GenerativeRL_Preview
1.0.0
Английский | 简体中文 (упрощенный китайский)
Generativerl , короткая для обучения генеративному подкреплению, является библиотекой Python для решения задач обучения подкреплению (RL) с использованием генеративных моделей, таких как диффузионные модели и модели потоков. Эта библиотека направлена на то, чтобы обеспечить основу для сочетания мощности генеративных моделей с возможностями принятия решений алгоритмами обучения подкреплению.
Genativerl_preview - это предварительная версия Generativerl , которая до сих пор находится в стадии разработки со многими экспериментальными функциями. Для стабильной версии Generativerl , пожалуйста, посетите Generativerl.
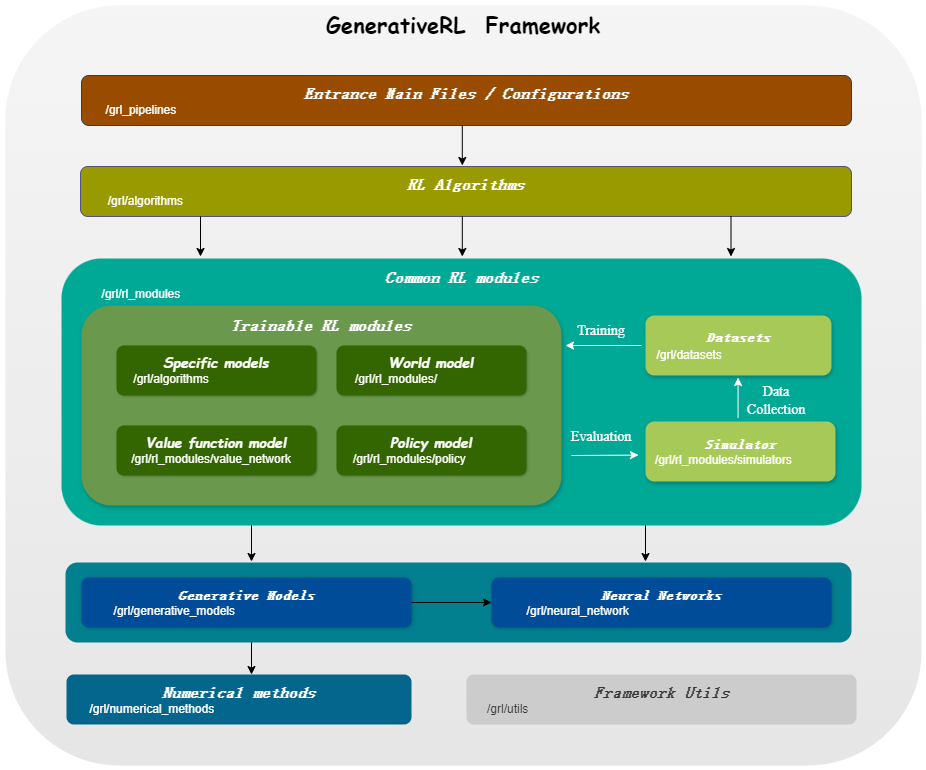
| Модели для непрерывных переменных | Сопоставление счетов | Поток сопоставление |
|---|---|---|
| Диффузионная модель | ||
| Линейный VP SDE | ✔ | ✔ |
| Генерализованный вице -президент SDE | ✔ | ✔ |
| Линейный SDE | ✔ | ✔ |
| Модель потока | ||
| Независимое соответствие условного потока | ✔ | |
| Оптимальное соответствие условного потока транспорта | ✔ |
| Модели для отдельных переменных | Дискретный поток соответствует |
|---|---|
| U-Coupling/Линейный путь | ✔ |
| Algo./models | Диффузионная модель | Модель потока |
|---|---|---|
| Idql | ✔ | |
| QGPO | ✔ | |
| Srpo | ✔ | |
| Gmpo | ✔ | ✔ |
| Gmpg | ✔ | ✔ |
Пожалуйста, установите из источника:
git clone https://github.com/zjowowen/GenerativeRL_Preview.git
cd GenerativeRL_Preview
pip install -e .Или вы можете использовать изображение Docker:
docker pull zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all zjowowen/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashВот пример того, как обучить диффузионную модель для оптимизации политики (QGPO) в среде LunarlanderContinoury-V2 с использованием Generativerl.
Установите требуемые зависимости:
pip install ' gym[box2d]==0.23.1 ' Загрузите набор данных отсюда и сохраните его как data.npz в текущем каталоге.
Generativerl использует Wandb для ведения журнала. Он попросит вас войти в свою учетную запись, когда вы ее используете. Вы можете отключить его, работая:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Для получения более подробных примеров и документации, пожалуйста, обратитесь к документации Generativerl.
Полную документацию для предварительной версии Generativerl можно найти в документации Generativerl (в процессе).
Мы предоставляем несколько учебных пособий, чтобы помочь вам лучше понять Generativerl. Посмотрите больше на учебных пособиях.
Мы предлагаем некоторые базовые эксперименты для оценки производительности алгоритмов обучения генеративным подкреплением. Посмотрите больше на Benchmark.
Мы приветствуем вклад в Generativerl! Если вы заинтересованы в соревнованиях, пожалуйста, обратитесь к руководству.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}Generativerl лицензируется по лицензии Apache 2.0. Смотрите лицензию для более подробной информации.


