query databases with natural language
1.0.0
Dieses Projekt ermöglicht die Interaktion mit relationalen Datenbanken durch natürliche Sprache. Insbesondere verwendet es die spärliche Mischung aus Experten (MOE) Model Mixtral 8x7b -Anweisungen für die Generierung von SQL -Abfragen und die Interpretation ihrer entsprechenden tabellarischen Ergebnisse, um zum Benutzer als Antworten zurückzukehren. Die Anwendung nutzt Sagemaker -Hosting -Tools, um das Modell zu bedienen, das mit einigen Klicks von Sagemaker Jumpstart bereitgestellt wird. Weitere Informationen finden Sie in diesem Blogpost.
Sie können derzeit MixTral 8x7b auf Sagemaker Jumpstart mit einem Klick bereitstellen. Der Amazon Sagemaker Jumpstart bietet eine vereinfachte Möglichkeit, über 100 verschiedene Open-Source- und Drittanbieter-Foundation-Modelle zuzugreifen und bereitzustellen. Um einen Endpunkt für das Host -Mixtral 8x7b von Sagemaker Jumpstart zu starten, müssen Sie möglicherweise eine Erhöhung der Servicequote anfordern, um auf eine Instanz von ML.G5.48XLARGE für die Endpunktverwendung zuzugreifen. Sie können problemlos die Servicekontingent -Erhöhungen über die AWS -Konsole, die CLI oder die API anfordern, um Zugriff zu erhalten.
Sie benötigen auch Zugriff auf eine relationale Datenquelle. Amazon RedShift wird in diesem Beitrag mit der Tickit -Datenbank als primäre Datenquelle verwendet. Diese Datenbank hilft den Analysten, Vertriebsaktivitäten für die fiktive Tickit -Website zu verfolgen, auf der Benutzer Tickets online für Sportveranstaltungen, Shows und Konzerte kaufen und verkaufen.
Bitte überprüfen Sie alle Lizenzbedingungen, die für den Datensatz mit Ihrem Rechtsteam gelten, und bestätigen Sie, dass Ihr Anwendungsfall vor dem Verfahren die Bedingungen entspricht.
Sie müssen zuerst einen Rotverschiebungscluster einrichten, wenn Sie noch keinen haben. Verwenden Sie die Amazon Redshift -Konsole oder -CLI, um einen Cluster mit dem gewünschten Knotentyp und der Anzahl der Knoten zu starten. Stellen Sie sicher, dass Sie den Cluster -Endpunkt, den Datenbanknamen und den Anmeldeinformationen herstellen.
Sobald der Cluster verfügbar ist, erstellen Sie eine neue Datenbank und Tabellen darin, um die relationalen Daten zu halten. Sie können Daten für die Tickit -Datenbank aus S3 aus diesen Schritten laden.
Um zu testen, ob Sie Ihren Redvershift -Cluster erfolgreich Daten hinzugefügt haben. Folgen Sie folgenden Schritten:
/* Find total sales on a given date. */
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
/* Find the top 10 buyers. */
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales GROUP BY buyerid
ORDER BY total_quantity
desc limit 10) Q, users
WHERE Q.buyerid = users.userid
ORDER BY Q.total_quantity desc;
Wenn Sie erfolgreiche Antworten erhalten, bedeutet dies, dass Sie die Datenbankdaten korrekt auf den Cluster geladen haben. Der Query -Editor ermöglicht das Speichern, Planen und Freigeben von Fragen. Sie können auch Abfragepläne, Ausführungsdetails anzeigen und die Abfrageleistung überwachen.
Wir empfehlen, dieses Notebook im Amazon Sagemaker Studio auszuführen. Dafür müssen Sie zuerst eine Sagemaker -Domain einrichten, um sicherzustellen, dass die entsprechenden Berechtigungen für die Interaktion mit Amazon Redvershift enthält. Dann klonen Sie dieses Github -Repository mit dem folgenden Befehl in den Sagemaker Studio Classic:
git clone https://github.com/aws-samples/query-databases-with-natural-language.git
Öffnen Sie die Abfrage-Amazon-Redshift-with-mixtral-8x7b-instruct.ipynb- Notizbuch, um es durchzuführen.
