BabyGPT
1.0.0

Babygpt baut auf der Intuition der NG-Video-Lecturen und Mingpts von Karpathy auf und bietet ein Arbeitsmodell eines GPT in einem viel kleineren Maßstab (256 sowie 16 Out-Kanäle, 5-Layer-GPT, Feinabstimmung). Babygpt wurde aus einem Toygpt gebaut, das Transformers von Grund auf neu verstanden wurde. Es wurde verkleinert, wie Sie unten sehen werden. Besuchen Sie die Notizbücher. Wir skalieren auf Transformatoren aus einfachen Sprachmodellen, Aufmerksamkeitsmechanismen und schließlich Babygpt. Während Toygpt durch Trennung aller Schichten eines Transformators indiviuell gebaut wurde. In BabyGPT wird der Aufmerksamkeitsmechanismus manuell implementiert. Der Zweck des Aufbaus kleinerer GPTs besteht darin, die Transformatorfunktionen auf einer viel detaillierteren Ebene zu verstehen.
Um kleine Modelle zu trainieren, verwenden wir Winzertorien. Sie können die Gewichte vom Umarmungsgesicht herunterladen. Wir setzen max_iters auf 5000 auf einem Tesla T4 ein. Für das OG -Modell verwenden wir 256 Out -Kanäle.
| Modell | Kontextlänge | n_layers | n_head | n_embd | Zugverlust | Valverlust | Parameter | Daten |
|---|---|---|---|---|---|---|---|---|
| 15 m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13k | Stories15m.bin |
| 42 m | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1,01 m | Stories42M.bin |
| Babygpt Original | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6,37 m | Daten |
Hinweis:- Die 110 m wird vorerst weggelassen. Der Widder blies in die Luft .. !!
Wenn Sie die düstere Art und Weise verstehen möchten, wie Transformatoren von Grund auf neu arbeiten, wird Sie diese Roadmap leiten. Wir beginnen mit der Implementierung einfacher Sprachmodelle Bigram und Ngram und arbeiten uns dann von dort zum Aufbau von Transformers, einem GPT von Grund auf und schließlich Babygpt.
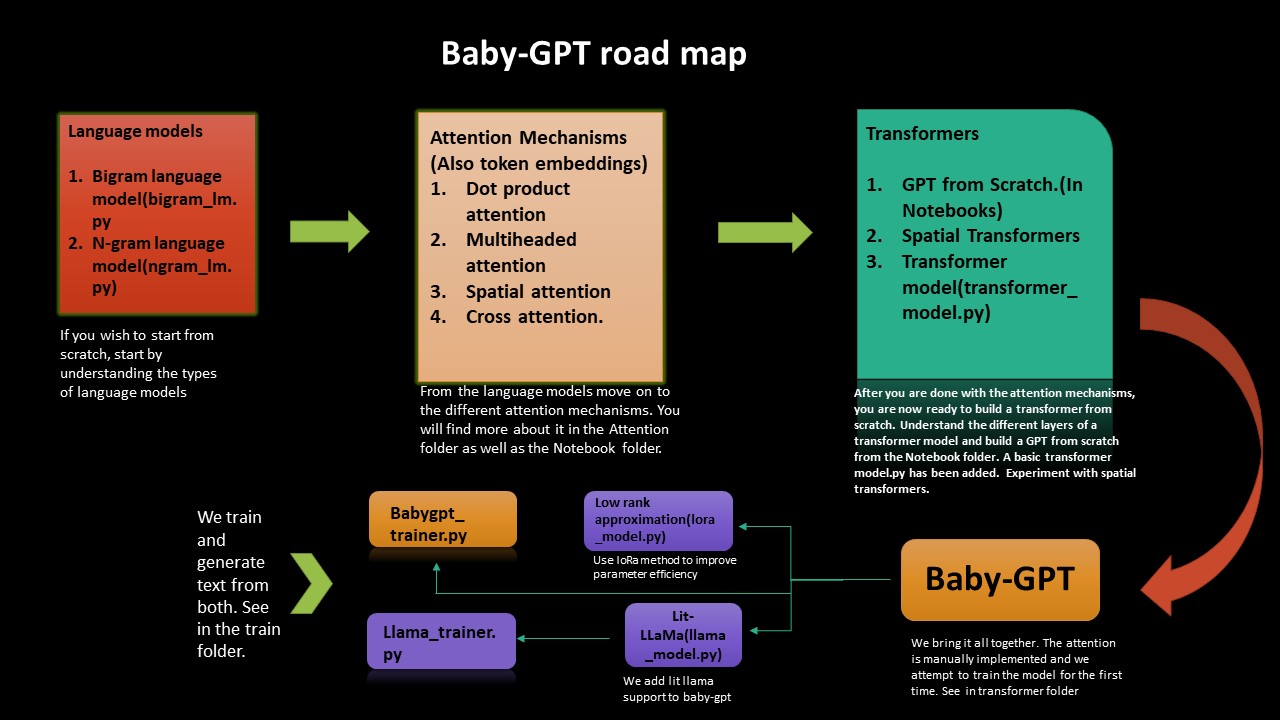
Wir führen auch eine Niedrigrangannäherung sowie ein Lit-Lama für BabyGPT durch. Wir trainieren endlich die Modelle und generieren Token.
