query databases with natural language
1.0.0
该项目使通过自然语言与关系数据库进行互动。具体而言,它使用专家(MOE)模型混合8x7b指令的稀疏混合物,生成SQL查询,并解释其相应的表格结果以返回用户作为答案。该应用程序利用SageMaker托管工具为模型提供服务,该工具可以从Sagemaker Jumpstart中单击几下部署。有关更多详细信息,请参阅此博客文章。
当前,您可以单击一键在SageMaker Jumpstart上部署Mixtral 8x7b。 Amazon Sagemaker Jumpstart提供了一种简化的方法,可以访问和部署100多种不同的开源和第三方基础模型。为了启动一个端点以从Sagemaker Jumpstart托管Mixtral 8x7b,您可能需要要求增加服务配额以访问ML.G5.48XLARGE实例以进行端点用法。您可以通过AWS控制台,CLI或API轻松地要求增加服务配额以访问。
您还需要访问关系数据源。 Amazon RedShift用Tickit数据库用作本文中的主要数据源。该数据库可帮助分析师跟踪虚构tick网站的销售活动,用户在线购买和出售门票以进行体育赛事,表演和音乐会。
请与您的法律团队一起查看适用于数据集的任何许可条款,并确认您的用例是否符合该条款。
如果您还没有一个,则首先需要设置一个红移集群。使用Amazon Redshift控制台或CLI来启动带有所需节点类型和节点数量的群集。确保注意群集端点,数据库名称和凭据连接。
群集可用后,在其中创建一个新的数据库和表以保存关系数据。您可以按照以下步骤从S3加载tickit数据库的数据。
为了测试您成功将数据添加到红移集群中。请按照以下步骤:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
如果您获得了成功的响应,则意味着您将数据库数据正确加载到集群上。查询编辑器允许保存,调度和共享查询。您还可以查看查询计划,执行详细信息和监视查询性能。
