query databases with natural language
1.0.0
Este projeto permite interagir com bancos de dados relacionais através da linguagem natural. Especificamente, ele usa a mistura esparsa de especialistas (MOE) Model Mixtral 8x7b Instruct, para gerar consultas SQL e interpretar seus resultados tabulares correspondentes para retornar ao usuário como respostas. O aplicativo aproveita as ferramentas de hospedagem de sagemaker para servir o modelo, que é implantado com alguns cliques do Sagemaker Jumpstart. Para mais detalhes, consulte este post do blog.
Atualmente, você pode implantar o Mixtral 8x7b no Sagemaker Jumpstart com um clique. O Amazon Sagemaker Jumpstart fornece uma maneira simplificada de acessar e implantar mais de 100 modelos diferentes de código aberto e de terceiros. Para iniciar um terminal para hospedar o Mixtral 8x7b do Sagemaker Jumpstart, pode ser necessário solicitar um aumento de cota de serviço para acessar uma instância de ML.G5.48XLARGE para uso do ponto de extremidade . Você pode solicitar facilmente aumentos de cota de serviço através do Console, CLI ou API da AWS para obter acesso.
Você também precisará de acesso a uma fonte de dados relacional. O Amazon Redshift é usado como a principal fonte de dados nesta postagem com o banco de dados Tickit. Esse banco de dados ajuda os analistas a rastrear a atividade de vendas para o site fictício, onde os usuários compram e vendem ingressos on -line para eventos esportivos, shows e shows.
Revise os termos de licença aplicáveis ao conjunto de dados com sua equipe jurídica e confirme que seu caso de uso está em conformidade com os termos antes de prosseguir.
Primeiro, você precisará configurar um cluster de desvio para o vermelho se ainda não tiver um. Use o console ou CLI do Amazon Redshift para iniciar um cluster com o tipo de nós desejado e o número de nós. Certifique -se de observar o terminal do cluster, o nome do banco de dados e as credenciais para se conectar.
Depois que o cluster estiver disponível, crie um novo banco de dados e tabelas para manter os dados relacionais. Você pode carregar dados para o banco de dados Tickit de S3 seguindo estas etapas.
Para testar que você adicionou dados com sucesso ao seu cluster de desvio para o vermelho. Siga estas etapas:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
Se você obtiver respostas bem -sucedidas, isso significa que você carregou corretamente os dados do banco de dados no cluster. O editor de consultas permite economizar, agendar e compartilhar consultas. Você também pode visualizar planos de consulta, detalhes de execução e monitorar o desempenho da consulta.
Recomendamos a execução deste caderno no Amazon Sagemaker Studio. Para isso, você deve primeiro configurar um domínio de sagema, certificando -se de que ele tenha as permissões apropriadas para interagir com o Amazon Redshift. Em seguida, clone este repositório do GitHub no Sagemaker Studio Classic com o seguinte comando:
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
Abra o notebook Query-Amazon-Redshift-With-Mixtral-8X7B-Struct.ipynb para executá-lo.
