BabyGPT
1.0.0

BabyGpt以Karpathy的NG-Video讲座和Mingpt的直觉为基础,提供了GPT的工作模型,该模型在较小的规模上(256和16个Out通道,5层GPT,5层GPT,微调)。 BabyGpt是由一个Toygpt建造的,该玩具是从头开始了解变压器的。正如您将在下面看到的那样,它已被缩小。访问笔记本。我们从简单的语言模型,注意机制和最终BabyGpt的变压器扩展到变形金刚。虽然Toygpt是通过定量分离变压器的所有层来构建的。在BabyGpt中,注意机制是手动实施的。构建较小的GPT的目的是了解更精细的变压器功能。
要训练小型模型,我们正在使用微小的故事。您可以从拥抱脸上下载权重。我们将Max_iters设置为Tesla T4上的5000。对于OG模型,我们使用256个OUT通道。
| 模型 | 上下文长度 | n_layers | n_head | n_embd | 火车损失 | 瓦尔损失 | 参数 | 数据 |
|---|---|---|---|---|---|---|---|---|
| 15m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13k | 故事15m.bin |
| 42m | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1.01m | 故事42m.bin |
| Babygpt原始 | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 637万 | 数据 |
注意: - 目前正在省略110m。公羊炸毁了.. !!
如果您想了解变形金刚从头开始工作的烦恼,则此路线图将指导您。我们从实施简单的语言模型BigRam和ngram开始,然后从那里开始努力,直至构建变形金刚,从头开始,然后再用babygpt。
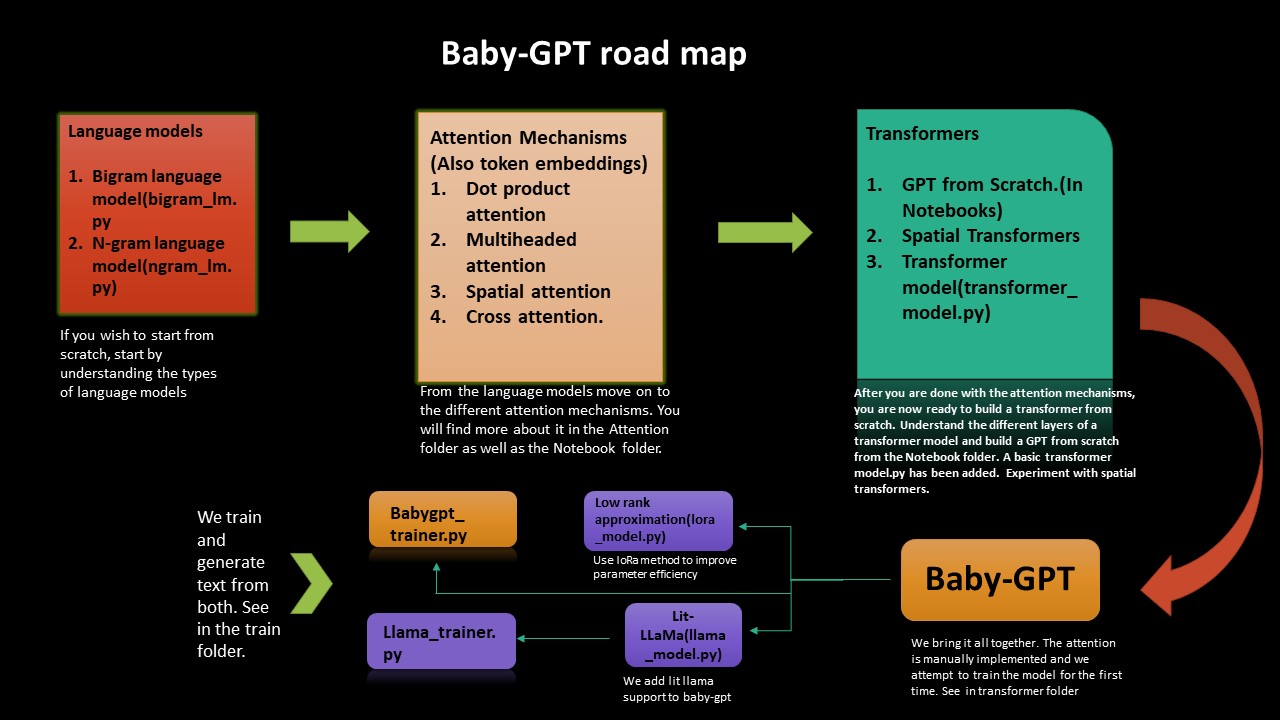
我们也实施了低级近似值以及对BabyGpt的LIT-LAMA。我们终于训练模型并生成令牌。
低等级近似提高了参数效率(压缩技术)。添加了一个lora_model.py(在256个频道上)。我们收到大约2的参数降低。一切,我们需要做的就是计算等级参数并相应地计算注意力。在Lora笔记本中,根据Chinchilla纸进行了拖鞋的估计。
量化也已在洛拉模型上进行。还添加了拖鞋的计算。对于256个频道的BabyGpt型号,我们将获得0.407 PETA拖鞋。在Lora笔记本中,我们添加了量化。就尺寸降低而言,我们目前的降低为1.3。
Lit-Lalama模型的插入已移植到BabyGpt(基于Llama-1版)。您可以在此处找到笔记本 - > llama_implementation。运行该模型,也添加了MFU。 llamapython llama_model_v1.py 。下面提供了培训和生成令牌。
