GenerativeRL_Preview
1.0.0
Englisch | 简体中文 (vereinfachtes Chinesisch)
Generativerl , kurz für generatives Verstärkungslernen, ist eine Python -Bibliothek zum Lösen von Problemen des Verstärkungslernens (RL) unter Verwendung von generativen Modellen wie Diffusionsmodellen und Flussmodellen. Diese Bibliothek zielt darauf ab, einen Rahmen für die Kombination der Kraft generativer Modelle mit den Entscheidungsfunktionen von Verstärkungslernenalgorithmen zu bieten.
Generativerl_Preview ist eine Vorschau -Version von Generativerl , die sich immer noch mit vielen experimentellen Merkmalen in einer schnellen Entwicklung befindet. Für eine stabile Version von Generativerl besuchen Sie Generativerl.
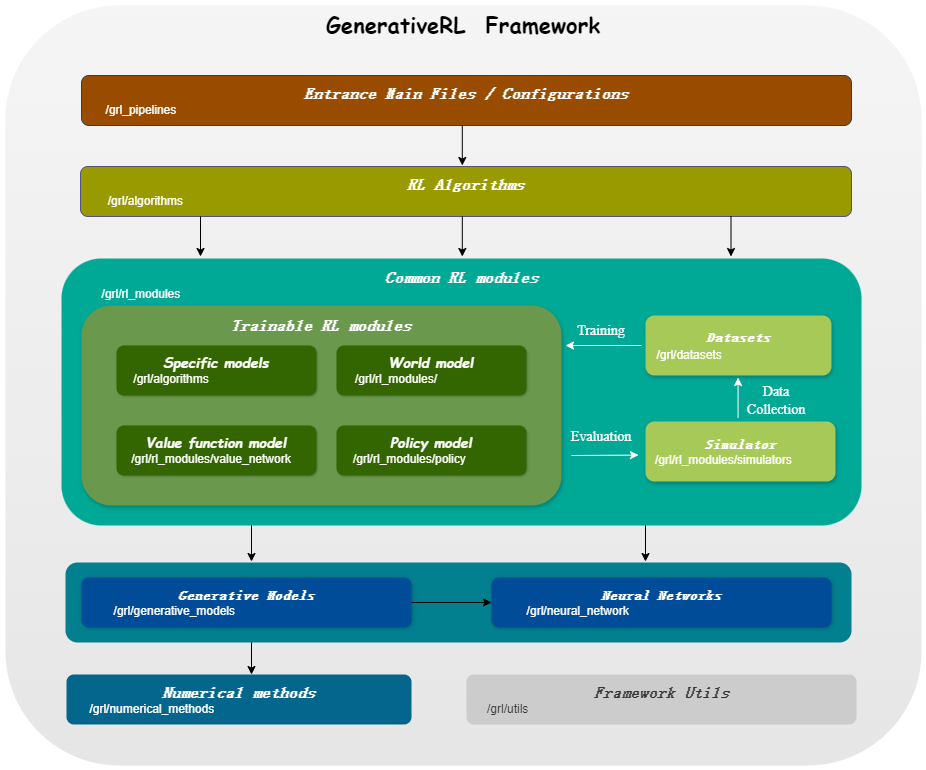
| Modelle für kontinuierliche Variablen | Punktzahl Matching | Flussanpassung |
|---|---|---|
| Diffusionsmodell | ||
| Lineare VP SDE | ✔ | ✔ |
| Verallgemeinerter VP SDE | ✔ | ✔ |
| Linearer SDE | ✔ | ✔ |
| Flussmodell | ||
| Unabhängige bedingte Flussanpassung | ✔ | |
| Optimaler Transportbedingung | ✔ |
| Modelle für diskrete Variablen | Diskreter Flussabgleich |
|---|---|
| U-Kopplung/linearer Pfad | ✔ |
| Algo./Models | Diffusionsmodell | Flussmodell |
|---|---|---|
| Idql | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| Gmpg | ✔ | ✔ |
Bitte installieren Sie aus Quelle:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .Oder Sie können das Docker -Bild verwenden:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashHier ist ein Beispiel dafür, wie ein Diffusionsmodell für die q-gesteuerte Richtlinienoptimierung (QGPO) in der Umgebung von Lunarlandercontinuous-V2 unter Verwendung von Generativerl trainiert wird.
Installieren Sie die erforderlichen Abhängigkeiten:
pip install ' gym[box2d]==0.23.1 ' Laden Sie hier den Datensatz herunter und speichern Sie es als data.npz im aktuellen Verzeichnis.
Generativerl verwendet WANDB für die Protokollierung. Sie werden aufgefordert, sich bei Ihrem Konto anzumelden, wenn Sie es verwenden. Sie können es deaktivieren, indem Sie leiten:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Ausführlichere Beispiele und Dokumentation finden Sie in der Generativerl -Dokumentation.
Die vollständige Dokumentation für die Generativerl -Vorschau -Version finden Sie unter Generativerl -Dokumentation (in Bearbeitung).
Wir bieten mehrere Fall -Tutorials, um Generativerl besser zu verstehen. Weitere Informationen finden Sie in Tutorials.
Wir bieten einige Baseline -Experimente an, um die Leistung generativer Verstärkungslernalgorithmen zu bewerten. Sehen Sie mehr bei Benchmark.
Wir begrüßen Beiträge zu Generativerl! Wenn Sie an einem Beitrag interessiert sind, lesen Sie bitte den beitragenden Leitfaden.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl ist unter der Apache -Lizenz 2.0 lizenziert. Weitere Informationen finden Sie unter Lizenz.


