query databases with natural language
1.0.0
このプロジェクトにより、自然言語を介してリレーショナルデータベースと対話することができます。具体的には、SQLクエリを生成し、対応する表形式の結果を解釈してユーザーに回答として返すために、エキスパート(MOE)Mixtral 8x7B命令のスパース混合物を使用します。アプリケーションは、SageMaker Jumpstartから数回クリックして展開されるモデルを提供するために、Sagemakerホスティングツールを活用しています。詳細については、このブログ投稿を参照してください。
現在、Sagemaker JumpstartにMixtral 8x7Bをワンクリックで展開できます。 Amazon Sagemaker Jumpstartは、100を超えるオープンソースおよびサードパーティの基礎モデルにアクセスして展開するための簡素化された方法を提供します。 Sagemaker JumpstartからMixtral 8x7Bをホストするエンドポイントを起動するには、 Endpoint使用のためにML.G5.48XLARGEインスタンスにアクセスするためにサービスクォータの増加を要求する必要があります。 AWSコンソール、CLI、またはAPIを介してサービスクォータの増加を簡単に要求して、アクセスできます。
また、リレーショナルデータソースへのアクセスも必要です。 Amazon Redshiftは、この投稿の主要なデータソースとして、The Tickitデータベースを使用して使用されます。このデータベースは、アナリストが架空のThickit Webサイトの販売活動を追跡するのに役立ちます。ユーザーは、スポーツイベント、ショー、コンサートのためにオンラインでチケットを売買します。
