BabyGPT
1.0.0

Sobre la base de la intuición de las conferencias de video Ng de Karpathy y Mingpt, BabyGPT proporciona un modelo de trabajo de un GPT en una escala mucho más pequeña (256 y 16 canales de salida, 5 capas GPT, ajustados). BabyGPT se ha construido a partir de un ToyGPT que fue hecho para comprender los transformadores desde cero. Se ha reducido, como verá a continuación. Visite los cuadernos. Escala hasta transformadores de modelos de lenguaje simples, mecanismos de atención y finalmente babygpt. Mientras que ToyGPT se ha construido separando todas las capas de un transformador individamente. En BabyGPT, el mecanismo de atención se implementa manualmente. El propósito de construir GPTs más pequeños es comprender las funciones del transformador a un nivel mucho más granular.
Para capacitar a modelos pequeños estamos utilizando pequeñas historias. Puede descargar los pesos de abrazar la cara. Estamos configurando max_iters en 5000 en un Tesla T4. Para el modelo OG, estamos utilizando 256 canales de salida.
| modelo | longitud de contexto | N_LAYERS | n_head | N_EMBD | pérdida de tren | pérdida de val | parametres | datos |
|---|---|---|---|---|---|---|---|---|
| 15m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13k | historias15m.bin |
| 42m | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1.01m | historias42m.bin |
| Babygpt original | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6.37m | datos |
Nota:- Los 110m se omiten por ahora. El carnero explotó .. !!
Si desea comprender el arenoso de cómo funcionan los transformadores desde cero, esta hoja de ruta lo guiará. Comenzamos desde la implementación de modelos de idiomas simples Bigram y Ngram y luego desde allí avanzamos hasta construir transformadores, un GPT desde cero y finalmente babygpt.
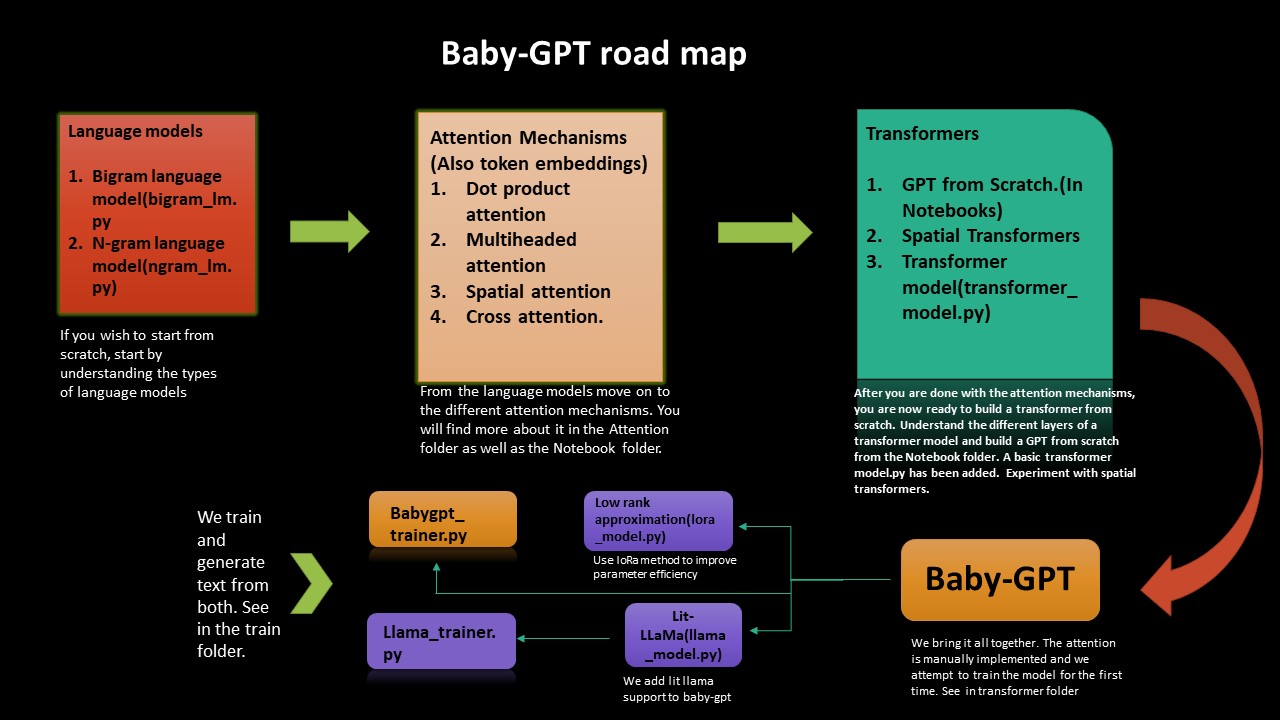
Implementamos una aproximación de bajo rango, así como también lit-lama a babygpt. Finalmente entrenamos los modelos y generamos tokens.
