BabyGPT
1.0.0

S'appuyant sur l'intuition des NG-Vidéo de Karpathy et du Mingpt, Babygpt fournit un modèle de travail d'un GPT à une échelle beaucoup plus petite (256 ainsi que 16 canaux, 5 couches GPT, affinés). Babygpt a été construit à partir d'un Toygpt qui a été conçu pour comprendre les transformateurs à partir de zéro. Il a été réduit, comme vous le verrez ci-dessous. Visitez les cahiers. Nous passons à la hauteur des transformateurs à partir de modèles de langage simples, de mécanismes d'attention et enfin de babygpt. Tandis que Toygpt a été construit en séparant toutes les couches d'un transformateur de manière auto-invace. Dans Babygpt, le mécanisme d'attention est mis en œuvre manuellement. Le but de construire des GPT plus petits est de comprendre les fonctions du transformateur à un niveau beaucoup plus granulaire.
Pour entraîner de petits modèles, nous utilisons des tinystories. Vous pouvez télécharger les poids en étreignant le visage. Nous définissons Max_Iters sur 5000 sur un Tesla T4. Pour le modèle OG, nous utilisons 256 canaux OUT.
| modèle | durée du contexte | n_layers | n_head | n_embd | perte de train | perte de val | paramètres | données |
|---|---|---|---|---|---|---|---|---|
| 15m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13K | Histoires15.bin |
| 42m | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1,01 m | Stories42m.bin |
| Babygpt Original | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6,37m | données |
Remarque: - Le 110m est omis pour l'instant. Le bélier a explosé .. !!
Si vous souhaitez comprendre le Nitty Granticty de la façon dont les transformateurs fonctionnent à partir de zéro, cette feuille de route vous guidera. Nous commençons par la mise en œuvre de modèles linguistiques simples Bigram et Ngram, puis à partir de là, nous allons à la construction de transformateurs, un GPT à partir de zéro puis enfin babygpt.
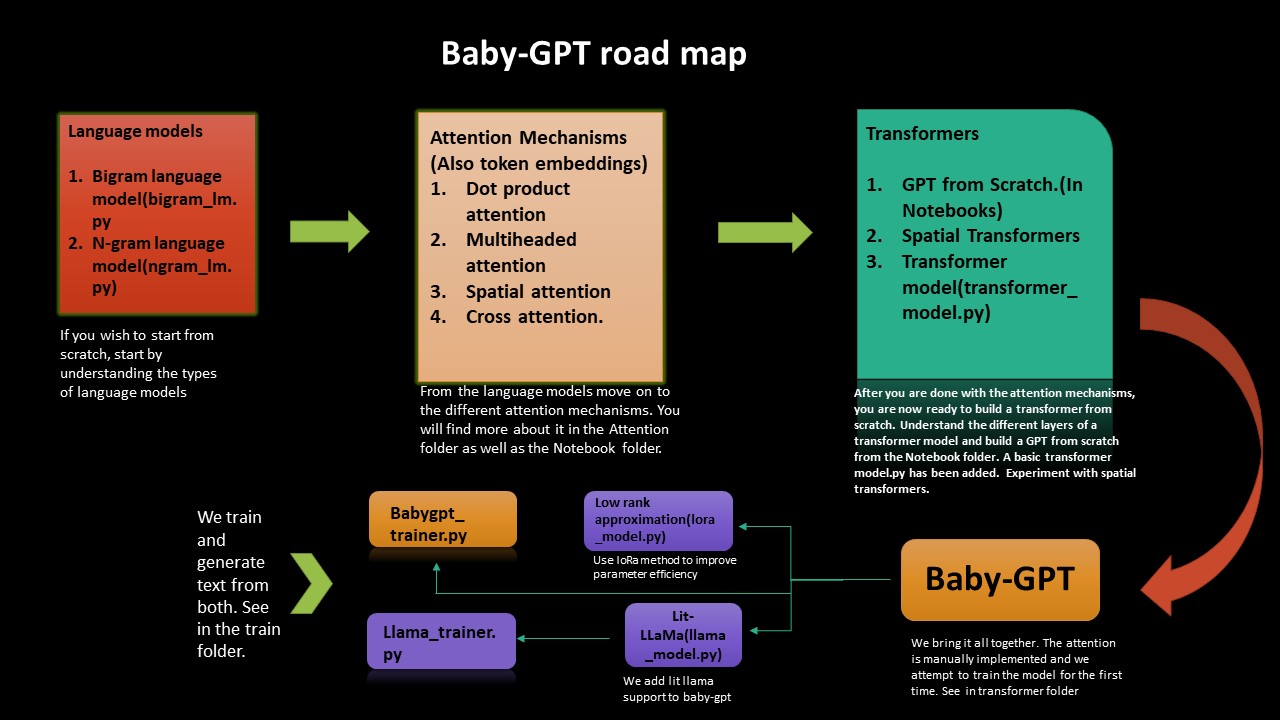
Nous mettons également en œuvre une approximation de bas rang ainsi que le lit-lama à Babygpt. Nous formons enfin les modèles et générons des jetons.
