query databases with natural language
1.0.0
該項目使通過自然語言與關係數據庫進行互動。具體而言,它使用專家(MOE)模型混合8x7b指令的稀疏混合物,生成SQL查詢,並解釋其相應的表格結果以返回用戶作為答案。該應用程序利用SageMaker託管工具為模型提供服務,該工具可以從Sagemaker Jumpstart中單擊幾下部署。有關更多詳細信息,請參閱此博客文章。
當前,您可以單擊一鍵在SageMaker Jumpstart上部署Mixtral 8x7b。 Amazon Sagemaker Jumpstart提供了一種簡化的方法,可以訪問和部署100多種不同的開源和第三方基礎模型。為了啟動一個端點以從Sagemaker Jumpstart託管Mixtral 8x7b,您可能需要要求增加服務配額以訪問ML.G5.48XLARGE實例以進行端點用法。您可以通過AWS控制台,CLI或API輕鬆地要求增加服務配額以訪問。
您還需要訪問關係數據源。 Amazon RedShift用Tickit數據庫用作本文中的主要數據源。該數據庫可幫助分析師跟踪虛構tick網站的銷售活動,用戶在線購買和出售門票以進行體育賽事,表演和音樂會。
請與您的法律團隊一起查看適用於數據集的任何許可條款,並確認您的用例是否符合該條款。
如果您還沒有一個,則首先需要設置一個紅移集群。使用Amazon Redshift控制台或CLI來啟動帶有所需節點類型和節點數量的群集。確保注意群集端點,數據庫名稱和憑據連接。
群集可用後,在其中創建一個新的數據庫和表以保存關係數據。您可以按照以下步驟從S3加載tickit數據庫的數據。
為了測試您成功將數據添加到紅移集群中。請按照以下步驟:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
如果您獲得了成功的響應,則意味著您將數據庫數據正確加載到集群上。查詢編輯器允許保存,調度和共享查詢。您還可以查看查詢計劃,執行詳細信息和監視查詢性能。
