GenerativeRL_Preview
1.0.0
الإنجليزية | 简体中文 (صيني مبسط)
Generativerl ، قصيرة لتعلم التعزيز التوليدي ، هي مكتبة Python لحل مشاكل التعلم التعزيز (RL) باستخدام نماذج توليدية ، مثل نماذج الانتشار ونماذج التدفق. تهدف هذه المكتبة إلى توفير إطار لدمج قوة النماذج التوليدية وقدرات صنع القرار في خوارزميات التعلم التعزيز.
Generativerl_preview هو نسخة معاينة من cenerativerl ، والتي لا تزال تحت التطوير السريع مع العديد من الميزات التجريبية. للحصول على نسخة مستقرة من Generativerl ، يرجى زيارة Generativerl.
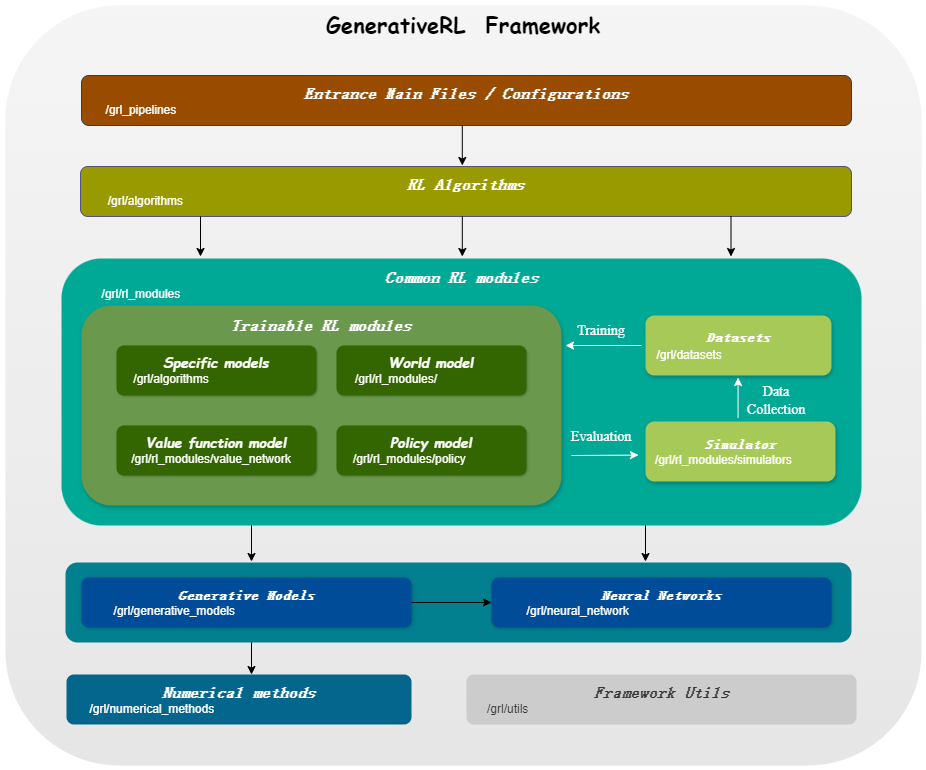
| نماذج للمتغيرات المستمرة | نقاط مطابقة | مطابقة التدفق |
|---|---|---|
| نموذج الانتشار | ||
| خطي نائب الرئيس SDE | ✔ | ✔ |
| VP SDE المعمم | ✔ | ✔ |
| خطي SDE | ✔ | ✔ |
| نموذج التدفق | ||
| مطابقة التدفق الشرطي المستقل | ✔ | |
| مطابقة التدفق الشرطي النقل الأمثل | ✔ |
| نماذج للمتغيرات المنفصلة | مطابقة التدفق المنفصل |
|---|---|
| المسار U/الخطي | ✔ |
| algo./models | نموذج الانتشار | نموذج التدفق |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
الرجاء التثبيت من المصدر:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .أو يمكنك استخدام صورة Docker:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashفيما يلي مثال على كيفية تدريب نموذج الانتشار لتحسين السياسة الموجهة Q (QGPO) في بيئة LunarlanderContinuous-V2 باستخدام Generativerl.
تثبيت التبعيات المطلوبة:
pip install ' gym[box2d]==0.23.1 ' قم بتنزيل مجموعة البيانات من هنا وحفظها كـ data.npz في الدليل الحالي.
يستخدم Generativerl WANDB لتسجيله. سيطلب منك تسجيل الدخول إلى حسابك عند استخدامه. يمكنك تعطيله عن طريق الجري:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )لمزيد من الأمثلة والوثائق التفصيلية ، يرجى الرجوع إلى وثائق Generativerl.
يمكن الاطلاع على الوثائق الكاملة لإصدار معاينة Generativerl في توثيق Generativerl (قيد التقدم).
نحن نقدم العديد من البرامج التعليمية للحالات لمساعدتك على فهم Generativerl بشكل أفضل. رؤية المزيد في البرامج التعليمية.
نحن نقدم بعض التجارب الأساسية لتقييم أداء خوارزميات تعلم التعزيز التوليدي. رؤية المزيد في القياس.
نرحب بالمساهمات في generativerl! إذا كنت مهتمًا بالمساهمة ، فيرجى الرجوع إلى الدليل المساهم.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}تم ترخيص Generativerl بموجب ترخيص Apache 2.0. انظر الترخيص لمزيد من التفاصيل.


