GenerativeRL_Preview
1.0.0
Inglés | 简体中文 (chino simplificado)
Generativerl , abreviatura de un aprendizaje de refuerzo generativo, es una biblioteca de Python para resolver problemas de aprendizaje de refuerzo (RL) utilizando modelos generativos, como modelos de difusión y modelos de flujo. Esta biblioteca tiene como objetivo proporcionar un marco para combinar el poder de los modelos generativos con las capacidades de toma de decisiones de los algoritmos de aprendizaje de refuerzo.
Generativerl_Preview es una versión previa de Generativerl , que todavía está en un desarrollo rápido con muchas características experimentales. Para la versión estable de Generativerl , visite Generativerl.
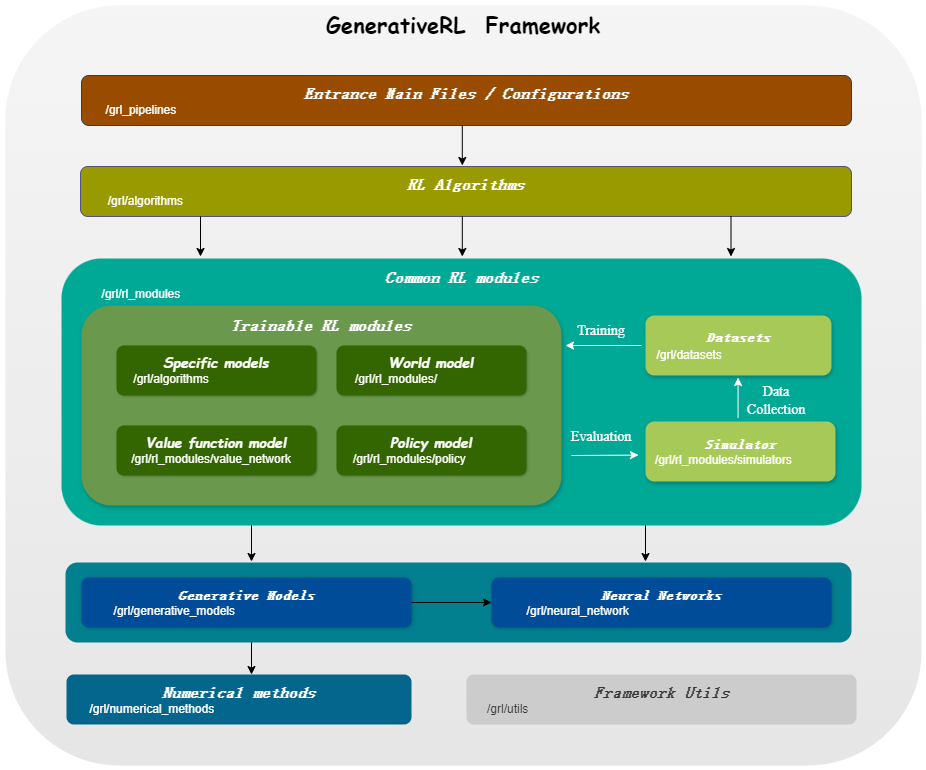
| Modelos para variables continuas | Partida de puntaje | Coincidencia de flujo |
|---|---|---|
| Modelo de difusión | ||
| VP lineal SDE | ✔ | ✔ |
| VP generalizado SDE | ✔ | ✔ |
| SDE lineal | ✔ | ✔ |
| Modelo de flujo | ||
| Coincidencia de flujo condicional independiente | ✔ | |
| Matriota de flujo condicional de transporte óptimo | ✔ |
| Modelos para variables discretas | Coincidencia de flujo discreto |
|---|---|
| Acoplamiento en U/ruta lineal | ✔ |
| Algo./modeles | Modelo de difusión | Modelo de flujo |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| Gmpg | ✔ | ✔ |
Instale desde la fuente:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .O puede usar la imagen Docker:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashAquí hay un ejemplo de cómo capacitar a un modelo de difusión para la optimización de políticas guiadas por Q (QGPO) en el entorno Lunarlandercontinuous-V2 utilizando Generativerl.
Instale las dependencias requeridas:
pip install ' gym[box2d]==0.23.1 ' Descargue el conjunto de datos desde aquí y guárdelo como data.npz en el directorio actual.
Generativerl usa WandB para registrar. Le pedirá que inicie sesión en su cuenta cuando la use. Puede deshabilitarlo ejecutando:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Para ver ejemplos y documentación más detallados, consulte la documentación de Generativerl.
La documentación completa para la versión de vista previa de Generativerl se puede encontrar en GenerAtiverl Documation (en progreso).
Proporcionamos varios tutoriales de casos para ayudarlo a comprender mejor a Generativerl. Ver más en los tutoriales.
Ofrecemos algunos experimentos de referencia para evaluar el rendimiento de los algoritmos de aprendizaje de refuerzo generativo. Ver más en Benchmark.
¡Agradecemos contribuciones a Generativerl! Si está interesado en contribuir, consulte la guía contribuyente.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl tiene licencia bajo la licencia Apache 2.0. Vea la licencia para más detalles.


