BabyGPT
1.0.0

بناءً على حدس محاضرات Karpathy NG-Video و Mingpt ، يوفر Babygpt نموذجًا عملًا لـ GPT على نطاق أصغر بكثير (256 بالإضافة إلى 16 قناة خارج ، 5 طبقة GPT ، تم ضبطها بشكل دقيق). تم بناء Babygpt من لعبة تم صنعها لفهم المحولات من الصفر. لقد تم تقليصه ، كما سترى أدناه. قم بزيارة دفاتر الملاحظات. نقوم بتوسيع نطاق المحولات من نماذج اللغة البسيطة وآليات الانتباه وأخيراً Babygpt. بينما تم بناء لعبة من خلال فصل جميع طبقات المحول بشكل غير مشترك. في Babygpt ، يتم تنفيذ آلية الانتباه يدويًا. الغرض من بناء GPTs الأصغر هو فهم وظائف المحولات على مستوى أكثر تحبينا.
لتدريب النماذج الصغيرة ، نستخدمها. يمكنك تنزيل الأوزان من وجه المعانقة. نحن نضع Max_iters على 5000 على Tesla T4. بالنسبة لنموذج OG ، نستخدم 256 قناة خارج.
| نموذج | طول السياق | n_layers | n_head | n_embd | خسارة القطار | فقدان فال | المعلمة | بيانات |
|---|---|---|---|---|---|---|---|---|
| 15m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13k | قصص 15M.Bin |
| 42 م | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1.01m | قصص 42 م |
| babygpt الأصل | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6.37m | بيانات |
ملاحظة:- تم حذف 110 متر في الوقت الحالي. فجر الكبش .. !!
إذا كنت ترغب في فهم الشجاعة الدقيقة لكيفية عمل المحولات من نقطة الصفر ، فإن خارطة الطريق هذه ستوجهك. نبدأ من تنفيذ نماذج اللغة البسيطة Bigram و Ngram ثم من هناك في طريقنا إلى بناء المحولات ، و GPT من نقطة الصفر ، ثم Babygpt أخيرًا.
نحن ننفذ تقريب رتبة منخفضة وكذلك Lit-Lama إلى babygpt كذلك. أخيرًا ندرب النماذج وننشئ الرموز.
تقريب الترتيب المنخفض يحسن كفاءة المعلمة (تقنية الضغط). تمت إضافة lora_model.py (على 256 قناة خارج). نتلقى تخفيضًا في البارامتر حوالي 2. كل شيء ، علينا القيام به هو حساب معلمة رتبة وحساب الاهتمام وفقًا لذلك. في دفتر الملاحظات في لورا ، تم إجراء تقدير للتقلب وفقًا لورقة Chinchilla.
كما تم إجراء القياس الكمي على طراز Lora. تمت إضافة حساب للتخبط أيضًا. بالنسبة لنموذج BabyGPT لـ 256 قناة خارج ، نحصل على 0.407 PETA. في دفتر الملاحظات في لورا أضفنا القياس الكمي. من حيث الحد من الحجم ، نحصل على انخفاض عامل 1.3 في الوقت الحالي.
تم نقل تنفيذ نموذج Lit-Llama إلى Babygpt (استنادًا إلى Llama- الإصدار 1). يمكنك العثور على دفتر الملاحظات هنا -> llama_implementation. تشغيل النموذج ، تمت إضافة MFU أيضًا. llamapython llama_model_v1.py . تم توفير الرموز التدريبية وتوليد أدناه.
ملاحظة:- لقد قمنا بنقل build_rope_cache() و apply_rope() و RMSNorm() من الإصدار 1. نحن أيضًا لا نستخدم أوزان الإصدار 1 أو نقاط التفتيش (هذه هي للموديلات الأكبر 7 ب ، 13 ب ، 65 ب ، إلخ). يمكنك تنزيل الأوزان و Port Llama على نسختك الخاصة.
لقد نقلنا llama2 بواسطة meta إلى babygpt. يمكنك العثور على التنفيذ في llamapython llama2.py . لقد قدمنا أيضًا حسابًا للتخبط مع النموذج.
تتخبط التزايد لحساب K ، V هو التقلبات اللازمة لحساب:-- 2 * 2 * num_layers * (inmbedded_dim) ^2. العثور على مزيد من المعلومات حول كيفية حساب الذاكرة والحساب في مدونة Kipply تمت إضافة MFU إلى LLAMA2
ملاحظة:- نحن لا نستخدم أوزان Llama الأصلية بواسطة Meta. نحن نستخدم أيضًا قيمًا تعسفية لـ 70B. يمكنك نقله إلى النموذج الخاص بك باستخدام أوزانك الخاصة.