L'approximation à faible rang améliore l'efficacité des paramètres (technique de compression). Un lora_model.py a été ajouté (sur 256 canaux out). Nous recevons une réduction des paramètres d'environ 2. Tout, nous devons faire est de calculer un paramètre de rang et de calculer l'attention en conséquence. Dans le cahier Lora, une estimation des flops a été effectuée selon le papier chinchilla.
La quantification a également été effectuée sur le modèle LORA. Un calcul des flops a également été ajouté. Pour le modèle Babygpt pour 256 canaux, nous obtenons 0,407 flops PETA. Dans le cahier LORA, nous avons ajouté la quantification. En termes de réduction de taille, nous obtenons une réduction d'un facteur de 1,3 pour l'instant.
Une implémentation du modèle lit-llama a été portée à Babygpt (basée sur la version 1). Vous pouvez trouver le cahier ici -> llama_implementation. Exécutez le modèle, MFU a également été ajouté. llamapython llama_model_v1.py . Des jetons de formation et de génération ont été fournis ci-dessous.
Remarque: - Nous avons porté build_rope_cache() , apply_rope() et RMSNorm() à partir de la version 1. Nous n'utilisons pas non plus les poids ou points de contrôle de la version 1 (ce sont des modèles encore plus grands 7b, 13b, 65b etc.). Vous pouvez télécharger les poids et Port Llama sur votre propre version.
Nous avons porté Llama2 par Meta dans Babygpt. Vous pouvez trouver la mise en œuvre de llamapython llama2.py . Nous avons également fourni un calcul des flops avec le modèle.
Les flops pour calculer k, v cache est les flops à calculer est: - 2 * 2 * num_layers * (embedded_dim) ^ 2. Trouvez plus d'informations sur la façon de calculer la mémoire et de calculer dans le blog de Kipply, MFU a été ajouté à Llama2
Remarque: - Nous n'utilisons pas les poids de lama d'origine par Meta. Nous utilisons également des valeurs arbitraires pour 70b. Vous pouvez le porter sur votre propre modèle en utilisant vos propres poids.
La tokenisation à l'aide de la phrase a été effectuée. Nous exportons un tokenizer.bin contrairement au tokenzer le dossier quant. Exécutez-le dans llamapython tokenizer.py (méta-pièces ajoutées). Nous pouvons utiliser le fichier .bin pour une inférence supplémentaire.