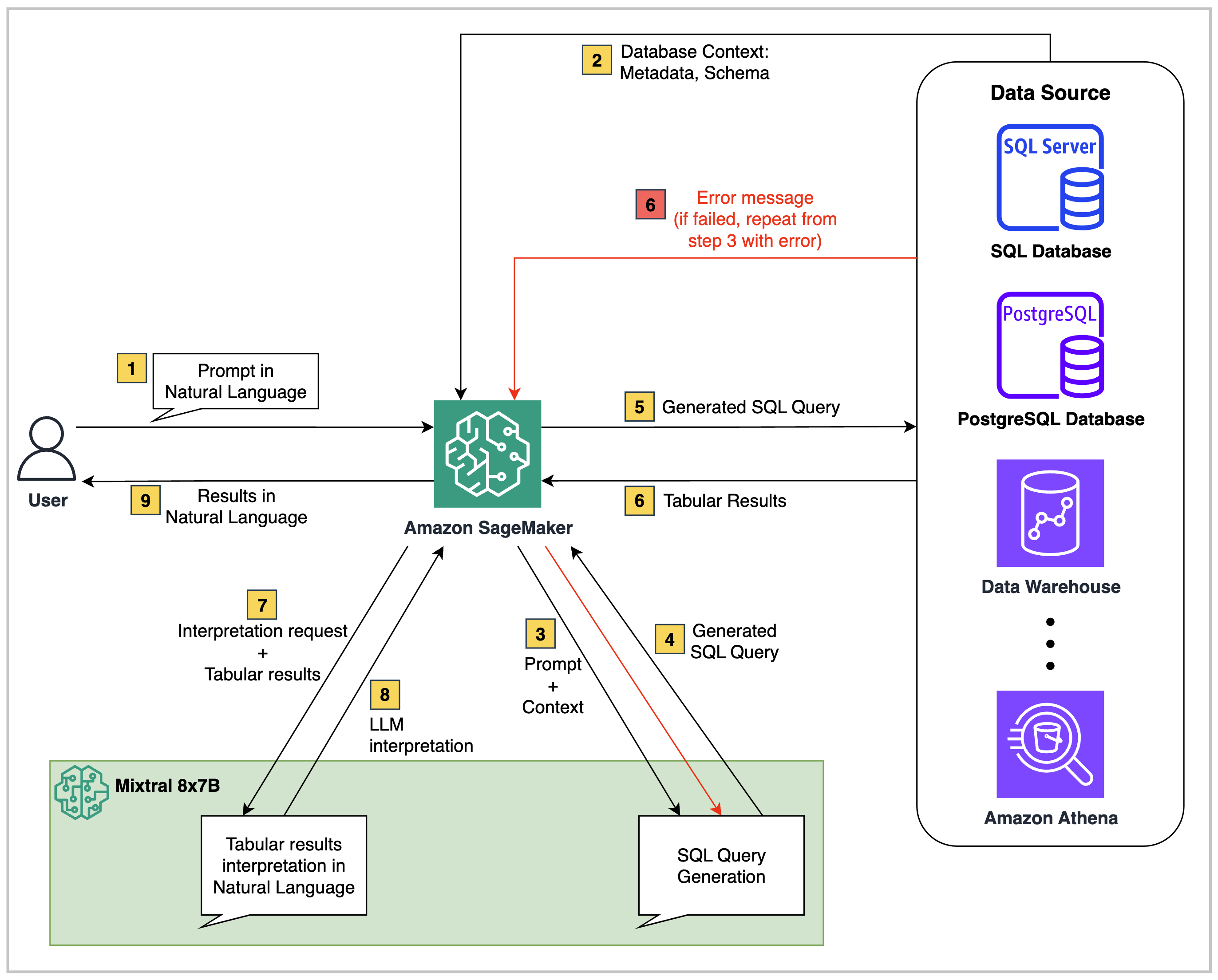
Auf hoher Ebene bestehen Text2SQL -Lösungen wie die in diesem Repository aus drei Kernkomponenten:
Strukturierte Datenquelle : Dies kann jede relationale Datenquelle wie Amazon RDS, Amazon Aurora, AWS Athena oder Snowflake sein. Es enthält die Geschäftsdaten, die abfragen.
Foundation -Modell : Ein großes Sprachmodell (LLM), das das Datenschema der Quelldatenbank verstehen und natürliche Sprachfragen in entsprechende SQL -Abfragen abbilden kann.
Orchestrator Back-End : Die Codeskripte können in Umgebungen wie einem Sagemaker Studio Notebook, einer Lambda-Funktion, EC2 oder ECS ausgeführt werden. Darüber hinaus können Sie bei Bedarf optional einen Orchestrierungsdienst wie AWS -Schrittfunktionen hinzufügen.
