query databases with natural language
1.0.0
Ce projet permet d'interagir avec les bases de données relationnelles à travers le langage naturel. Plus précisément, il utilise le mélange clairsemé d'experts (MOE) Modèle Mixtral 8x7b Instruct, pour générer des requêtes SQL et interpréter leurs résultats tabulaires correspondants pour revenir à l'utilisateur en tant que réponses. L'application exploite des outils d'hébergement Sagemaker pour servir le modèle, qui est déployé en quelques clics de SageMaker Jumpstart. Pour plus de détails, veuillez vous référer à ce blog.
Vous pouvez actuellement déployer Mixtral 8x7b sur SageMaker Jumpstart en un seul clic. Amazon Sagemaker Jumpstart fournit un moyen simplifié d'accéder et de déployer sur 100 modèles de fondation open source et tiers différents. Afin de lancer un point de terminaison pour héberger Mixtral 8x7b de SageMaker Jumpstart, vous devrez peut-être demander une augmentation de quota de service pour accéder à une instance ML.G5.48xlarge pour l'utilisation du point de terminaison . Vous pouvez facilement demander des augmentations de quota de service via la console AWS, la CLI ou l'API pour accéder.
Vous aurez également besoin d'accéder à une source de données relationnelle. Amazon Redshift est utilisé comme source de données principale dans ce post avec la base de données Tickit. Cette base de données aide les analystes à suivre l'activité de vente pour le site Web de Fictional Tickit, où les utilisateurs achètent et vendent des billets en ligne pour des événements sportifs, des spectacles et des concerts.
Veuillez consulter toutes les conditions de licence applicables à l'ensemble de données avec votre équipe juridique et confirmez que votre cas d'utilisation est conforme aux conditions avant la procédure.
Vous devrez d'abord configurer un cluster Redshift si vous n'en avez pas déjà. Utilisez la console ou la CLI Redshift Amazon pour lancer un cluster avec le type de nœud et le nombre de nœuds souhaités. Assurez-vous de noter le point de terminaison du cluster, le nom de la base de données et les informations d'identification pour se connecter.
Une fois le cluster disponible, créez une nouvelle base de données et des tables pour contenir les données relationnelles. Vous pouvez charger des données pour la base de données Tickit à partir de S3 en suivant ces étapes.
Pour tester que vous avez réussi à ajouter des données à votre cluster Redshift. Suivez ces étapes:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
Si vous obtenez des réponses réussies, cela signifie que vous avez correctement chargé les données de la base de données sur le cluster. L'éditeur de requête permet d'enregistrer, de planifier et de partager des requêtes. Vous pouvez également afficher les plans de requête, les détails d'exécution et surveiller les performances de la requête.
Nous vous recommandons d'exécuter ce cahier dans Amazon Sagemaker Studio. Pour cela, vous devez d'abord configurer un domaine SageMaker, en vous assurant qu'il a les autorisations appropriées pour interagir avec Amazon Redshift. Ensuite, clone ce référentiel GitHub dans Sagemaker Studio Classic avec la commande suivante:
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
Ouvrez la requête-Amazon-Redshift-with-mixtral-8x7b-instructe.ipynb Notebook pour l'exécuter.