Nous avons besoin d'une utilisation efficace de la mémoire pour les LLM. Les accélérateurs matériels utilisent une technique appelée utilisation du flop matérielle pour des compromis efficaces entre l'utilisation de la mémoire et le calcul. Cela se fait généralement en utilisant une estimation du rapport des flops observés sur un dispositif donné à ses flops de pic théoriques. Le MFU est le rapport du débit observé (jetons par seconde), par rapport au débit maximal théorique d'un système fonctionnant à des flops maximaux. Le maximum théorique Matmul de Tesla T4 est d'environ 8,1 Tflops. Par conséquent, nous calculons le MFU du modèle LLAMA Trainer. Voir dans le cahier d'entraîneur sous la-trainer lama. Nous recevons un MFU de: 0,0527723427% sur des paramètres de 3,22 m. Cela augmenterait bien sûr à mesure que le nombre de paramètres augmente. Pour un modèle de paramètre 530b, MPU est d'environ 30% sur les GPU A100. Nous utilisons la section B du papier palm pour référence.
Les LLM nécessitent de nombreux GPU pour s'exécuter, nous devons trouver des moyens de réduire ces exigences tout en préservant les performances du modèle. Diverses technologies ont été développées qui essaient de réduire la taille du modèle, vous avez peut-être entendu parler de la quantification et de la distillation. Il a été découvert qu'au lieu d'utiliser la précision FP32 de 4 octets, nous pouvons obtenir un résultat d'inférence presque identique avec la demi-précision BF16 / FP16 de 2 octets, qui récupère la taille du modèle.
Pour résoudre cela, la quantification 8 bits a été introduite. Cette méthode utilise un quart de précision, ne nécessitant donc que 1 / 4e de la taille du modèle! Mais ce n'est pas fait en laissant simplement tomber une autre moitié des bits. Il y a beaucoup plus dans ce sujet. Regardez la quantification du visage étreint.
Vous pouvez voir Quant.md sur la façon d'effectuer la quantinalisation des lama. Vous pouvez consulter le cahier de quantification pour une introduction au débutant à la quantification. Différentes analyses comparatives ont été effectuées. Pour Ex: - Sur un GPU, le modèle de paramètre 7B sur BFLOAT16 prendra environ 15 Go. Babygpt prendra environ quelques kilobytes .. !!! quantization.py a été obtenue à partir de Lit-Llama Repo. Un tokenzer utilisant la phrase a également été ajouté. Différentes types d'opérations de poids peuvent être effectuées à partir du tokenizer.model
Pour la quantification post-formation, nous sommes en mesure de réduire la taille du modèle d'un facteur de près de 4.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
Remarque: juste pour la quantification, nous utilisons un modèle plus grand avec environ 3,22 m de paramtres
L'analyse comparative des performances a été effectuée sur le babygptmodel et le modèle quantifié. Voici les résultats.
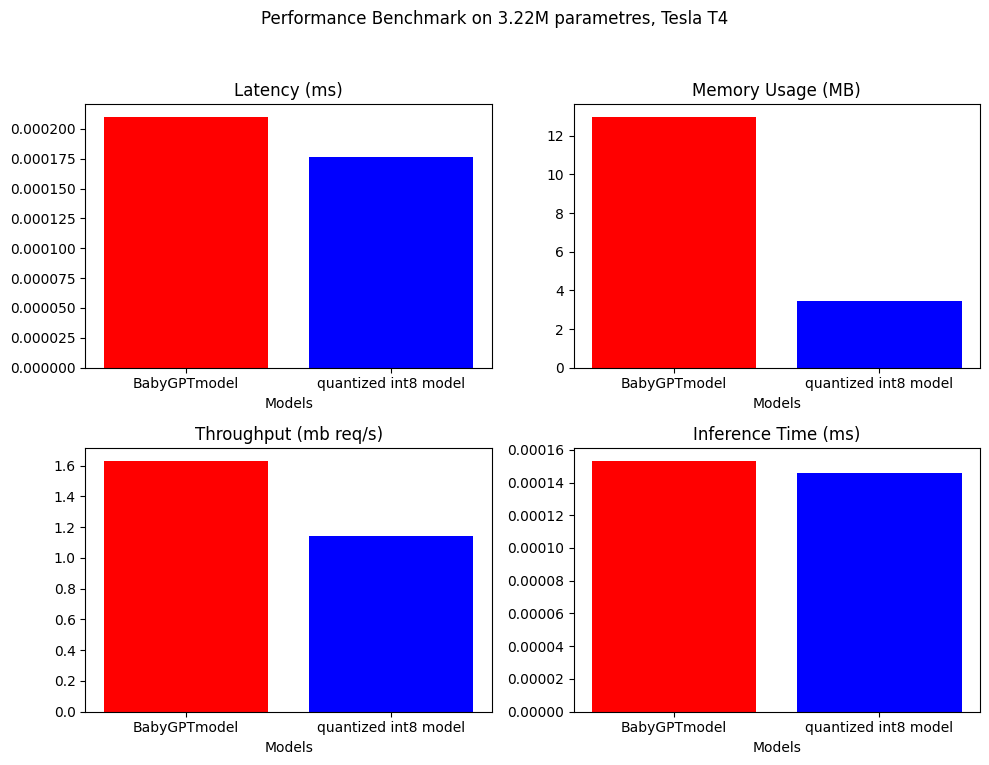 .