تم إجراء الرمز المميز باستخدام SentencePiece. نقوم بتصدير tokenizer.bin على عكس المجلد الكمي. قم بتشغيله في llamapython tokenizer.py (تمت إضافة قطع meta). يمكننا استخدام ملف .bin لمزيد من الاستدلال.
نحن بحاجة إلى استخدام ذاكرة فعال لـ LLMs. يستخدم مسرعات الأجهزة تقنية تسمى استخدام أجهزة Flop لمقايضات فعالة بين استخدام الذاكرة والحساب. يتم ذلك عادةً باستخدام تقدير لنسبة التقلبات التي تمت ملاحظتها على جهاز معين إلى ذروته النظرية. MFU هي نسبة الإنتاجية المرصودة (الرموز الرموز في الثانية) ، نسبة إلى الحد الأقصى النظري لإنتاجية نظام يعمل في الذروة. الذروة النظرية Matmul من Tesla T4 حوالي 8.1 tflops. وبالتالي ، نقوم بحساب MFU لنموذج مدرب LLAMA. انظر في دفتر المدرب تحت Llama-Trainer. نتلقى MFU من: 0.0527723427 ٪ على 3.22M المعلمات. هذا سيزيد بالطبع مع زيادة عدد المعلمات. بالنسبة لنموذج Parametre 530B ، يبلغ MPU حوالي 30 ٪ على وحدات معالجة الرسومات A100. نستخدم القسم ب من ورقة النخيل للرجوع إليه.
تتطلب LLMs العديد من وحدات معالجة الرسومات ، نحتاج إلى إيجاد طرق لتقليل هذه المتطلبات مع الحفاظ على أداء النموذج. تم تطوير تقنيات مختلفة تحاول تقليص حجم النموذج ، ربما تكون قد سمعت عن القياس الكمي والتقطير. لقد تم اكتشاف أنه بدلاً من استخدام دقة FP32 ذات 4 بايت ، يمكننا الحصول على نتيجة استنتاج متطابقة تقريبًا مع نصف الدقة 2-بايت BF16/FP16 ، والتي تحدد حجم النموذج.
لعلاج ذلك ، تم تقديم كميات 8 بت. تستخدم هذه الطريقة دقة ربع ، وبالتالي تحتاج فقط إلى 1/4 من حجم النموذج! ولكن لم يتم ذلك عن طريق إسقاط نصف البتات. هناك الكثير لهذا الموضوع. انظر إلى معانقة كمية الوجه.
يمكنك رؤية Quant.md حول كيفية أداء llama-quantization. يمكنك إلقاء نظرة على كمبيوتر محمول لتقديم كميات لإدخال المبتدئين في القياس الكمي. تم إجراء معايير مختلفة. على سبيل المثال:- على وحدة معالجة الرسومات ، سيستغرق نموذج PRAMETRE 7B على BFLOAT16 حوالي 15 جيجابايت. سوف يستغرق Babygpt حوالي بضعة كيلو بايت .. !!! تم الحصول على quantization.py من repo lit-llama. تمت إضافة رمز الرمز المميز باستخدام SentencePiece أيضًا. يمكن إجراء أنواع مختلفة من عمليات الوزن من tokenizer.model
بالنسبة لقياس ما بعد التدريب ، يمكننا تقليل حجم النموذج بعامل ما يقرب من 4.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
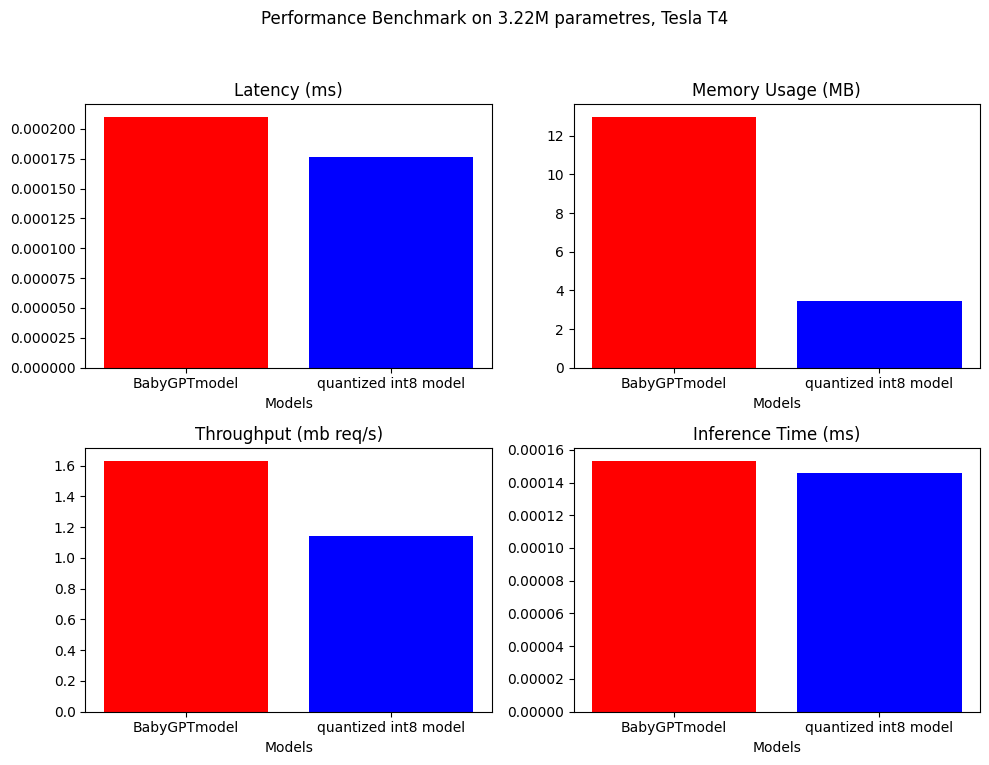
ملاحظة: فقط للتشكيل ، نستخدم نموذجًا أكبر مع حوالي 3.22 متر paramtres
تم إجراء معايير الأداء على Babygptmodel والنموذج الكمي. فيما يلي النتائج.
