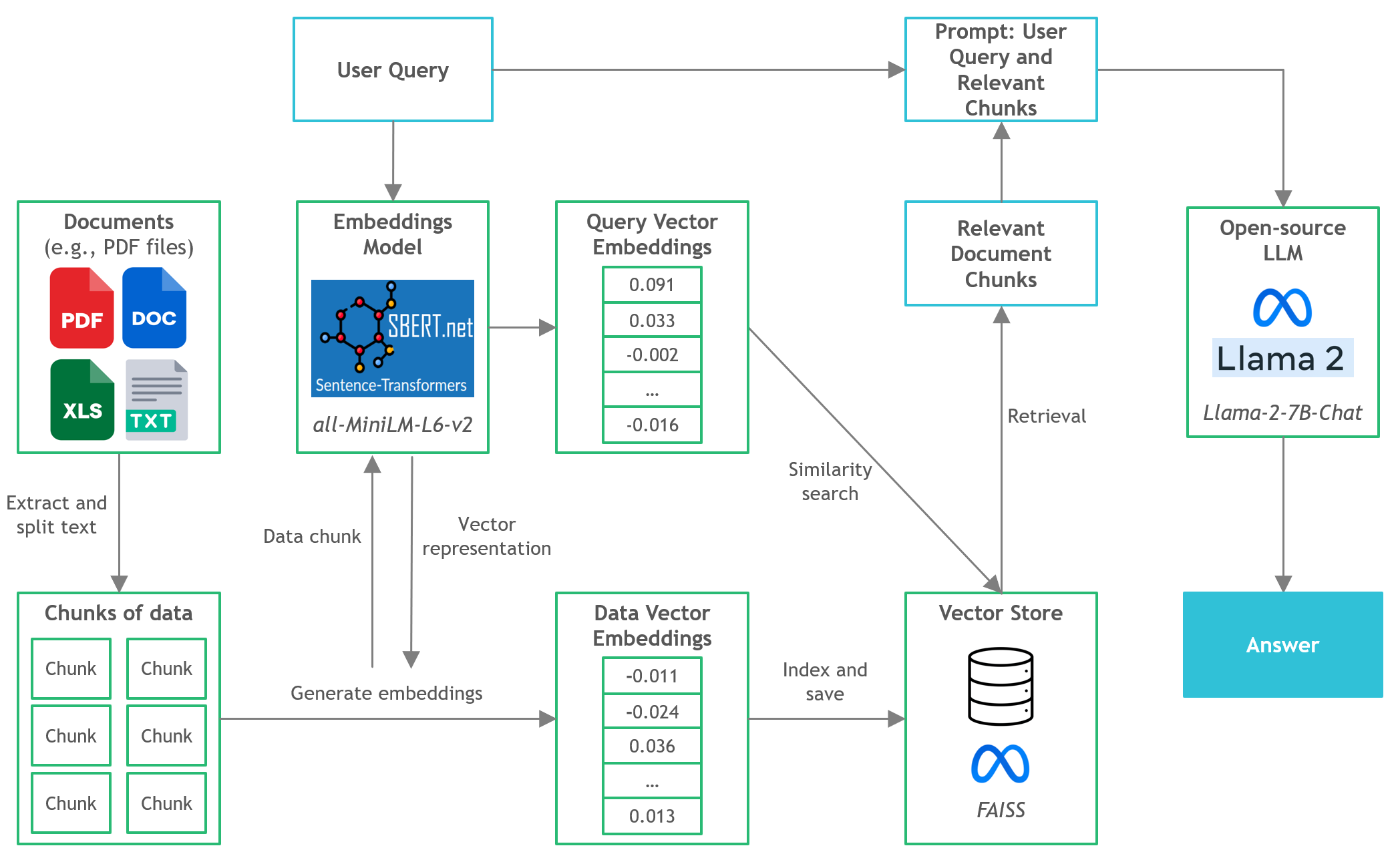
- 在此项目中,我们将发现如何在本地CPU推理中对文档问答(Q&A)运行量化版本的开源版本。
Quickstart
- 确保您从https://huggingface.co/thebloke/llama-2-7b-chat-ggml下载了GGML二进制文件,并将其放入
models/文件夹中 - 要开始将用户查询解析到应用程序中,请从项目目录启动终端并运行以下命令:
poetry run python main.py "<user query>" - 例如,
poetry run python main.py "What is the minimum guarantee payable by Adidas?" - 注意:如果您不使用诗歌,请省略预期
poetry run

工具
- Langchain :开发由语言模型提供支持的应用程序的框架
- C变形金刚:使用GGML库在C/C ++中实现的变压器模型的Python绑定
- FAISS :开源库,用于有效的相似性搜索和密集矢量的聚类。
- 句子转换器(All-Minilm-L6-V2) :开源预训练的变压器模型,用于将文本嵌入到384维密集的矢量空间中,以用于聚类或语义搜索等任务。
- Llama-2-7b-chat :开源微调的Llama 2模型,设计用于聊天对话。利用公开可用的说明数据集和超过100万的人类注释。
- 诗歌:依赖性管理和Python包装工具
文件和内容
/assets :与项目相关的图像/config :LLM应用程序的配置文件/data :用于此项目的数据集(即,曼联FC 2022年度报告-177页PDF文档)-
/models :GGML的二进制文件量化LLM模型(即,Llama-2-7b-chat) -
/src :LLM应用程序关键组件的Python代码,即llm.py , utils.py和prompts.py -
/vectorstore :文档的faiss矢量商店 db_build.py脚本到摄入数据集并生成faiss矢量商店main.py :主Python脚本启动应用程序并通过命令行传递用户查询pyproject.toml :toml文件以指定使用的依赖项的哪些版本(诗歌)-
requirements.txt :python依赖列表(和版本)
参考
- https://github.com/marella/ctransformers
- https://huggingface.co/thebloke
- https://huggingface.co/thebloke/llama-2-7b-chat-ggml
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/readme.md
- https://www.mdpi.com/2189676