Niedrigrangige Näherung verbessert die Parameter -Effizienz (Kompressionstechnik). Ein lora_model.py wurde hinzugefügt (auf 256 Kanälen). Wir erhalten eine Parameterreduzierung von etwa 2. Alles, wir müssen einen Rangparameter berechnen und die Aufmerksamkeit entsprechend berechnen. Im Lora -Notebook wurde nach dem Chinchilla -Papier eine Schätzung der Flops durchgeführt.
Die Quantisierung wurde auch am LORA -Modell durchgeführt. Eine Berechnung von Flops wurde ebenfalls hinzugefügt. Für das BabyGPT -Modell für 256 Out -Kanäle erhalten wir 0,407 PETA -Flops. Im Lora -Notizbuch haben wir die Quantisierung hinzugefügt. In Bezug auf die Größenreduzierung erhalten wir vorerst eine Reduzierung von 1,3 Faktor.
Eine Implemetation des Lit-Llama-Modells wurde auf BabyGPT portiert (basierend auf Lama-Version 1). Hier finden Sie das Notebook -> llama_implementation. Führen Sie das Modell aus, MFU wurde ebenfalls hinzugefügt. llamapython llama_model_v1.py . Das Training und die Generierung von Token wurde unten angeboten.
HINWEIS:- Wir haben build_rope_cache() , apply_rope() und RMSNorm() aus Version 1 portiert. Wir verwenden auch keine Gewichte oder Kontrollpunkte von Version 1 (diese sind für noch größere Modelle 7B, 13B, 65B usw.). Sie können die Gewichte und das Port Lama in Ihre eigene Version herunterladen.
Wir haben LLAMA2 von Meta in babygpt portiert. Sie finden die Implementierung bei llamapython llama2.py . Wir haben auch eine Berechnung von Flops zusammen mit dem Modell bereitgestellt.
Die Flops zum Berechnen von k, V-Cache sind die Flops, die zu berechnen sind, ist:- 2 * 2 * num_layers * (eingebettete) ^2. Weitere Informationen zum Berechnen von Speicher und Berechnung in Kiplys Blog MFU wurde zu LAMA22 hinzugefügt
Hinweis:- Wir verwenden keine originalen Lama-Gewichte von Meta. Wir verwenden auch beliebige Werte für 70B. Sie können es mit Ihren eigenen Gewichten auf Ihr eigenes Modell portieren.
Die Tokenisierung mit Satzstück wurde durchgeführt. Wir exportieren einen tokenizer.bin . Führen Sie es in llamapython tokenizer.py (Meta-Stücke hinzu). Wir können die .bin -Datei für weitere Schlussfolgerungen verwenden.
Wir brauchen eine effiziente Speicherverwendung für LLMs. Hardwarebeschleuniger verwenden eine Technik, die als Hardware-Flop-Auslastung bezeichnet wird, um effiziente Kompromisse zwischen Speicherverbrauch und Berechnung zu erhalten. Dies erfolgt typischerweise unter Verwendung einer Schätzung des Verhältnisses von Flops, die auf einem gegebenen Gerät zu seinen theoretischen Peak -Flops beobachtet wurden. MFU ist das Verhältnis des beobachteten Durchsatzes (Token-per-Sekunden) im Vergleich zum theoretischen maximalen Durchsatz eines Systems, das bei Spitzenflops arbeitet. Der theoretische Matmul von Tesla T4 liegt bei 8,1 Tflops. Daher berechnen wir die MFU des Lama -Trainermodells. Siehe im Trainer Notebook unter Lama-Trainer. Wir erhalten eine MFU von: 0,0527723427% bei 3,22 m -Parametern. Dies würde natürlich zunehmen, wenn die Anzahl der Parameter zunimmt. Für ein 530B -Parametermodell liegt MPU bei A100 GPU bei etwa 30%. Wir verwenden Abschnitt B aus dem Palmpapier als Referenz.