In dem in diesem Repository bereitgestellten Code ist die Architektur Folgendes:
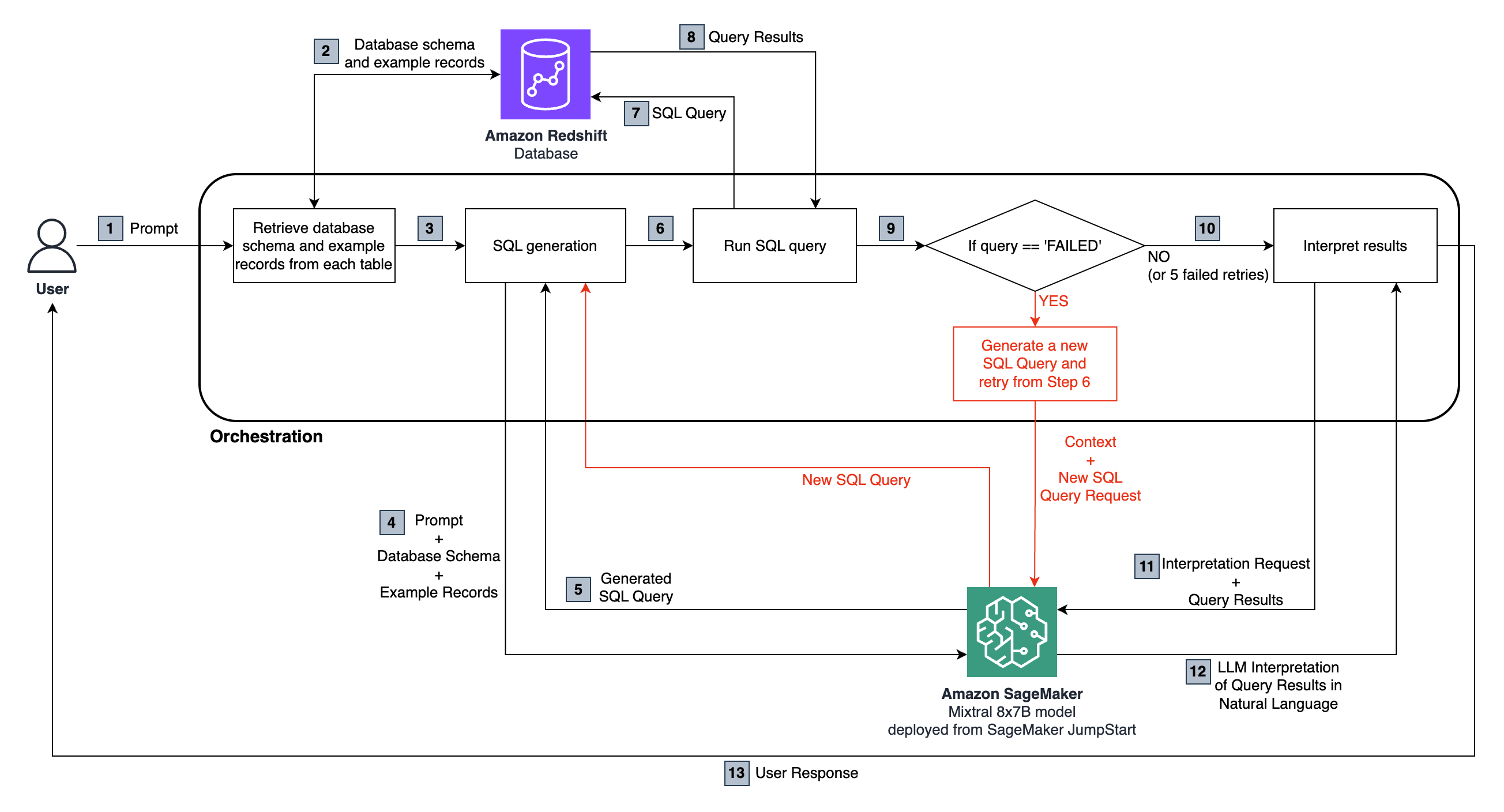
Der End-to-End-Fluss ist wie folgt:
Der Benutzer stellt eine natürliche Sprachfrage, die an das in Sagemaker gehostete Mixtral 8x7b -Anweisungsmodell übergeben wird.
Das LLM analysiert die Frage und verwendet das aus der angeschlossene Redvershift -Datenbank abgerufene Schema, um eine SQL -Abfrage zu generieren.
Die SQL -Abfrage wird mit der Datenbank ausgeführt. Bei einem Fehler wird ein Wiederholungs -Workflow ausgeführt.
Die empfangenen tabellarischen Ergebnisse werden zur Interpretation an die LLM zurückgegeben und sie in eine natürliche Sprachantwort auf die ursprüngliche Frage des Benutzers umgewandelt.
Für eine Schritt-für-Schritt-Durchführung der Implementierung finden Sie unter den Referenz-Blogpost.


