query databases with natural language
1.0.0
이 프로젝트를 통해 자연어를 통한 관계형 데이터베이스와 상호 작용할 수 있습니다. 구체적으로, SQL 쿼리를 생성하고 해당 테이블 결과를 해석하여 사용자에게 답변으로 반환하기 위해 전문가 (MOE) 모델 Mixtral 8x7b의 희소 혼합을 사용합니다. 이 응용 프로그램은 Sagemaker Hosting Tools를 활용하여 Sagemaker JumpStart에서 몇 번의 클릭으로 배포됩니다. 자세한 내용은이 블로그 포스트를 참조하십시오.
현재 Sagemaker Jumpstart에서 한 번의 클릭으로 Mixtral 8x7b를 배포 할 수 있습니다. Amazon Sagemaker Jumpstart는 100 가지가 넘는 오픈 소스 및 타사 재단 모델에 액세스하고 배포하는 단순화 된 방법을 제공합니다. SageMaker JumpStart에서 믹스 트랄 8x7b 호스트로 엔드 포인트를 시작하려면 엔드 포인트 사용에 대한 ML.G5.48XLARGE 인스턴스 에 액세스하려면 서비스 할당량 증가를 요청해야 할 수도 있습니다. AWS 콘솔, CLI 또는 API를 통해 서비스 할당량 증가를 쉽게 요청하여 액세스 할 수 있습니다.
또한 관계형 데이터 소스에 대한 액세스가 필요합니다. Amazon Redshift는 TickIT 데이터베이스와 함께이 게시물의 기본 데이터 소스로 사용됩니다. 이 데이터베이스는 분석가가 가상의 Tickit 웹 사이트의 영업 활동을 추적하는 데 도움이됩니다. 여기서 사용자는 스포츠 이벤트, 쇼 및 콘서트를 위해 온라인으로 티켓을 구매하고 판매합니다.
법무 팀과 데이터 세트에 적용되는 라이센스 약관을 검토하고 진행하기 전에 사용 사례가 이용 약관을 준수하는지 확인하십시오.
아직 없으면 먼저 빨간 편이 클러스터를 설정해야합니다. Amazon Redshift 콘솔 또는 CLI를 사용하여 원하는 노드 유형과 노드 수를 가진 클러스터를 시작하십시오. 클러스터 엔드 포인트, 데이터베이스 이름 및 연결할 자격 증명에 유의하십시오.
클러스터를 사용할 수있게되면 관계형 데이터를 유지하기 위해 새 데이터베이스와 테이블을 작성하십시오. 이 단계에 따라 S3의 TickIT 데이터베이스에 대한 데이터를로드 할 수 있습니다.
테스트하려면 Redshift 클러스터에 데이터를 성공적으로 추가했습니다. 다음 단계를 따르십시오.
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
성공적인 응답을 받으면 데이터베이스 데이터를 클러스터에 올바르게로드했음을 의미합니다. 쿼리 편집기를 사용하면 쿼리를 저장, 예약 및 공유 할 수 있습니다. 쿼리 계획, 실행 세부 정보 및 모니터 쿼리 성능을 볼 수도 있습니다.
Amazon Sagemaker Studio 에서이 노트를 운영하는 것이 좋습니다. 이를 위해 먼저 Sagemaker 도메인을 설정하여 Amazon Redshift와 상호 작용할 수있는 적절한 권한이 있는지 확인해야합니다. 그런 다음이 Github 저장소를 다음 명령으로 Sagemaker Studio Classic으로 복제하십시오.
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
Query-Amazon-Redshift-With-Mixtral-8x7b-Instruct.ipynb 노트북을 열어서 실행하십시오.
