GenerativeRL_Preview
1.0.0
ภาษาอังกฤษ | 简体中文 (ภาษาจีนง่าย ๆ )
Generativerl สั้นสำหรับการเรียนรู้การเสริมแรงแบบกำเนิดเป็นห้องสมุด Python สำหรับการแก้ปัญหาการเรียนรู้การเสริมแรง (RL) โดยใช้แบบจำลองการกำเนิดเช่นแบบจำลองการแพร่กระจายและแบบจำลองการไหล ห้องสมุดนี้มีจุดมุ่งหมายเพื่อให้กรอบการทำงานร่วมกันรวมพลังของแบบจำลองการกำเนิดเข้ากับความสามารถในการตัดสินใจของอัลกอริทึมการเรียนรู้การเสริมแรง
Generativerl_Preview เป็นรุ่นตัวอย่างของ Generativerl ซึ่งยังอยู่ภายใต้การพัฒนาอย่างรวดเร็วด้วยคุณสมบัติการทดลองมากมาย สำหรับรุ่นที่เสถียรของ Generativerl กรุณาเยี่ยมชม Generativerl
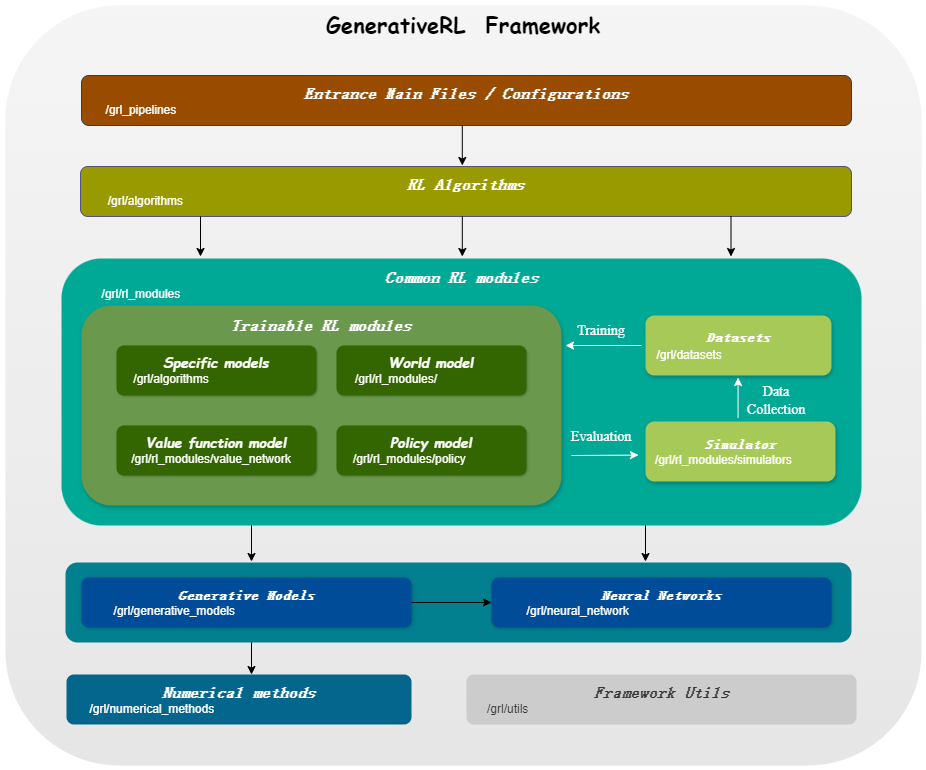
| แบบจำลองสำหรับตัวแปรต่อเนื่อง | การจับคู่คะแนน | การจับคู่การไหล |
|---|---|---|
| รูปแบบการแพร่กระจาย | ||
| VP SDE เชิงเส้น | ||
| VP SDE ทั่วไป | ||
| SDE เชิงเส้น | ||
| โมเดลการไหล | ||
| การจับคู่การไหลแบบมีเงื่อนไขอิสระ | ||
| การจับคู่การไหลแบบเงื่อนไขการขนส่งที่ดีที่สุด |
| แบบจำลองสำหรับตัวแปรที่ไม่ต่อเนื่อง | การจับคู่การไหลแบบไม่ต่อเนื่อง |
|---|---|
| เส้นทาง U-coupling/linear |
| Algo./Models | รูปแบบการแพร่กระจาย | โมเดลการไหล |
|---|---|---|
| idql | ||
| QGPO | ||
| SRPO | ||
| GMPO | ||
| GMPG |
กรุณาติดตั้งจากแหล่งที่มา:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .หรือคุณสามารถใช้อิมเมจนักเทียบท่า:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashนี่คือตัวอย่างของวิธีการฝึกอบรมแบบจำลองการแพร่กระจายสำหรับการเพิ่มประสิทธิภาพนโยบาย Q-Guided (QGPO) ในสภาพแวดล้อม Lunarlandercontinuous-V2 โดยใช้ Generativerl
ติดตั้งการพึ่งพาที่ต้องการ:
pip install ' gym[box2d]==0.23.1 ' ดาวน์โหลดชุดข้อมูลจากที่นี่และบันทึกเป็น data.npz ในไดเรกทอรีปัจจุบัน
Generativerl ใช้ Wandb สำหรับการบันทึก มันจะขอให้คุณเข้าสู่บัญชีของคุณเมื่อคุณใช้ คุณสามารถปิดการใช้งานได้โดยการวิ่ง:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )สำหรับตัวอย่างและเอกสารโดยละเอียดเพิ่มเติมโปรดดูเอกสารประกอบของ Generativerl
เอกสารฉบับเต็มสำหรับเวอร์ชันดูตัวอย่างของ Generativerl สามารถดูได้ที่เอกสาร Generativerl (อยู่ระหว่างดำเนินการ)
เรามีบทเรียนหลายกรณีเพื่อช่วยให้คุณเข้าใจ Generativerl ได้ดีขึ้น ดูเพิ่มเติมที่บทเรียน
เราเสนอการทดลองพื้นฐานบางอย่างเพื่อประเมินประสิทธิภาพของอัลกอริทึมการเรียนรู้การเสริมแรงแบบกำเนิด ดูเพิ่มเติมที่มาตรฐาน
เรายินดีต้อนรับการมีส่วนร่วมของ Generativerl! หากคุณสนใจที่จะมีส่วนร่วมโปรดดูคู่มือการสนับสนุน
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache 2.0 ดูใบอนุญาตสำหรับรายละเอียดเพิ่มเติม


