GenerativeRL_Preview
1.0.0
英語| 簡體中文(簡化中文)
Generativerl是生成增強學習的縮寫,是使用生成模型(例如擴散模型和流量模型)來解決增強學習(RL)問題的Python庫。該圖書館旨在提供一個將生成模型的力量與強化學習算法的決策能力相結合的框架。
Generativerl_preview是Generativerl的預覽版,它仍在快速開發中,具有許多實驗功能。對於穩定版本的Generativerl ,請訪問Generativerl。
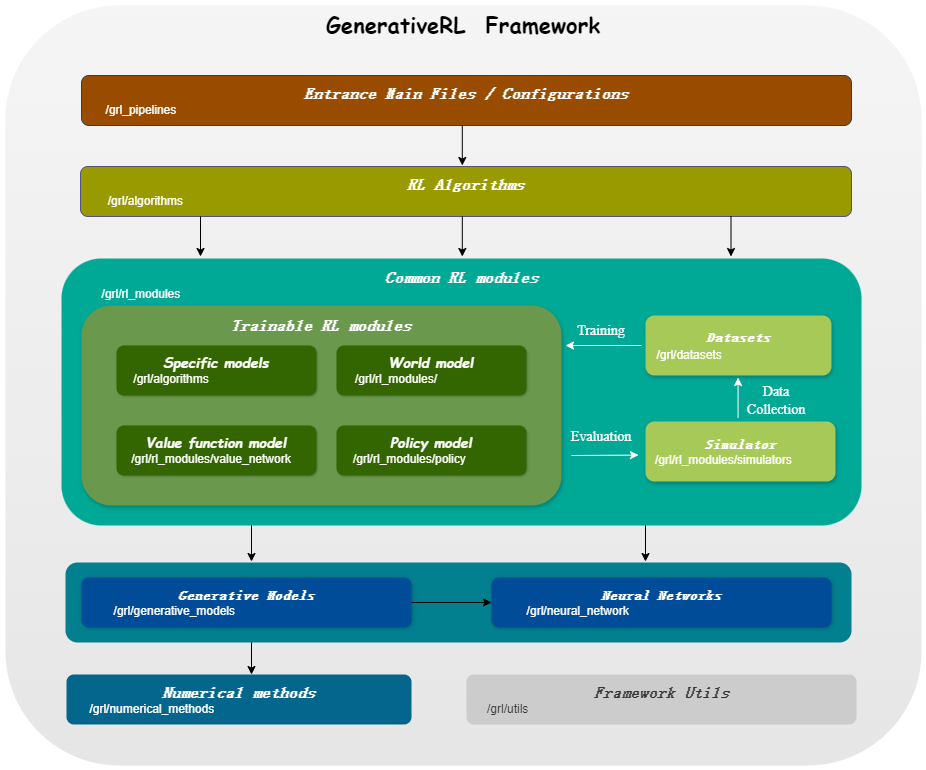
| 連續變量的模型 | 得分匹配 | 流匹配 |
|---|---|---|
| 擴散模型 | ||
| 線性VP SDE | ✔ | ✔ |
| 廣義VP SDE | ✔ | ✔ |
| 線性SDE | ✔ | ✔ |
| 流模型 | ||
| 獨立的條件流匹配 | ✔ | |
| 最佳運輸條件流程匹配 | ✔ |
| 離散變量的模型 | 離散流匹配 |
|---|---|
| U耦合/線性路徑 | ✔ |
| 算法/模型 | 擴散模型 | 流模型 |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| srpo | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
請從來源安裝:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .或者您可以使用Docker映像:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bash這是如何使用Generativerl訓練在Lunarlanderconcontinuum-V2環境中訓練Q引導策略優化(QGPO)的擴散模型的示例。
安裝所需的依賴項:
pip install ' gym[box2d]==0.23.1 '從此處下載數據集並將其保存為當前目錄中的data.npz 。
Generativerl使用wandb進行記錄。使用該帳戶時,它會要求您登錄到您的帳戶。您可以通過運行來禁用它:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )有關更詳細的示例和文檔,請參閱Generativerl文檔。
可以在Generativerl文檔(正在進行的)上找到Generativerl Preview版本的完整文檔。
我們提供幾個案例教程,以幫助您更好地了解Generativerl。在教程中查看更多。
我們提供一些基線實驗來評估生成增強學習算法的性能。在基準測試中查看更多。
我們歡迎對Generativerl的貢獻!如果您有興趣貢獻,請參閱《貢獻指南》。
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl由Apache許可證2.0獲得許可。有關更多詳細信息,請參見許可證。