La aproximación de bajo rango mejora la eficiencia de parámetros (técnica de compresión). Se ha agregado un lora_model.py (en 256 canales de salida). Recibimos una reducción de parámetros de aproximadamente 2. Todo, debemos hacer es calcular un parámetro de rango y calcular la atención en consecuencia. En el cuaderno de Lora, se ha realizado una estimación de Flops según el papel de Chinchilla.
La cuantización también se ha realizado en el modelo Lora. También se ha agregado un cálculo de flops. Para el modelo BabyGPT para 256 canales de salida obtenemos 0.407 Flops PETA. En el cuaderno de Lora hemos agregado la cuantización. En términos de reducción del tamaño, estamos obteniendo una reducción de un factor de 1.3 por ahora.
Una implementación del modelo Lit-Llama se ha portado a BabyGPT (basado en Llama- versión 1). Puede encontrar el cuaderno aquí -> Llama_implementation. Ejecute el modelo, también se ha agregado MFU. llamapython llama_model_v1.py . La capacitación y la generación de tokens se han proporcionado a continuación.
NOTA:- Hemos portado build_rope_cache() , apply_rope() y RMSNorm() de la versión 1. Tampoco estamos utilizando los pesos o los puntos de control de la versión 1 (estos son para modelos aún más grandes 7b, 13b, 65b, etc.). Puede descargar las pesas y el puerto a su propia versión.
Hemos portado Llama2 por Meta en Babygpt. Puede encontrar la implementación en llamapython llama2.py . También hemos proporcionado un cálculo de flops junto con el modelo.
Los fracasos para calcular k, v caché son los fracasos para calcular es:- 2 * 2 * num_layers * (incredded_dim) ^2. Encuentre más información sobre cómo calcular la memoria y calcular en la MFU del blog de Kiply se ha agregado a LLAMA2
Nota:- No estamos usando pesos de llamas originales de Meta. También estamos usando valores arbitrarios para 70B. Puede transferirlo a su propio modelo usando sus propios pesos.
Se ha realizado tokenización utilizando la pieza de oración. Estamos exportando un tokenizer.bin A diferencia del tokenizador de la carpeta cuant. Ejecutarlo en llamapython tokenizer.py (meta-piezas agregadas). Podemos usar el archivo .bin para una inferencia adicional.
Necesitamos un uso eficiente de memoria para LLM. Los aceleradores de hardware utilizan una técnica llamada utilización de flop de hardware para compensaciones eficientes entre el uso de la memoria y el cómputo. Esto generalmente se realiza utilizando una estimación de la relación de flops observados en un dispositivo dado a sus flops pico teóricos. MFU es la relación del rendimiento observado (tokens por segundo), en relación con el rendimiento máximo teórico de un sistema que funciona en los flops máximos. El pico teórico Matmul de Tesla T4 es de alrededor de 8.1 Tflops. Por lo tanto, calculamos la MFU del modelo de entrenador de llamas. Ver en el cuaderno de entrenador bajo el entrenador de llamas. Recibimos una MFU de: 0.0527723427% en parametres de 3.22m. Por supuesto, esto aumentaría a medida que aumente el número de parametras. Para un modelo de parámetros 530B, MPU es de alrededor del 30% en las GPU A100. Usamos la sección B del papel de palma para referencia.