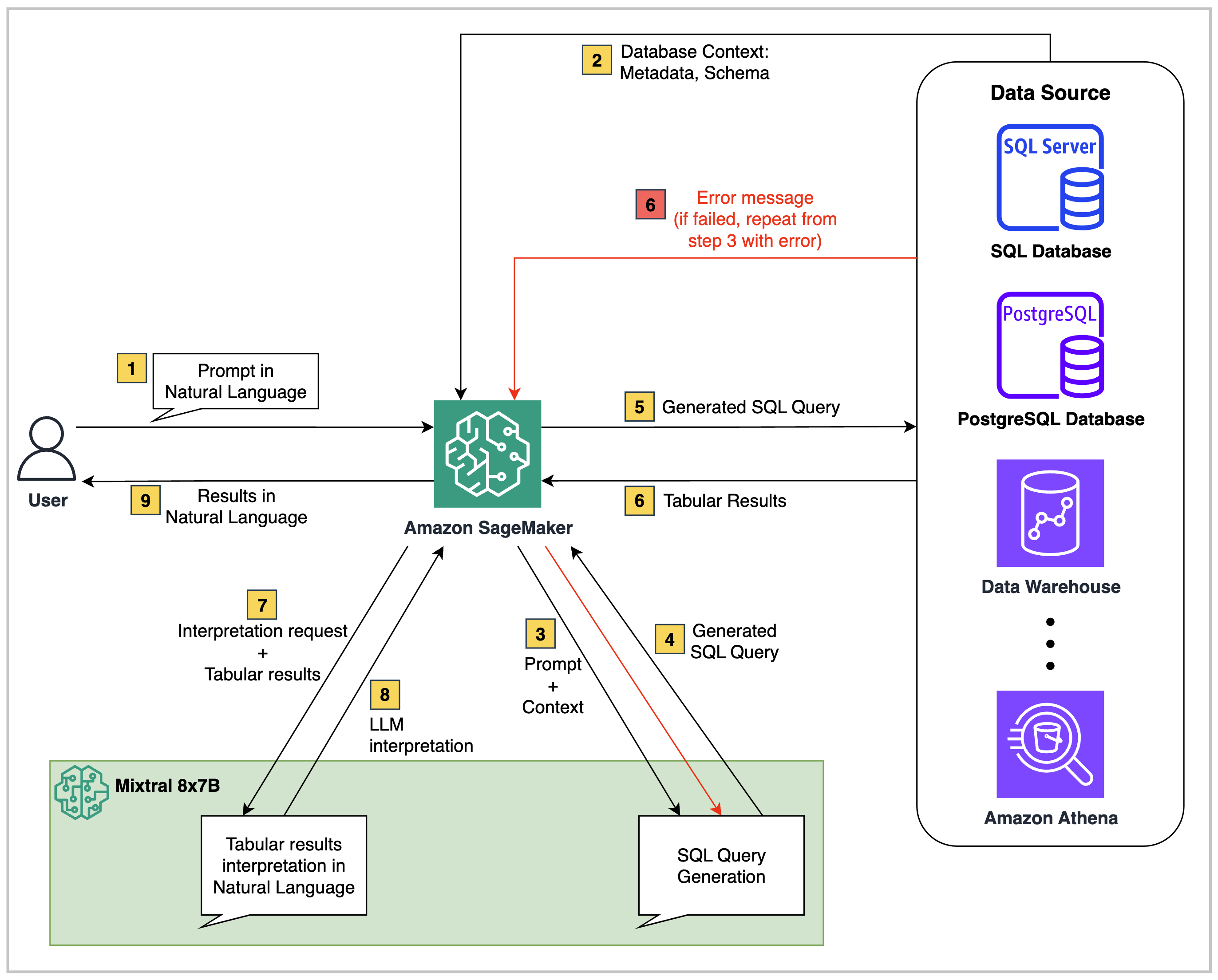
À un niveau élevé, des solutions text2sql telles que celle de ce référentiel se composent de trois composants principaux:
Source de données structurée : il peut s'agir de n'importe quelle source de données relationnelle telle qu'Amazon RDS, Amazon Aurora, AWS Athena ou Snowflake. Il contient les données commerciales à interroger.
Modèle de fondation : un modèle grand langage (LLM) qui est capable de comprendre le schéma de données de la base de données source et de mapper les questions en langage naturel dans les requêtes SQL correspondantes.
Orchestrator Back-end : Les scripts de code peuvent être exécutés dans des environnements tels qu'un ordinateur portable SageMaker Studio, une fonction Lambda, EC2 ou ECS. En plus de cela, vous pouvez éventuellement ajouter un service d'orchestration, tel que les fonctions AWS Step, si nécessaire.