LLMs erfordern viele GPUs. Wir müssen Wege finden, um diese Anforderungen zu reduzieren und gleichzeitig die Leistung des Modells zu erhalten. Es wurden verschiedene Technologien entwickelt, die versuchen, die Modellgröße zu verkleinern. Möglicherweise haben Sie von Quantisierung und Destillation gehört. Es wurde festgestellt, dass wir anstatt die 4-Byte-FP32-Präzision zu verwenden, mit 2-Byte-BF16/FP16-Halbprezision ein nahezu identisches Inferenzergebnis erzielen können, das die Modellgröße halbiert.
Um das zu beheben, wurde eine 8-Bit-Quantisierung eingeführt. Diese Methode verwendet eine Viertelpräzision und benötigt daher nur 1/4 der Modellgröße! Aber es ist nicht getan, indem es nur eine weitere Hälfte der Teile fallen lässt. Dieses Thema hat noch viel mehr. Schauen Sie sich die Umarmung der Gesichtsquantisierung an.
Sie können quant.md sehen, wie man Lama-Quantisierung durchführt. Sie können das Quantization Notebook für eine Einführung eines Anfängers in die Quantisierung betrachten. Es wurden verschiedene Benchmarkings durchgeführt. Zum Beispiel:- Bei einer GPU dauert das 7B-Parametermodell auf BFLOAT16 etwa 15 GB. Babygpt wird ungefähr ein paar Kilobyten dauern .. !!! quantization.py wurde aus lit-llama repo erhalten. Ein Tokenizer mit Satzstück wurde ebenfalls hinzugefügt. Aus dem Tokenizer können unterschiedliche Arten von Gewichtsoperationen durchgeführt werden.
Für die Quantisierung nach dem Training können wir die Modellgröße um einen Faktor von fast 4 reduzieren.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
Hinweis: Nur zur Quantisierung verwenden wir ein größeres Modell mit ca. 3,22 m Paramtres
Das Leistungsbenchmarking wurde am Babygptmodel und dem quantisierten Modell durchgeführt. Nachfolgend finden Sie die Ergebnisse.
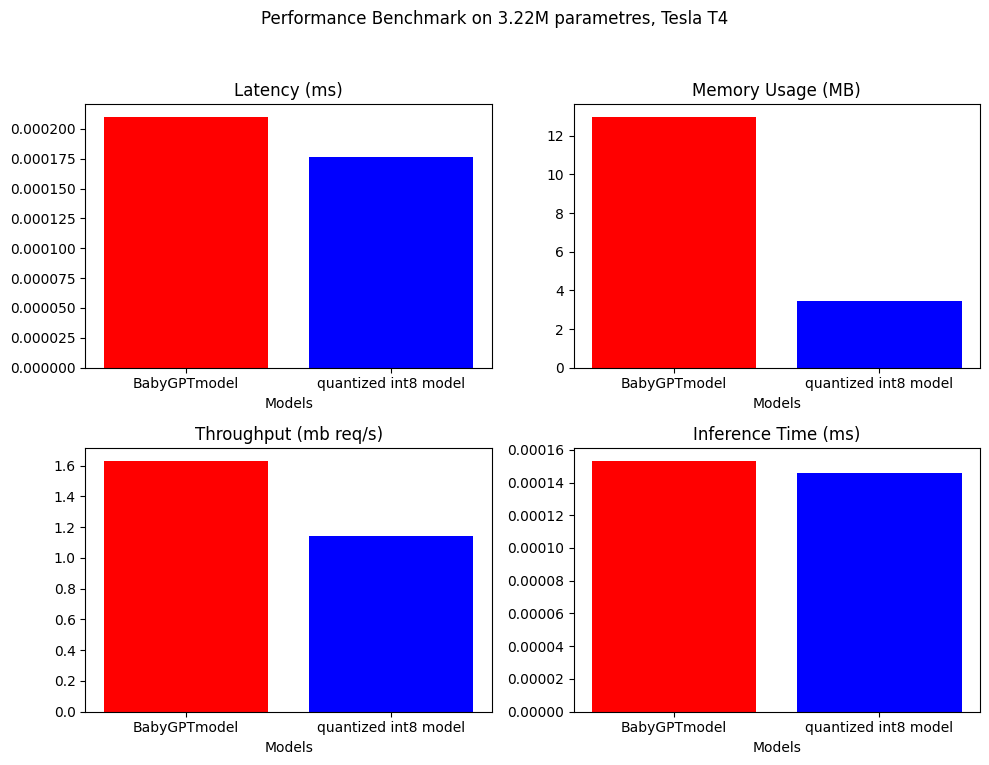 .