Las LLM requieren que se ejecute muchas GPU, necesitamos encontrar formas de reducir estos requisitos al tiempo que preservamos el rendimiento del modelo. Se han desarrollado varias tecnologías que intentan reducir el tamaño del modelo, es posible que haya oído hablar de cuantificación y destilación. Se ha descubierto que, en lugar de usar la precisión FP32 de 4 bytes, podemos obtener un resultado de inferencia casi idéntico con la medios precisión de 2 bytes BF16/FP16, que reduce a la mitad el tamaño del modelo.
Para remediar eso, se introdujo la cuantización de 8 bits. ¡Este método utiliza un cuarto de precisión, lo que necesita solo 1/4 del tamaño del modelo! Pero no se hace simplemente dejando caer otra mitad de los bits. Hay mucho más en este tema. Mira la cuantización de la cara abrazada.
Puede ver Quant.md sobre cómo realizar la quantización de Llama. Puede considerar el cuaderno de cuantización para una introducción para principiantes a la cuantización. Se han realizado diferentes evaluaciones de evaluación comparativa. Para Ex:- En una GPU, el modelo de parámetros 7B en BFLOAT16 tomará aproximadamente 15 GB. Babygpt tomará alrededor de unos pocos kilobytes .. !!! quantization.py se ha obtenido del repositorio de Lit-Llama. También se ha agregado un tokenizador que usa una pieza de oración. Diferentes tipos de operaciones de peso se pueden realizar desde el tokenizer.model
Para la cuantificación posterior al entrenamiento, podemos reducir el tamaño del modelo en un factor de casi 4.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
Nota: Solo para la cuantificación estamos utilizando un modelo más grande con unos 3.22 millones de parámetros
La evaluación comparativa de rendimiento se ha realizado en el BabyPptModel y el modelo cuantificado. A continuación están los resultados.
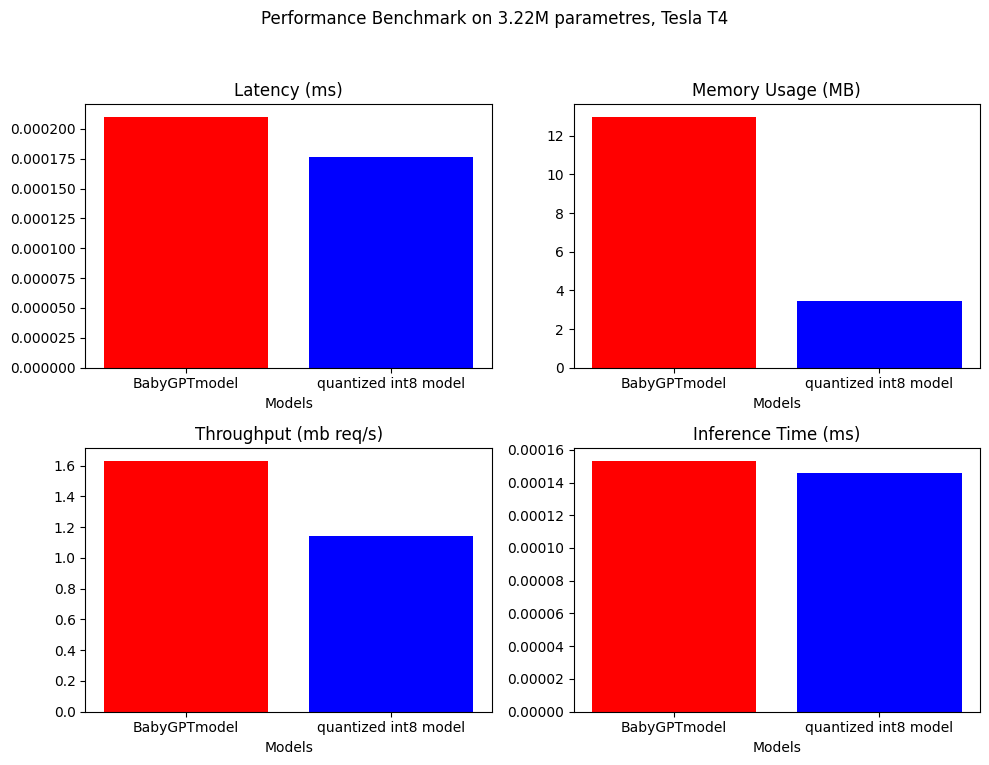 .