Dans le code fourni dans ce référentiel, l'architecture est la suivante:
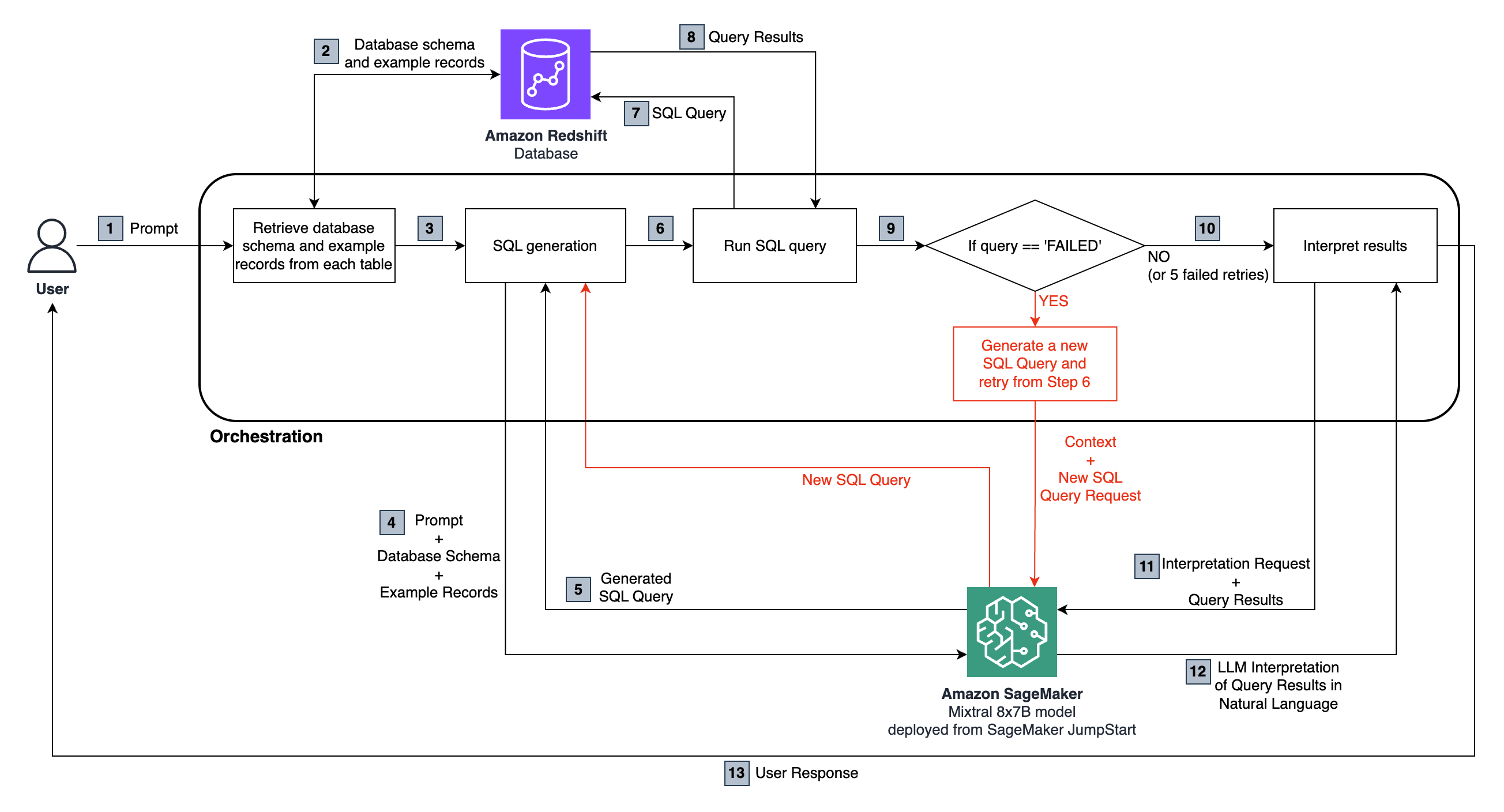
Le flux de bout en bout est le suivant:
L'utilisateur pose une question de langue naturelle qui est transmise au modèle d'instruct de Mixtral 8x7b, hébergé dans SageMaker.
Le LLM analyse la question et utilise le schéma obtenu à partir de la base de données Redshift connectée pour générer une requête SQL.
La requête SQL est exécutée par rapport à la base de données. En cas d'erreur, un flux de travail de réessayer est exécuté.
Les résultats tabulaires reçus sont remis au LLM pour l'interprétation et pour les convertir en une réponse en langage naturel à la question initiale de l'utilisateur.
Pour une procédure étape par étape de la mise en œuvre, veuillez consulter le blog de référence.