.
Es wurde dem Quantisierungs -Notebook im Quant -Ordner hinzugefügt.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
Klonen Sie das Repo und führen Sie Folgendes aus:
! git clone https://github.com/soumyadip1995/BabyGPT.git
Um die Bigram- und Ngram -Sprachmodelle zu führen. python bigram_lm.py und python ngram_lm.py .
Babygpt transformerspython babygpt.py aus dem Ordner Transformers.
So führen Sie ein einfaches Transformatormodell python transformer_model.py aus
Ein niedriger Rangnähermodell python LoRa_model.py ausführen
Das Lama -Modell llamapython llama_model_v1.py leiten
LLAMA2 llamapython llama2.py
Führen Sie die unterschiedlichen Aufmerksamkeitsmechanismen aus dem Aufmerksamkeitsordner aus.
Eine sehr vorläufige automatische gemischte Präzision wurde hinzugefügt. FP16/FP32 Es kann mit einer CUDA -fähigen GPU erreicht werden. Eine Kombination von Pytorchs autocast() und gradscalar() wird zur gemischten Präzision verwendet. Weitere Informationen finden Sie im Pytorch -Tutorial. Leider blies die GPU während des Trainings und die CPU stützt vorerst nur Bfloat16. Braucht eine verdammt lange Zeit, um zu trainieren. Wenn jemand es verbessern kann, wäre das großartig. Überprüfen Sie das gemischte Präzisions -Notizbuch.
Wenn Sie mit Babygpt und Lama anfangen möchten, aber nicht den Aufwand, alles über Transformatormodelle zu wissen, können Sie einfach den Code aus dem Zugordner ausführen.
Sachen und Text aus dem Babygpt -Modell und dem Lama -Modell zu schulen und zu generieren. Rennen Sie trainpython babygpt_trainer.py und trainpython llama_trainer.py aus dem Zugordner.
Beide wurden am Tesla T4 GPUs ausgebildet. Sie können die Werte von max_itern entsprechend Ihrem Wunsch erhöhen oder verringern. Dauert ein paar Minuten, um zu trainieren.
Sie können das Ergebnis aus beiden Modellen im Trainer -Notebook sehen.
Anzahl der Parameter = 3,22 m
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
Es scheint, als konvergiert das Modell gegen Ende etwas früh. Vielleicht braucht das mehr Änderungen. Spucken Sie etwas Eminem yo aus.: Lächeln:
Der Datenordner enthält das Textdokument, das die Texte zu allen Songs von Eminem enthält.
| Notizbuch | Beschreibung |
|---|---|
| DOT -Produktaufmerksamkeit | Colab |
| Multi -Head -Aufmerksamkeit | Colab |
| GPT von Grund auf neu | Colab (ca. 860k Parameter) |
| Räumliche Transformatoren | Colab |
| Babygpt | Colab (16, 256 Out -Kanäle) |
| Lora | Colab (256 Kanäle) |
| Lit-Llama für Babygpt | Colab (16 Out-Kanäle für Lit-Llama) |
| Trainer für Babygpt und Lama | Colab (16 Out -Kanäle für Babygpt, 256 Kanäle für Lama) |
text.txt basiert auf Eminems Stan.
Die Lizenzen wurden aktualisiert, um FacebookResearch/Lama, Lit-Llama und IST-das Labor zu enthalten. Sie können es unter GNU, Apache und MIT verwenden.