注意: - 我们已端口build_rope_cache() , apply_rope()和RMSNorm()来自版本1。我们也不使用版本1权重或检查点(这些都适用于较大的型号7b,13b,65b等)。您可以将权重和旧羊毛拉玛下载到自己的版本中。
我们已经将Llama2通过Meta移植到Babygpt中。您可以在llamapython llama2.py上找到实现。我们还提供了与模型一起计算的拖鞋。
计算K,V缓存的拖鞋是要计算的拖船是:-2 * 2 * num_layers *(embedded_dim) ^2。在Kipply的博客MFU中查找有关如何计算内存和计算的更多信息已添加到Llama2
注意: - 我们不使用Meta的原始Llama重量。我们还为70B使用任意值。您可以使用自己的权重将其移植到自己的型号中。
已经完成了使用句子的令牌化。我们正在导出一个tokenizer.bin 。在llamapython tokenizer.py中运行它(添加了元件)。我们可以使用.bin文件进行进一步推断。
我们需要有效的LLMS内存使用量。硬件加速器使用一种称为硬件翻牌用途的技术,用于在内存使用和计算之间有效折衷。这通常是使用在给定设备上观察到的触发器与其理论峰值拖失lop的比率进行的。 MFU是观察到的吞吐量(每秒标记)的比率,相对于在峰值触发器上运行的系统的理论最大吞吐量。特斯拉T4的理论峰值矩阵约为8.1 tflops。因此,我们计算了Llama Trainer模型的MFU。请参阅在骆驼训练下的教练笔记本上。我们将获得322万参数的MFU:0.0527723427%。当然,随着参数数量的增加,这当然会增加。对于530b参数模型,A100 GPU的MPU约为30%。我们使用棕榈纸的B节进行参考。
LLM需要许多GPU才能运行,我们需要找到减少这些要求的方法,同时保留模型的性能。已经开发了试图缩小模型大小的各种技术,您可能已经听说过量化和蒸馏。已经发现,我们可以使用2字节BF16/FP16半精度获得几乎相同的推理结果,而不是使用4字节FP32精度,将模型大小减半。
为了补充这一点,引入了8位量化。该方法使用四分之一的精度,因此仅需要模型大小的1/4!但这不是仅仅掉下一半的碎片就可以做到了。这个主题还有很多。看拥抱面部量化。
您可以看到有关如何执行骆驼定量化的量子。您可以查看初学者量化介绍的量化笔记本。已经完成了不同的基准测试。对于EX: - 在GPU上,BFLOAT16上的7B参数模型将大约需要15GB。 BabyGpt将花费大约几千字节.. !!! quantization.py已从lit-lalama repo获得。还添加了使用句子的令牌。可以从Tokenizer.Model执行不同的重量操作
对于培训后的量化,我们能够将模型大小降低几乎4倍。
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
注意:仅用于量化,我们使用的是一个大约322万参数的较大模型
BabyGptModel和量化模型已经完成了性能基准测试。以下是结果。
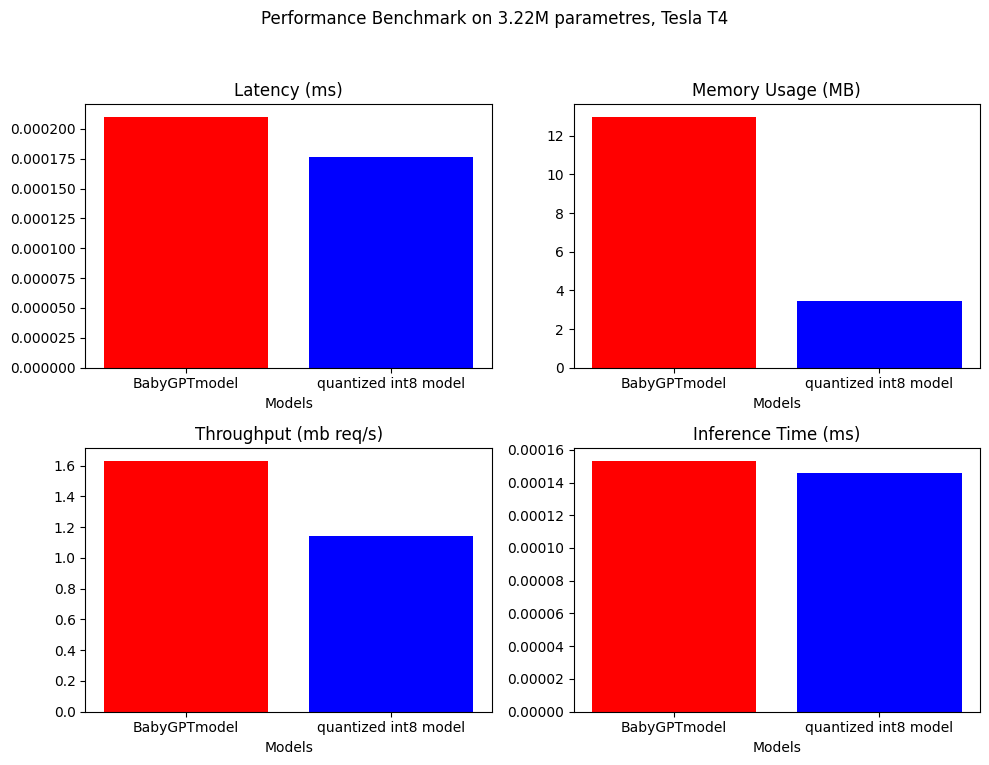 。
。
它已被添加到量子文件夹中的量化笔记本上。