 .
.
تمت إضافته إلى دفتر كميات في المجلد الكمي.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
استنساخ الريبو وقم بتشغيل ما يلي:
! git clone https://github.com/soumyadip1995/BabyGPT.git
لتشغيل نماذج لغة Bigram و Ngram. python bigram_lm.py و python ngram_lm.py .
لتشغيل Babygpt transformerspython babygpt.py من مجلد Transformers.
لتشغيل نموذج محول بسيط python transformer_model.py
لتشغيل نموذج تقريب رتبة منخفضة python LoRa_model.py
لتشغيل طراز Llama llamapython llama_model_v1.py
لتشغيل llama2 llamapython llama2.py
تشغيل آليات الانتباه المختلفة من مجلد الانتباه.
تمت إضافة دقة أولية أولية مختلطة. FP16/FP32 يمكن تحقيقه باستخدام وحدة معالجة الرسومات CUDA. يستخدم مزيج من autocast() و gradscalar() من Pytorch للدقة المختلطة. شاهد المزيد في البرنامج التعليمي Pytorch. لسوء الحظ ، فجر GPU أثناء التدريب ووحدة المعالجة المركزية في الوقت الحالي يدعم فقط Bfloat16. يأخذ جحيم وقت طويل للتدريب. إذا كان بإمكان أي شخص تحسينه ، فسيكون ذلك رائعًا. تحقق من دفتر الملاحظات الدقة المختلطة.
إذا كنت ترغب في البدء في Babygpt و Llama ، ولكن لا تريد أن تمر بكل متاعب معرفة كل شيء عن نماذج المحولات ، يمكنك ببساطة البدء عن طريق تشغيل الكود من مجلد القطار.
لتدريب وتوليد النص من كل من نموذج Babygpt ونموذج Llama. Run trainpython babygpt_trainer.py and trainpython llama_trainer.py من مجلد القطار.
تم تدريب كلاهما على وحدات معالجة الرسومات Tesla T4. يمكنك زيادة أو تقليل قيم Max_iters وفقًا لرغبتك. يستغرق بضع دقائق للتدريب.
يمكنك رؤية النتيجة من كلا النموذجين في دفتر المدرب.
عدد المعلمات = 3.22 م
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
يبدو أن النموذج يتقارب في وقت مبكر بعض الشيء ، في النهاية. ربما سيحتاج ذلك إلى مزيد من التعديل. البصق بعض ايمينيم يو ..: ابتسامة:
يحتوي مجلد البيانات على مستند النص الذي يحتوي على كلمات لجميع أغاني Eminem.
| دفتر | وصف |
|---|---|
| انتباه المنتج نقطة | كولاب |
| اهتمام متعددة | كولاب |
| GPT من الصفر | كولاب (حوالي 860K المعلمات) |
| المحولات المكانية | كولاب |
| babygpt | كولاب (16 ، 256 قناة خارج) |
| لورا | كولاب (256 قناة خارج) |
| Lit-llama for babygpt | كولاب (16 قناة خارجية ل Lit-Llama) |
| مدرب لـ Babygpt و Llama | كولاب (16 قناة خارج Babygpt ، 256 قناة خارج لما) |
يعتمد text.txt على ستان Eminem.
تم تحديث التراخيص لتشمل FacebookResearch/Llama و Lit-Llama و IST-Das Lab يمكنك استخدامها تحت GNU و Apache و MIT.