我们建议在Amazon Sagemaker Studio上运行此笔记本。为此,您必须首先设置一个SageMaker域,以确保它具有与Amazon Redshift互动的适当权限。然后,将此GitHub存储库克隆到Sagemaker Studio Classic中,并具有以下命令:
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
打开查询 - amazon-redshift-with-mixtral-8x7b-instruct.ipynb笔记本,以通过它运行。
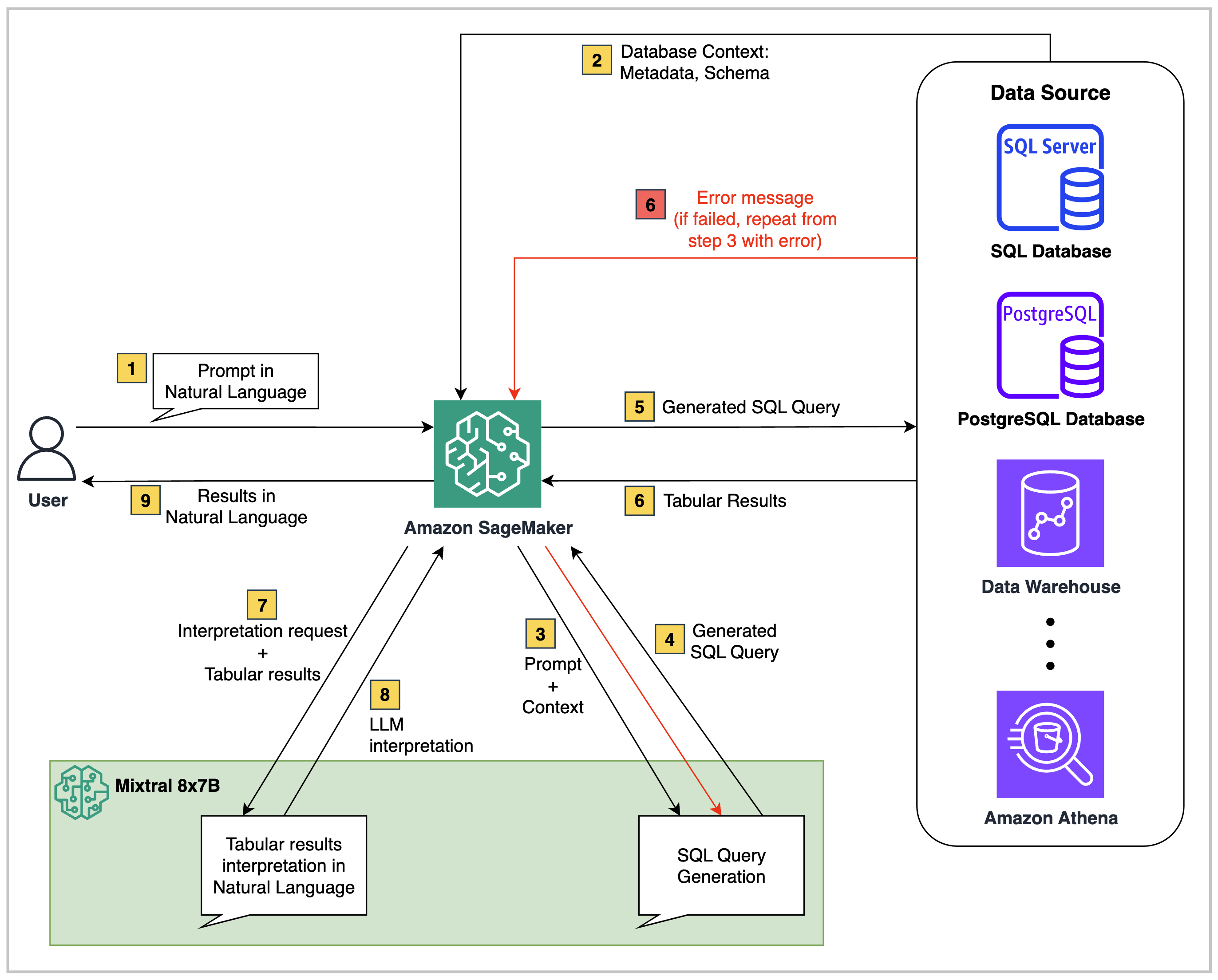
在高级别,Text2SQL解决方案(例如此存储库中的一个解决方案)由三个核心组成部分组成:
结构化数据源:这可以是任何关系数据源,例如Amazon RD,Amazon Aurora,AWS Athena或Snowflake。它包含要查询的业务数据。
基础模型:一个大型语言模型(LLM),能够理解源数据库的数据架构并将自然语言问题映射到相应的SQL查询中。
编目后端:代码脚本可以在诸如Sagemaker Studio笔记本,Lambda功能,EC2或EC等环境中执行。最重要的是,您可以选择添加编排服务,例如AWS步骤功能(如果需要)。
在此存储库中提供的代码中,架构如下:
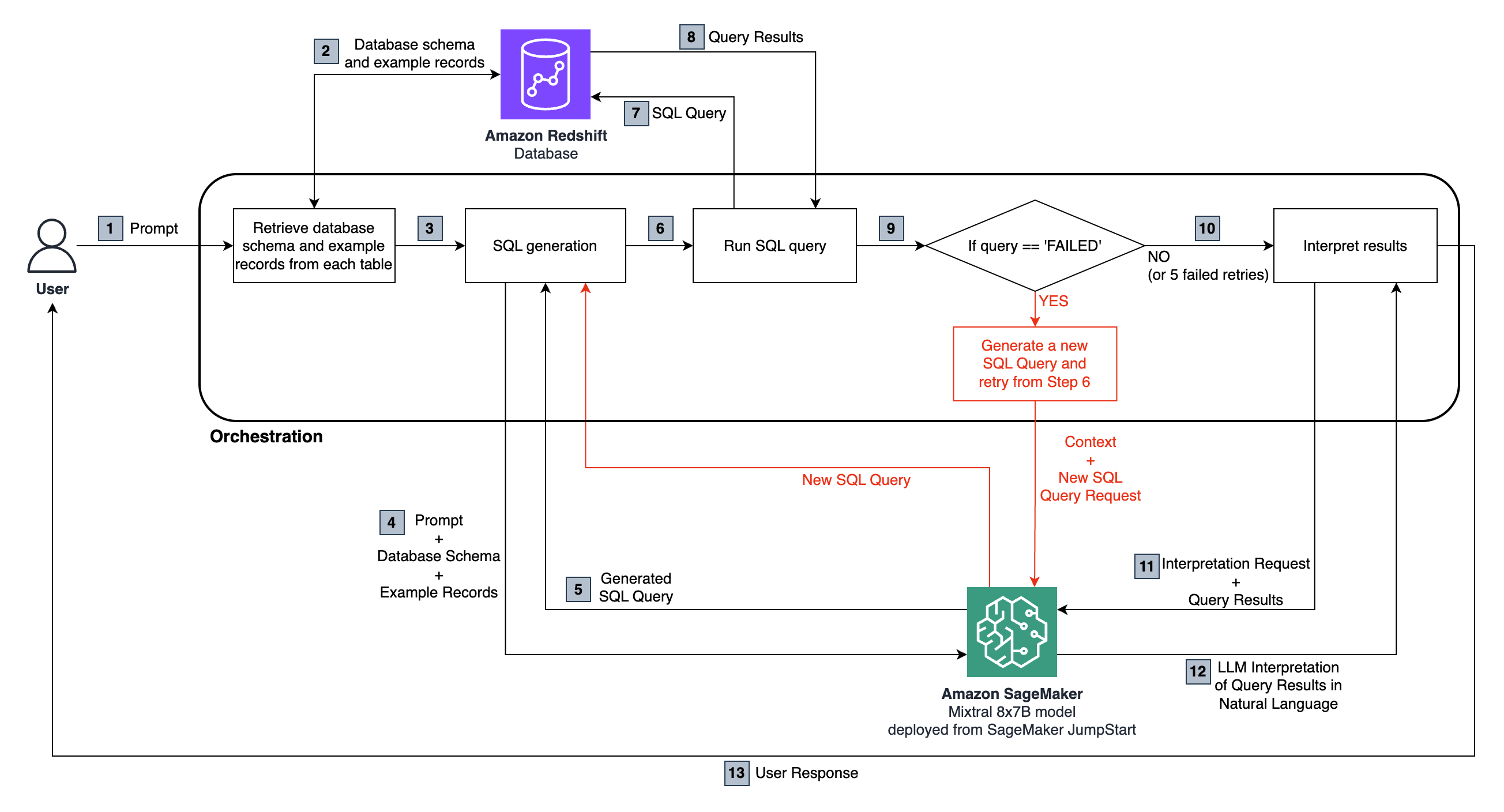
端到端流量如下:
用户提出了一个自然语言问题,该问题将传递给sagemaker托管的Mixtral 8x7b指令模型。
LLM分析问题并使用从连接的红移数据库中获取的架构来生成SQL查询。
SQL查询与数据库运行。如果发生错误,则执行重试工作流。
收到的表格结果将传递回LLM进行解释,并将其转换为用户原始问题的自然语言响应。
有关实施的逐步演练,请查看参考博客文章。