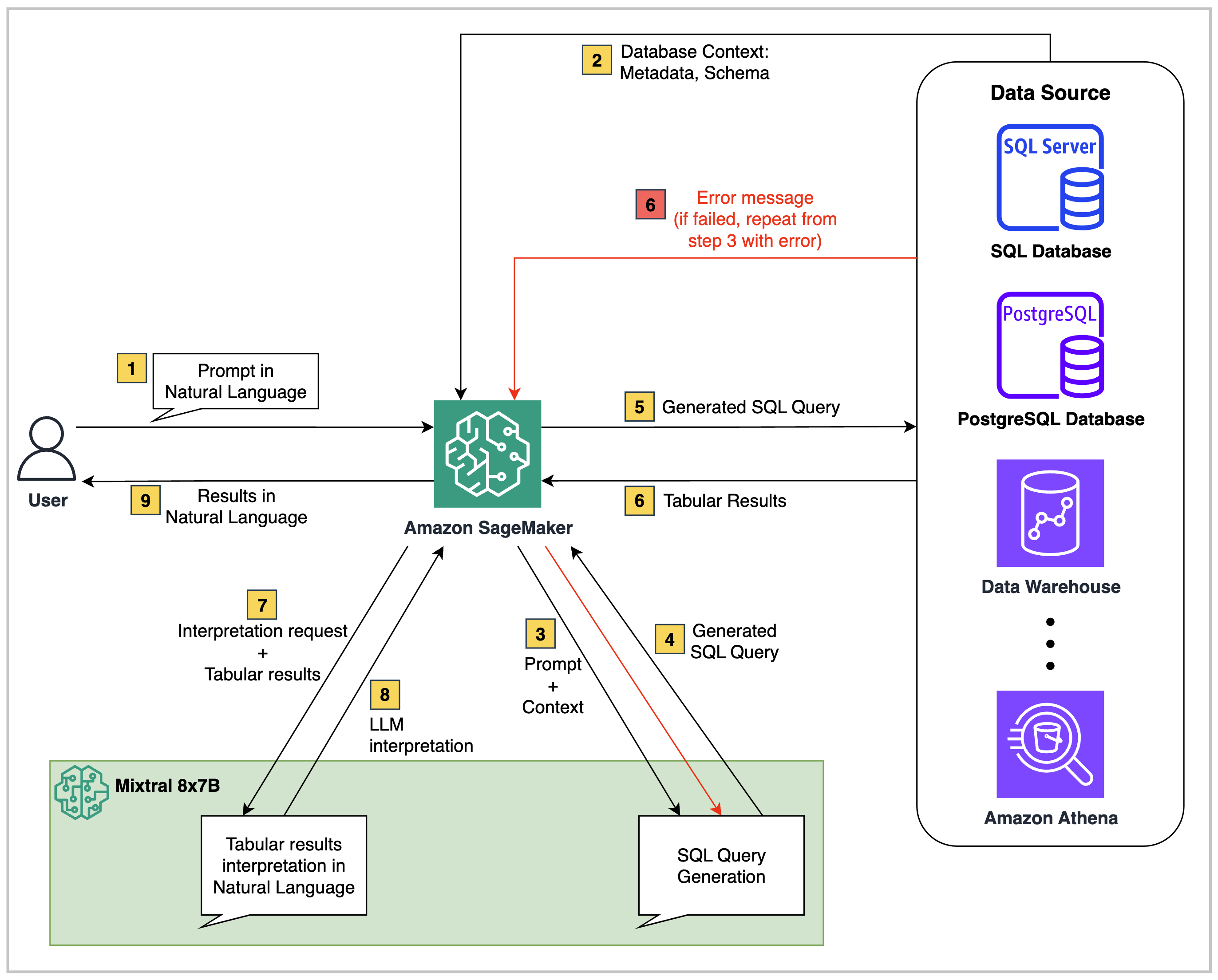
Em um nível alto, as soluções Text2Sql, como a deste repositório, consistem em três componentes principais:
Fonte de dados estruturados : isso pode ser qualquer fonte de dados relacional, como Amazon RDS, Amazon Aurora, AWS Athena ou Snowflake. Ele contém os dados comerciais para consultar.
Modelo de fundação : Um grande modelo de idioma (LLM) capaz de entender o esquema de dados do banco de dados de origem e mapear questões de linguagem natural nas consultas SQL correspondentes.
Orchestrator back-end : Os scripts de código podem ser executados em ambientes como um notebook Sagemaker Studio, uma função Lambda, EC2 ou ECS. Além disso, você pode opcionalmente adicionar um serviço de orquestração, como funções de etapas da AWS, se necessário.