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
克隆回购并运行以下内容:
! git clone https://github.com/soumyadip1995/BabyGPT.git
运行Bigram和Ngram语言模型。 python bigram_lm.py和python ngram_lm.py 。
运行来自变形金刚文件夹的babygpt transformerspython babygpt.py 。
运行简单的变压器模型python transformer_model.py
运行低级近似模型python LoRa_model.py
运行Llama Model llamapython llama_model_v1.py
运行Llama2 llamapython llama2.py
从注意文件夹中运行不同的注意机制。
已经添加了非常初步的自动混合精度。 fp16/fp32可以通过启用CUDA的GPU来实现。 Pytorch的autocast()和gradscalar()的组合用于混合精度。在Pytorch教程中查看更多内容。不幸的是,GPU在培训期间爆炸了,而CPU现在只支持BFLOAT16。需要很长时间的训练。如果有人能改善它,那就太棒了。检查混合精密笔记本。
如果您想开始使用BabyGpt和Llama,但不想经历有关Transformer型号的所有了解的所有麻烦,则可以简单地从火车文件夹中运行代码开始。
训练和生成Babygpt模型和Llama模型的文本。运行trainpython babygpt_trainer.py和trainpython llama_trainer.py从火车文件夹中。
两者都接受了Tesla T4 GPU的培训。您可以根据自己的意愿增加或降低max_iters的值。需要几分钟才能训练。
您可以在教练笔记本中看到两个模型的结果。
参数= 3.22 m
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
似乎该模型在末尾有点收敛。也许这将需要更多的修改。吐一些eminem哟..:微笑:
数据文件夹包含文本文档,该文本具有歌词,其中包括Eminem的所有歌曲。
| 笔记本 | 描述 |
|---|---|
| 点产品的关注 | COLAB |
| 多重注意 | COLAB |
| GPT从头开始 | COLAB(约860K参数) |
| 空间变压器 | COLAB |
| babygpt | COLAB(16,256频道) |
| 洛拉 | COLAB(256个频道) |
| babygpt的lit-lalama | COLAB(Lit-lalama的16个频道) |
| Babygpt和Llama的培训师 | COLAB(Babygpt的16个频道,256个淡紫色的频道) |
text.txt基于Eminem的Stan。
许可已更新为包括Facebook Research/Llama,Lit-Lalama和IST-DAS实验室,您可以在GNU,Apache和MIT下使用它。


