GenerativeRL_Preview
1.0.0
영어 | 简体中文 (단순화 된 중국어)
생성 강화 학습을위한 짧은 GenerativerL은 확산 모델 및 흐름 모델과 같은 생성 모델을 사용하여 강화 학습 (RL) 문제를 해결하기위한 파이썬 라이브러리입니다. 이 라이브러리는 생성 모델의 힘을 강화 학습 알고리즘의 의사 결정 능력과 결합하기위한 프레임 워크를 제공하는 것을 목표로합니다.
Generativerl_preview 는 Generativerl 의 미리보기 버전으로, 여전히 많은 실험 기능을 갖춘 빠른 개발 중입니다. Generativerl 의 안정적인 버전은 Generativerl을 방문하십시오.
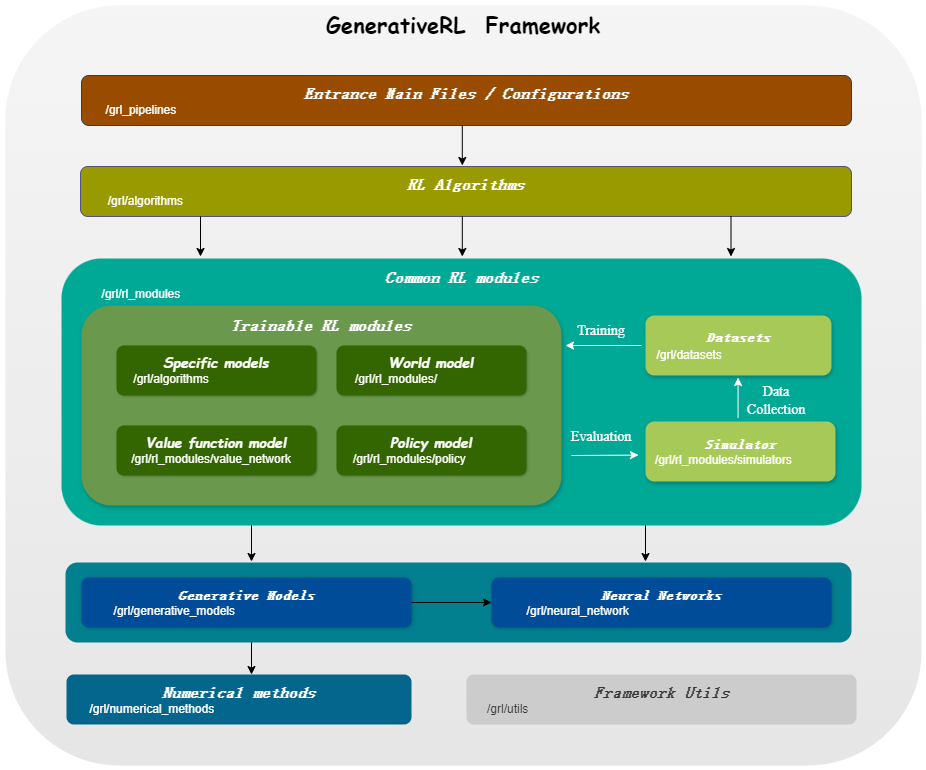
| 연속 변수 모델 | 점수 일치 | 흐름 일치 |
|---|---|---|
| 확산 모델 | ||
| 선형 VP SDE | ✔ | ✔ |
| 일반화 된 VP SDE | ✔ | ✔ |
| 선형 SDE | ✔ | ✔ |
| 흐름 모델 | ||
| 독립적 인 조건부 흐름 일치 | ✔ | |
| 최적의 전송 조건부 흐름 일치 | ✔ |
| 이산 변수 모델 | 불연속 흐름 일치 |
|---|---|
| U- 커플 링/선형 경로 | ✔ |
| Algo./models | 확산 모델 | 흐름 모델 |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
소스에서 설치하십시오 :
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .또는 Docker 이미지를 사용할 수 있습니다.
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bash다음은 GenerativerL을 사용하여 LunarlanderContinous-V2 환경에서 QGPO (Q-Guided Policy Optimization)를위한 확산 모델을 훈련시키는 방법의 예입니다.
필요한 종속성 설치 :
pip install ' gym[box2d]==0.23.1 ' 여기에서 데이터 세트를 다운로드하고 현재 디렉토리에서 data.npz 로 저장하십시오.
Generativerl은 로깅에 WANDB를 사용합니다. 계정을 사용할 때 계정에 로그인하도록 요청합니다. 실행하여 비활성화 할 수 있습니다.
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )자세한 내용과 설명서는 Generativerl 문서를 참조하십시오.
Generativerl 미리보기 버전에 대한 전체 문서는 Generativerl Documentation (진행중인)에서 찾을 수 있습니다.
우리는 GenerativerL을 더 잘 이해하는 데 도움이되는 몇 가지 사례 자습서를 제공합니다. 튜토리얼에서 자세한 내용을보십시오.
우리는 생성 강화 학습 알고리즘의 성능을 평가하기위한 몇 가지 기준 실험을 제공합니다. 벤치 마크에서 더 많은 것을보십시오.
Generativerl에 대한 기여를 환영합니다! 기고에 관심이 있으시면 기고 가이드를 참조하십시오.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl은 Apache 라이센스 2.0에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스를 참조하십시오.