.
Il a été ajouté au cahier de quantification dans le dossier Quant.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
Clone le repo et exécutez ce qui suit:
! git clone https://github.com/soumyadip1995/BabyGPT.git
Pour exécuter les modèles de langue Bigram et Ngram. python bigram_lm.py et python ngram_lm.py .
Pour exécuter Babygpt transformerspython babygpt.py du dossier Transformers.
Pour exécuter un modèle de transformateur simple python transformer_model.py
Pour exécuter un modèle d'approximation à bas rang python LoRa_model.py
Pour exécuter le Llama Model llamapython llama_model_v1.py
Pour exécuter llama2 llamapython llama2.py
Exécutez les différents mécanismes d'attention du dossier d'attention.
Une précision automatique très préliminaire a été ajoutée. FP16 / FP32 Il peut être réalisé avec un GPU compatible CUDA. Une combinaison de Pytorch's autocast() et gradscalar() est utilisée pour une précision mixte. Voir plus dans le tutoriel Pytorch. Malheureusement, le GPU a explosé pendant l'entraînement et le CPU ne prend en charge que BFLOAT16. Prend beaucoup de temps pour s'entraîner. Si quelqu'un peut l'améliorer, ce serait génial. Vérifiez le cahier de précision mixte.
Si vous souhaitez commencer sur Babygpt et Llama, mais que vous ne voulez pas passer par tous les tracas de savoir tout sur les modèles de transformateurs, vous pouvez simplement commencer par exécuter le code à partir du dossier de train.
Pour entraîner et générer du texte à la fois à la fois à Babygpt Model et au modèle LLAMA. Run trainpython babygpt_trainer.py et trainpython llama_trainer.py du dossier de train.
Les deux ont été formés sur les GPU Tesla T4. Vous pouvez augmenter ou diminuer les valeurs de Max_Iters en fonction de votre souhait. Prend quelques minutes pour s'entraîner.
Vous pouvez voir le résultat des deux modèles du cahier d'entraîneur.
Nombre de params = 3,22 m
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
On dirait que le modèle converge un peu tôt, vers la fin. Peut-être que cela aura besoin de plus de modifications. Cracher un eminem yo ..: sourire:
Le dossier de données contient le document texte qui a les paroles de toutes les chansons d'Eminem.
| Carnet de notes | Description |
|---|---|
| Attention du produit DOT | colab |
| Attention multiples | colab |
| GPT à partir de zéro | Colab (paramètres d'environ 860k) |
| Transformateurs spatiaux | colab |
| Babygpt | Colab (16, 256 canaux) |
| Lora | colab (256 canaux) |
| lit-llama pour babygpt | Colab (16 canaux out pour lit-llama) |
| Traineur pour Babygpt et Llama | Colab (16 canaux OUT pour Babygpt, 256 canaux OUT pour LLAMA) |
text.txt est basé sur le stan d'Eminem.
Les licences ont été mises à jour pour inclure FacebookResearch / Llama, Lit-Lama et IST-DAS Lab, vous pouvez l'utiliser sous GNU, Apache et MIT.