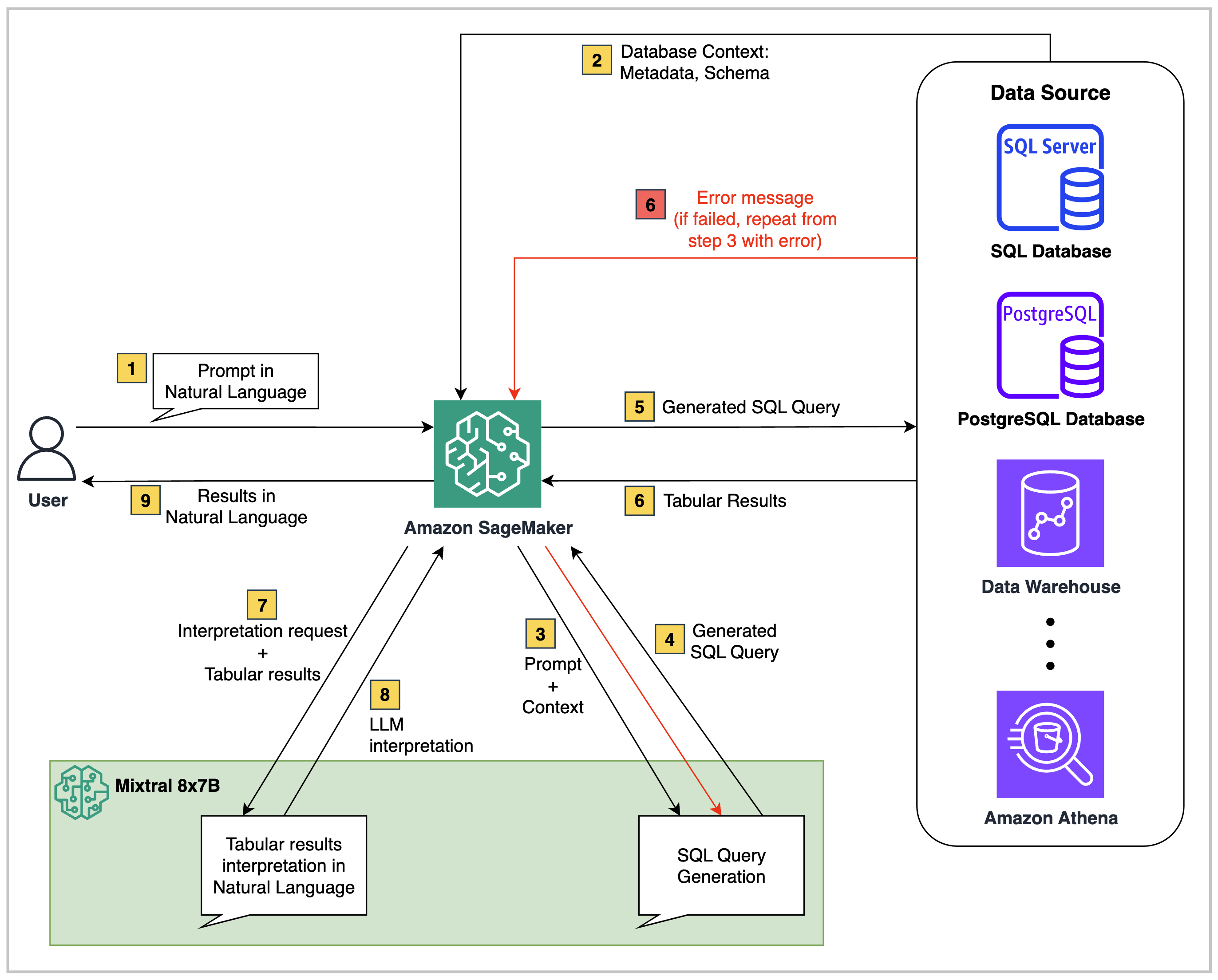
높은 수준 에서이 저장소의 것과 같은 Text2SQL 솔루션은 세 가지 핵심 구성 요소로 구성됩니다.
구조화 된 데이터 출처 : Amazon RDS, Amazon Aurora, AWS Athena 또는 Snowflake와 같은 관계형 데이터 소스 일 수 있습니다. 쿼리 할 비즈니스 데이터가 포함되어 있습니다.
기초 모델 : 소스 데이터베이스의 데이터 스키마를 이해하고 자연어 문제를 해당 SQL 쿼리에 매핑 할 수있는 LLM (Lange Language Model).
오케스트레이터 백엔드 : 코드 스크립트는 Sagemaker Studio Notebook, Lambda 기능, EC2 또는 ECS와 같은 환경에서 실행할 수 있습니다. 또한 필요한 경우 AWS 스텝 기능과 같은 오케스트레이션 서비스를 선택적으로 추가 할 수 있습니다.
이 저장소에 제공된 코드에서 아키텍처는 다음과 같습니다.