No código fornecido neste repositório, a arquitetura é a seguinte:
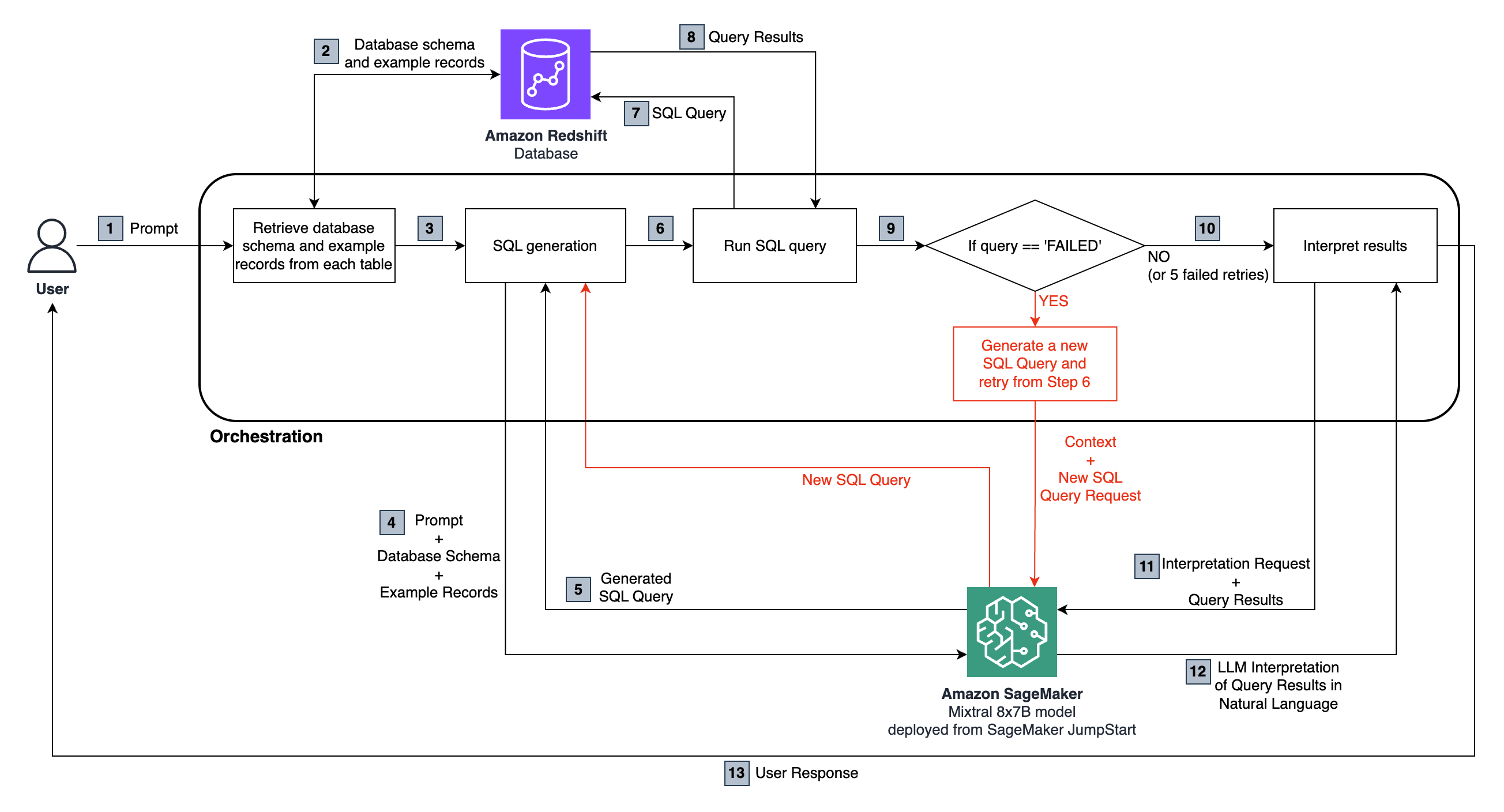
O fluxo de ponta a ponta é o seguinte:
O usuário faz uma pergunta de linguagem natural que é passada para o modelo Mixtral 8x7b Instruct, hospedado em Sagemaker.
O LLM analisa a pergunta e usa o esquema buscado no banco de dados do Redshift conectado para gerar uma consulta SQL.
A consulta SQL é executada no banco de dados. Em caso de erro, um fluxo de trabalho de nova tentativa é executado.
Os resultados tabulares recebidos são transmitidos de volta ao LLM para interpretação e para convertê -los em uma resposta de linguagem natural à pergunta original do usuário.
Para um passo a passo da implementação, confira o blog Post.