我們建議在Amazon Sagemaker Studio上運行此筆記本。為此,您必須首先設置一個SageMaker域,以確保它具有與Amazon Redshift互動的適當權限。然後,將此GitHub存儲庫克隆到Sagemaker Studio Classic中,並具有以下命令:
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
打開查詢 - amazon-redshift-with-mixtral-8x7b-instruct.ipynb筆記本,以通過它運行。
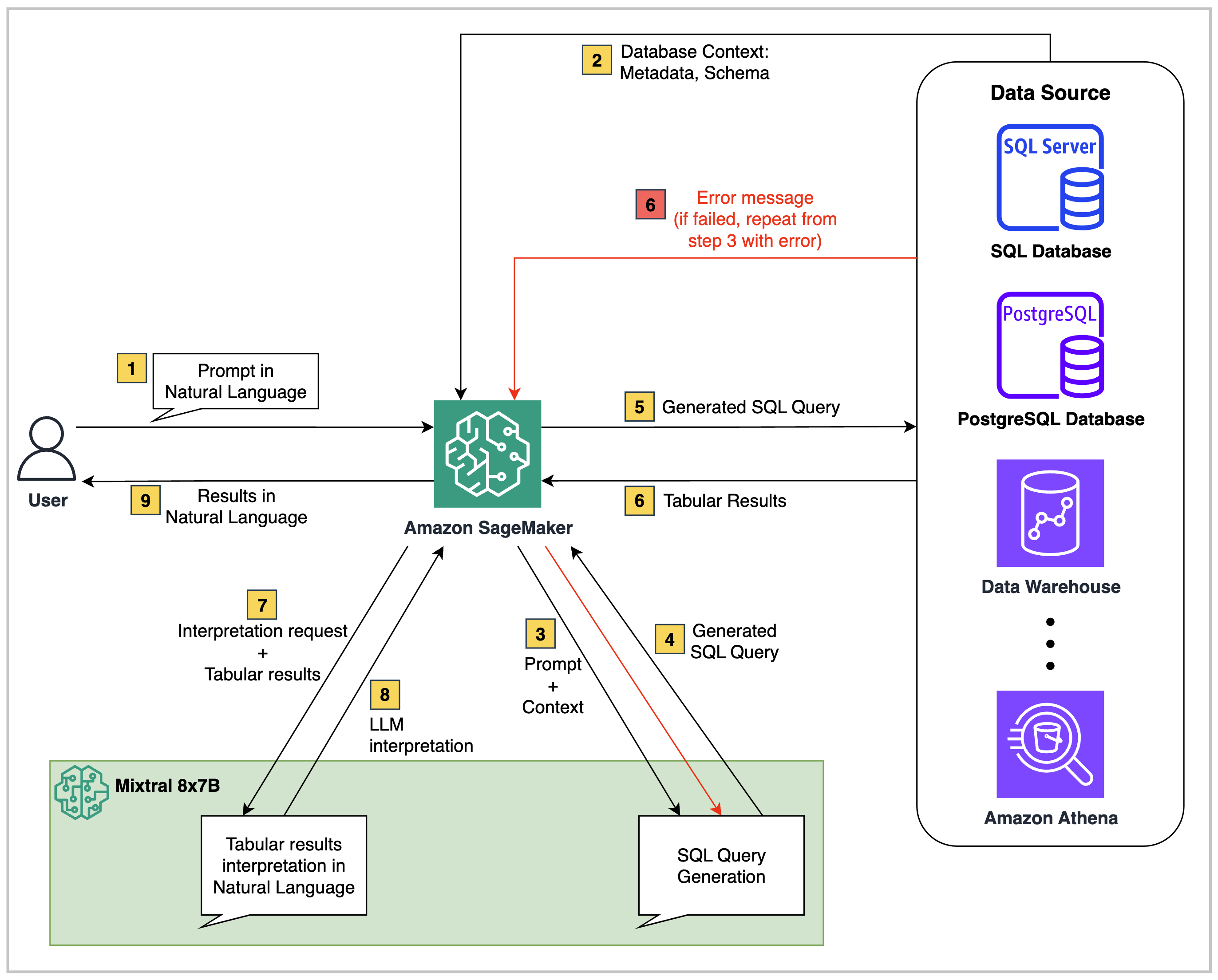
在高級別,Text2SQL解決方案(例如此存儲庫中的一個解決方案)由三個核心組成部分組成:
結構化數據源:這可以是任何關係數據源,例如Amazon RD,Amazon Aurora,AWS Athena或Snowflake。它包含要查詢的業務數據。
基礎模型:一個大型語言模型(LLM),能夠理解源數據庫的數據架構並將自然語言問題映射到相應的SQL查詢中。
編目後端:代碼腳本可以在諸如Sagemaker Studio筆記本,Lambda功能,EC2或EC等環境中執行。最重要的是,您可以選擇添加編排服務,例如AWS步驟功能(如果需要)。
在此存儲庫中提供的代碼中,架構如下:
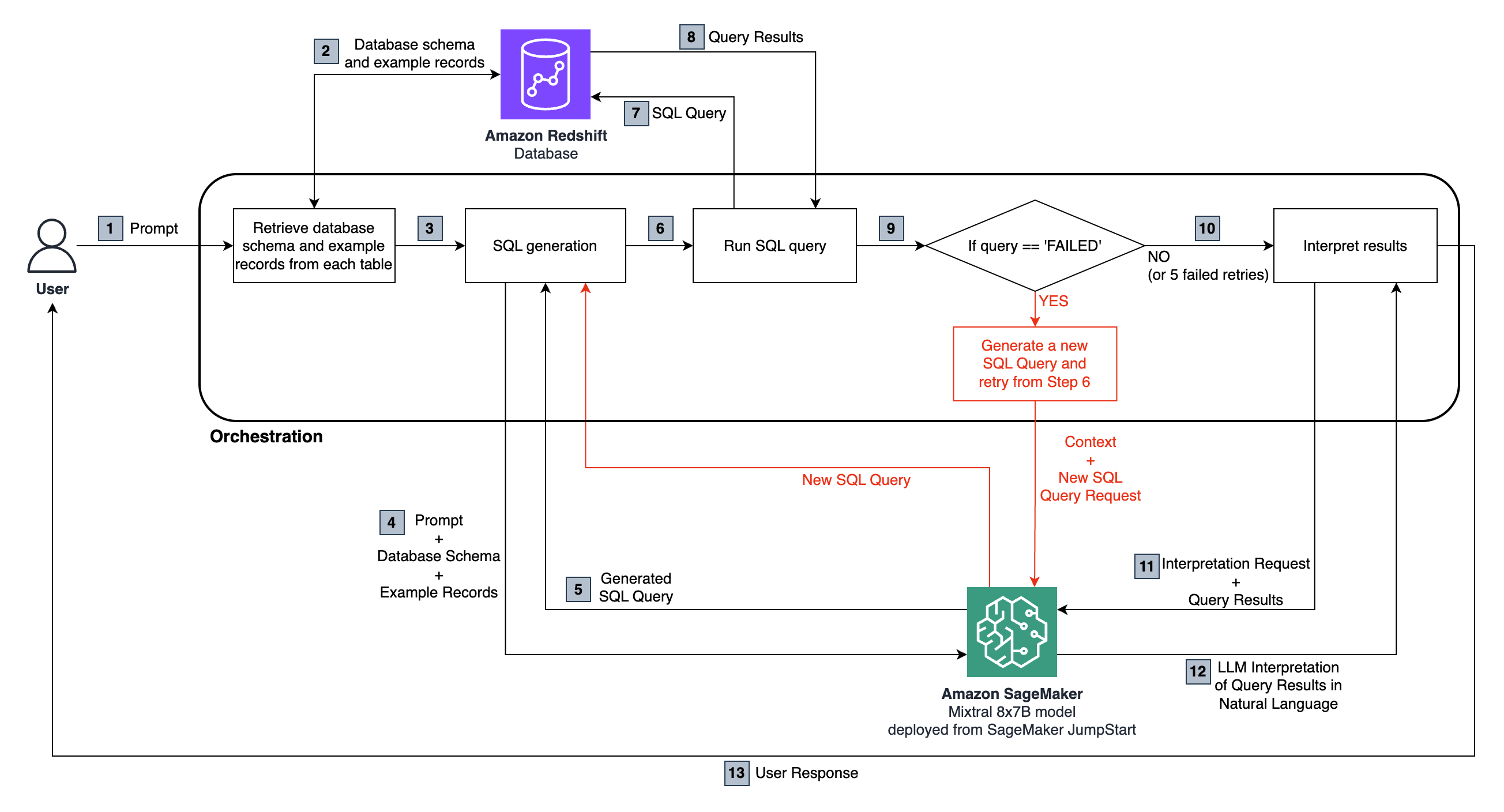
端到端流量如下:
用戶提出了一個自然語言問題,該問題將傳遞給sagemaker託管的Mixtral 8x7b指令模型。
LLM分析問題並使用從連接的紅移數據庫中獲取的架構來生成SQL查詢。
SQL查詢與數據庫運行。如果發生錯誤,則執行重試工作流。
收到的表格結果將傳遞回LLM進行解釋,並將其轉換為用戶原始問題的自然語言響應。
有關實施的逐步演練,請查看參考博客文章。