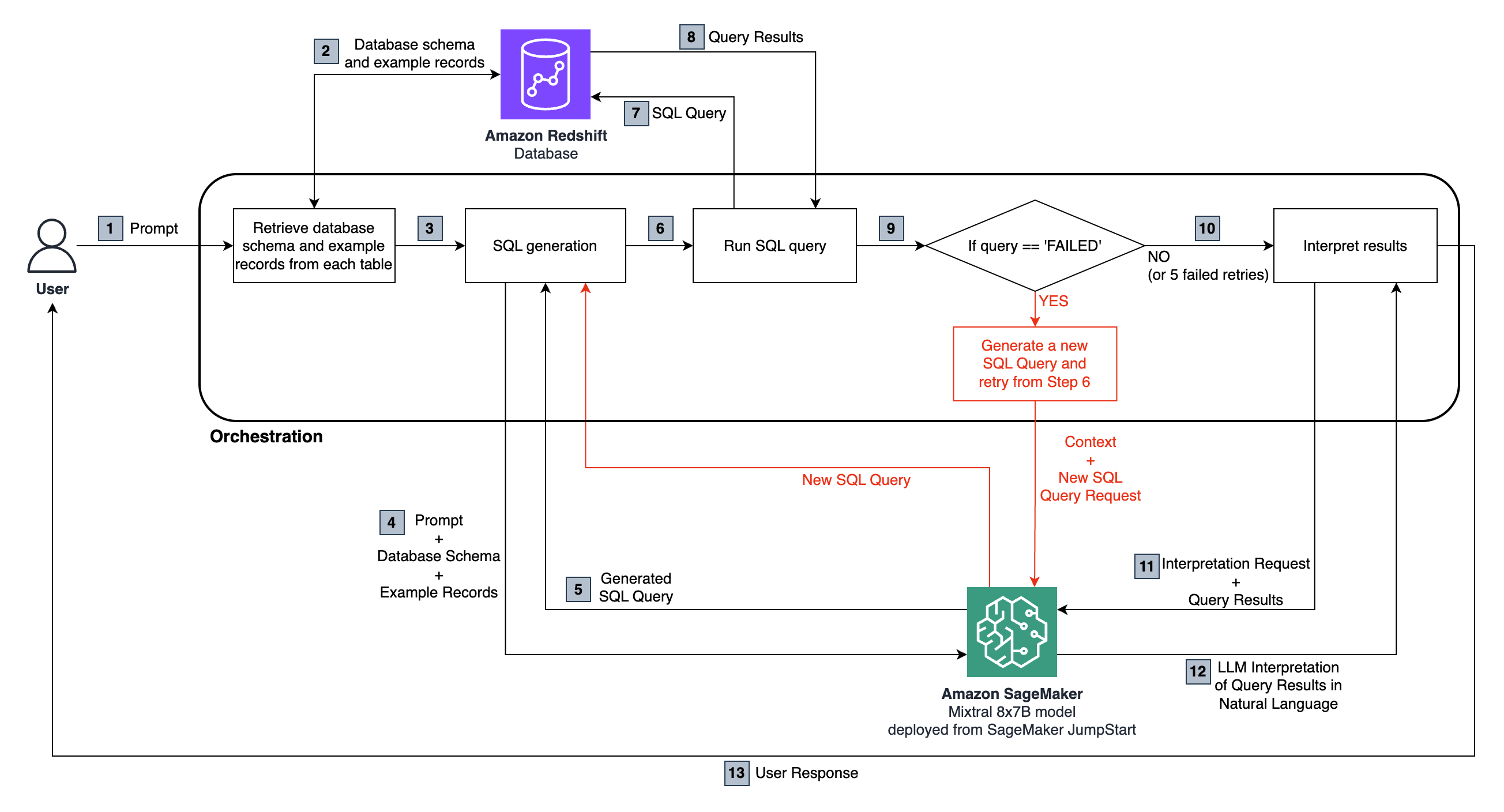
엔드 투 엔드 흐름은 다음과 같습니다.
사용자는 Sagemaker에서 주최 한 Mixtral 8x7b Instruct 모델로 전달되는 자연어 질문을합니다.
LLM은 질문을 분석하고 연결된 적색 편이 데이터베이스에서 가져온 스키마를 사용하여 SQL 쿼리를 생성합니다.
SQL 쿼리는 데이터베이스에 대해 실행됩니다. 오류의 경우 재시도 워크 플로가 실행됩니다.
수신 된 테이블 결과는 해석을 위해 LLM으로 다시 전달되어 사용자의 원래 질문에 대한 자연어 응답으로 전환됩니다.
구현의 단계별 연습을 보려면 참조 블로그 포스트를 확인하십시오.