.
Se ha agregado al cuaderno de cuantización en la carpeta Quant.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
Clonar el repositorio y ejecutar lo siguiente:
! git clone https://github.com/soumyadip1995/BabyGPT.git
Para ejecutar los modelos de idiomas BigRam y Ngram. python bigram_lm.py y python ngram_lm.py .
Para ejecutar Babygpt transformerspython babygpt.py de la carpeta Transformers.
Para ejecutar un modelo de transformador simple python transformer_model.py
Para ejecutar un modelo de aproximación de bajo rango python LoRa_model.py
Para ejecutar el Llama Model llamapython llama_model_v1.py
Run Llama2 llamapython llama2.py
Ejecute los diferentes mecanismos de atención desde la carpeta de atención.
Se ha agregado una precisión auto mixta muy preliminar. FP16/FP32 Se puede lograr con una GPU habilitada para CUDA. Se usa una combinación de autocast() y gradscalar() de Pytorch para la precisión mixta. Ver más en el tutorial de Pytorch. Desafortunadamente, la GPU explotó durante el entrenamiento y la CPU por ahora solo admite BFLOAT16. Toma mucho tiempo para entrenar. Si alguien puede mejorarlo, sería increíble. Verifique el cuaderno de precisión mixto.
Si desea comenzar en BabyGPT y Llama, pero no desea pasar por toda la molestia de saber todo sobre los modelos de transformadores, simplemente puede comenzar ejecutando el código desde la carpeta del tren.
Para entrenar y generar texto tanto del modelo BabyGPT como del modelo LLAMA. Ejecute trainpython babygpt_trainer.py y trainpython llama_trainer.py desde la carpeta del tren.
Ambos han sido entrenados en las GPU de Tesla T4. Puede aumentar o disminuir los valores de Max_iters de acuerdo con su deseo. Tarda unos minutos para entrenar.
Puede ver el resultado de ambos modelos en el cuaderno de entrenador.
Número de parámetros = 3.22 m
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
Parece que el modelo converge un poco temprano, hacia el final. Tal vez eso necesite más modificación. Escupir un poco de eminem yo ..: sonrisa:
La carpeta de datos contiene el documento de texto que tiene la letra de todas las canciones de Eminem.
| Computadora portátil | Descripción |
|---|---|
| Atención del producto Dot | colab |
| Atención múltiple | colab |
| GPT desde cero | colab (aproximadamente 860k parametres) |
| Transformadores espaciales | colab |
| Babygpt | Colab (16, 256 canales de salida) |
| Lora | Colab (256 canales de salida) |
| Lit-llama para babygpt | Colab (16 canales para Lit-Llama) |
| Trainer para Babygpt y Llama | Colab (16 canales de salida para BabyGPT, 256 canales de salida para LLAMA) |
text.txt se basa en el Stan de Eminem.
Las licencias se han actualizado para incluir FacebookResearch/Llama, Lit-Llama y IST-DAS Lab, puede usarlo en GNU, Apache y MIT.