法務チームでデータセットに適用されるライセンス条件を確認し、先に進む前にユースケースが条件に準拠していることを確認してください。
まだ持っていない場合は、最初にRedshiftクラスターをセットアップする必要があります。 Amazon Redshift ConsoleまたはCLIを使用して、目的のノードタイプと数のノードを備えたクラスターを起動します。接続するクラスターエンドポイント、データベース名、および資格情報に注意してください。
クラスターが利用可能になったら、新しいデータベースとテーブルを作成して、リレーショナルデータを保持します。これらの手順に従って、S3からThickitデータベースのデータをロードできます。
Redshiftクラスターにデータを正常に追加したことをテストします。次の手順に従ってください:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
応答が成功した場合、データベースデータをクラスターに正しくロードしたことを意味します。クエリエディターを使用すると、クエリを保存、スケジューリング、共有できます。クエリプラン、実行の詳細を表示し、クエリのパフォーマンスを監視することもできます。
このノートブックをAmazon Sagemaker Studioで実行することをお勧めします。そのためには、最初にSagemakerドメインを設定し、Amazon Redshiftと対話するための適切なアクセス許可があることを確認する必要があります。次に、次のコマンドを使用して、このgithubリポジトリをSagemaker Studio Classicにクローンします。
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
Query-Amazon-Redshift-with-mixtral-8x7b-instruct.ipynbノートを開いて実行します。
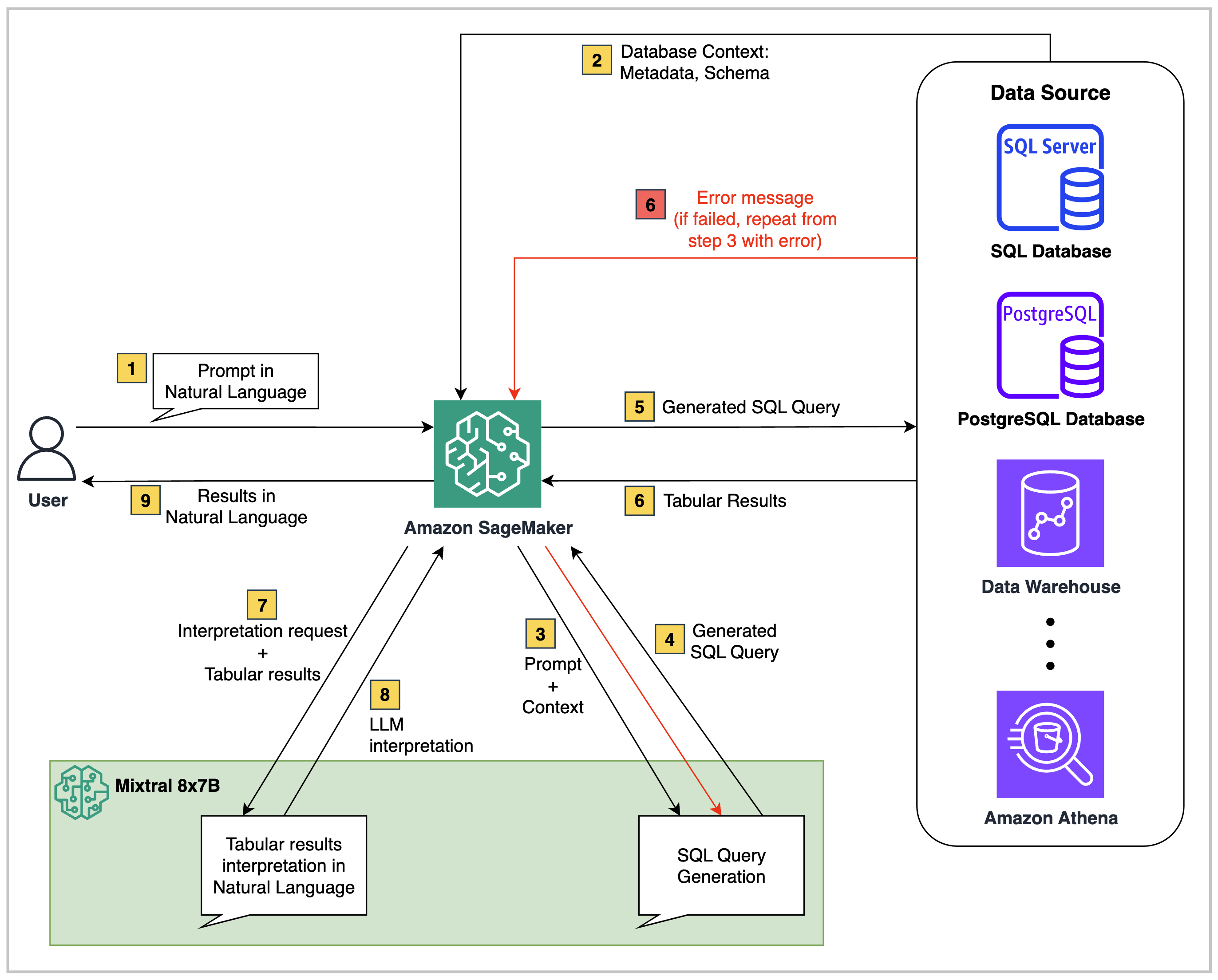
高レベルでは、このリポジトリのようなText2SQLソリューションは、3つのコアコンポーネントで構成されています。
構造化されたデータソース:これは、Amazon RDS、Amazon Aurora、AWS Athena、Snowflakeなどのリレーショナルデータソースです。クエリするビジネスデータが含まれています。
基礎モデル:ソースデータベースのデータスキーマを理解し、自然言語の質問を対応するSQLクエリにマッピングできる大規模な言語モデル(LLM)。
オーケストレーターバックエンド:コードスクリプトは、Sagemaker Studio Notebook、Lambda機能、EC2、またはECSなどの環境で実行できます。それに加えて、必要に応じて、AWSステップ関数などのオーケストレーションサービスをオプションで追加できます。
このリポジトリで提供されているコードでは、アーキテクチャは次のとおりです。
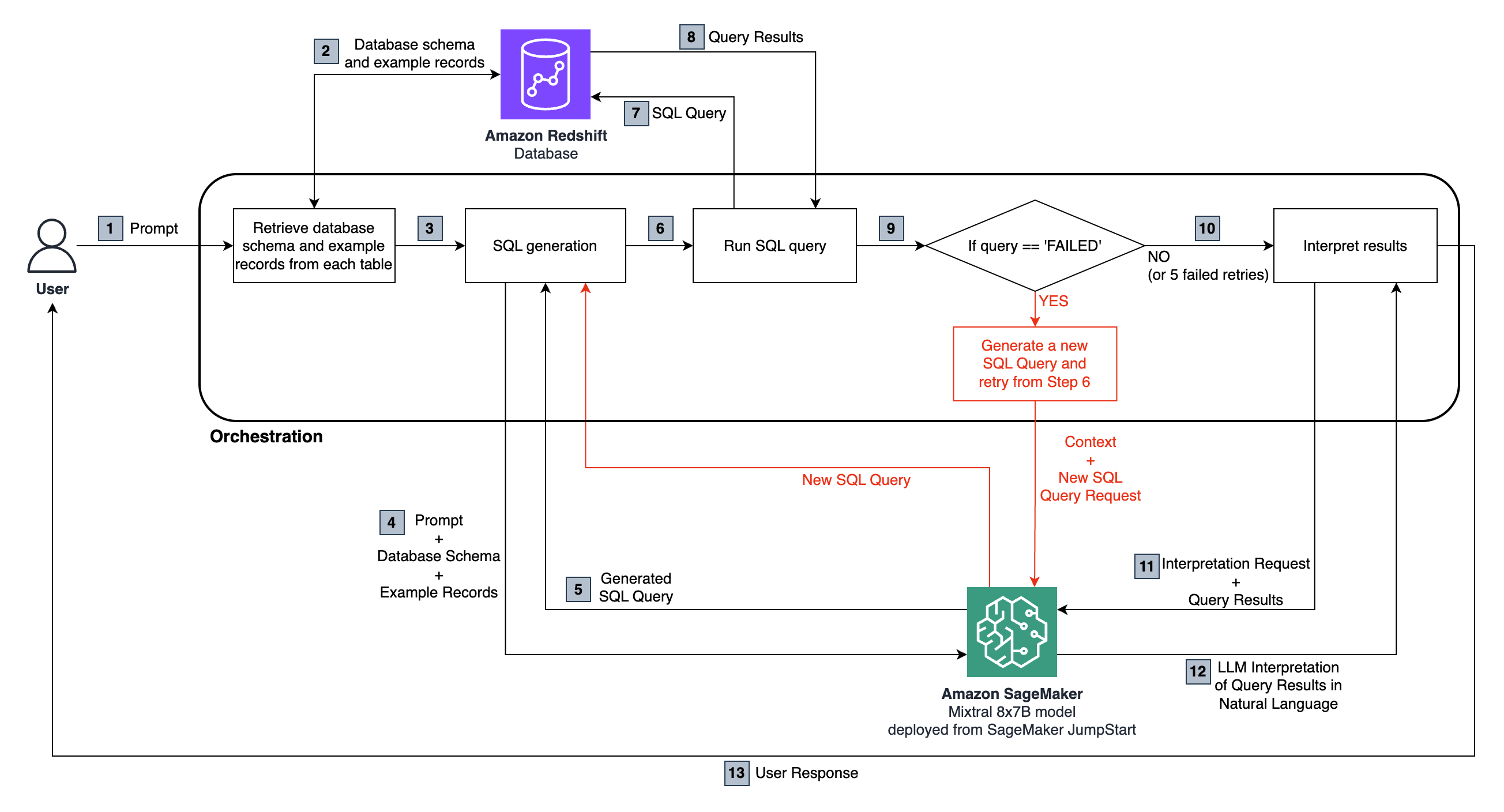
エンドツーエンドのフローは次のとおりです。
ユーザーは、SagemakerでホストされているMixtral 8x7b instruceモデルに渡される自然言語の質問をします。
LLMは質問を分析し、接続されたRedshiftデータベースから取得したスキーマを使用してSQLクエリを生成します。
SQLクエリはデータベースに対して実行されます。エラーが発生した場合、再試行ワークフローが実行されます。
受け取った表形式の結果は、解釈のためにLLMに渡され、ユーザーの元の質問に対する自然言語の応答に変換されます。
実装の段階的なウォークスルーについては、参照BlogPostをご覧ください。


