BabyGPT
1.0.0

Com base na intuição das lecturas ng-video e mingpt de Karpathy, o Babygpt fornece um modelo de trabalho de um GPT em uma escala muito menor (256, bem como 16 canais, 5 camadas GPT, ajustados finos). Babygpt foi construído a partir de um brinquedo que foi feito para entender os transformadores do zero. Foi reduzido, como você verá abaixo. Visite os cadernos. Nós aumentamos para transformadores de modelos de linguagem simples, mecanismos de atenção e, finalmente, babygpt. Enquanto o Toygpt foi construído separando todas as camadas de um transformador, de forma alguma. Em Babygpt, o mecanismo de atenção é implementado manualmente. O objetivo de construir GPTs menores é entender as funções do transformador em um nível muito mais granular.
Para treinar pequenos modelos, estamos usando o TinyStories. Você pode baixar os pesos do rosto abraçando. Estamos definindo max_iters como 5000 em um Tesla T4. Para o modelo OG, estamos usando 256 canais out.
| modelo | comprimento do contexto | n_layers | n_head | n_embd | perda de trem | Val perda | parametres | dados |
|---|---|---|---|---|---|---|---|---|
| 15m | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13k | Stories15m.bin |
| 42m | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1,01m | histórias42m.bin |
| Babygpt original | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6.37m | dados |
Nota:- O 110m está sendo omitido por enquanto. A RAM explodiu .. !!
Se você deseja entender o âmago da questão de como os Transformers funcionam do zero, este roteiro o guiará. Começamos da implementação de modelos de linguagem simples Bigram e Ngram e, a partir daí, trabalhamos até a construção de transformadores, um GPT do zero e, finalmente, Babygpt.
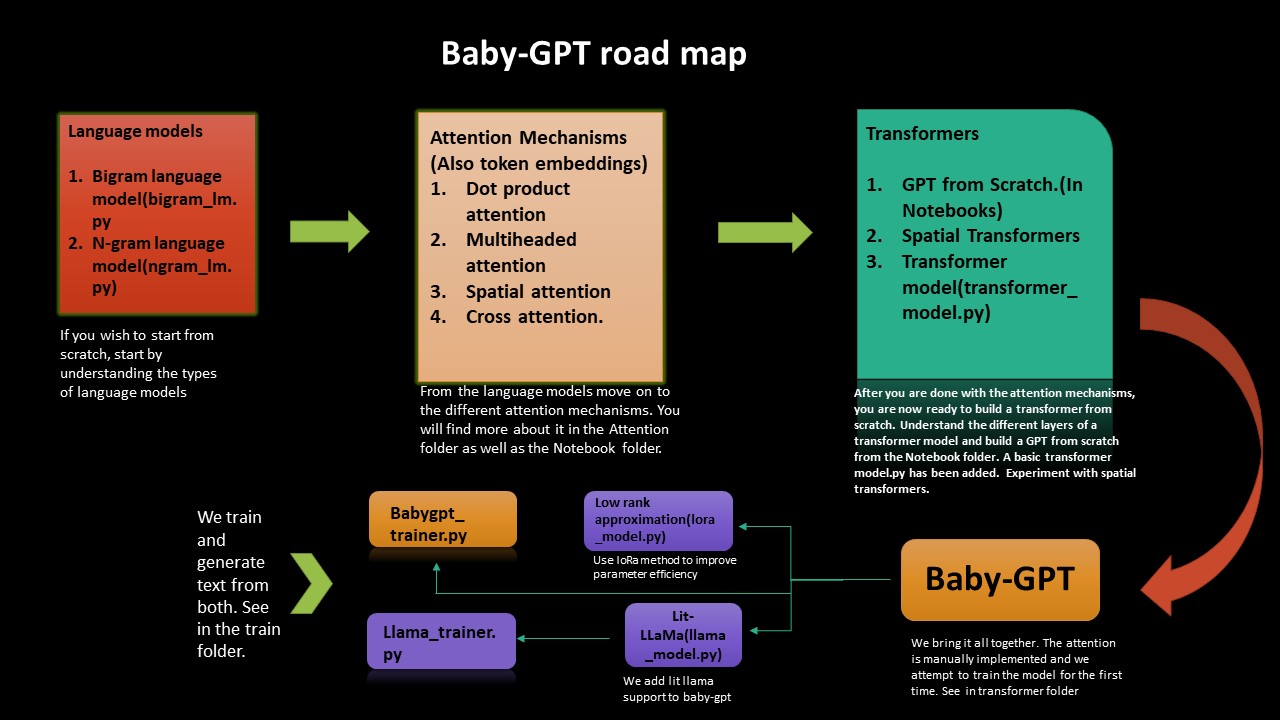
Implementamos uma aproximação de baixa classificação, bem como Lama Lama ao Babygpt também. Finalmente treinamos os modelos e geramos tokens.
A aproximação de baixa classificação melhora a eficiência dos parâmetros (técnica de compressão). Um Lora_model.py foi adicionado (em 256 canais de saída). Recebemos uma redução de parâmetros de cerca de 2. Tudo, precisamos fazer é calcular um parâmetro de classificação e calcular a atenção de acordo. No caderno de Lora, uma estimativa de fracassos foi feita de acordo com o papel chinchilla.
A quantização também foi realizada no modelo Lora. Um cálculo de flops também foi adicionado. Para o modelo Babygpt para 256 canais de saída, obtemos 0,407 flops PETA. No caderno Lora, adicionamos a quantização. Em termos de redução de tamanho, estamos obtendo uma redução de um fator de 1,3 por enquanto.
Uma implementação do modelo Lit-llama foi portada para Babygpt (com base na llama-versão 1). Você pode encontrar o notebook aqui -> llama_implementation. Execute o modelo, a MFU também foi adicionada. llamapython llama_model_v1.py . Treinamento e geração de tokens foram fornecidos abaixo.
NOTA:- Portamos build_rope_cache() , apply_rope() e RMSNorm() da versão 1. Também não estamos usando os pesos ou pontos de verificação da versão 1 (são para modelos ainda maiores 7b, 13b, 65b etc). Você pode baixar os pesos e a llama da porta para sua própria versão.
Portamos llama2 por meta para o babygpt. Você pode encontrar a implementação em llamapython llama2.py . Também fornecemos um cálculo de fracassos junto com o modelo.
Os fracassos para calcular k, v cache são os flops para calcular são:- 2 * 2 * num_layers * (incorporado_dim) ^2. Encontre mais informações sobre como calcular a memória e calcular no blog de Kipply MFU foi adicionado ao llama2
NOTA:- Não estamos usando pesos originais de lhama por meta. Também estamos usando valores arbitrários para 70b. Você pode portá -lo para seu próprio modelo usando seus próprios pesos.
A tokenização usando a frase da sentença foi feita. Estamos exportando um tokenizer.bin diferente do tokenizer a pasta Quant. Execute-o em llamapython tokenizer.py (meta-peças adicionadas). Podemos usar o arquivo .bin para mais inferência.
Precisamos de uso de memória eficiente para o LLMS. Os aceleradores de hardware usam uma técnica chamada Utilização de Flop de hardware para trade-offs eficientes entre o uso da memória e a computação. Isso geralmente é feito usando uma estimativa da proporção de fracassos observados em um determinado dispositivo em seus picos teóricos. A MFU é a razão entre a taxa de transferência observada (tokens por segundos), em relação à taxa de transferência máxima teórica de um sistema operando em picos de pico. O pico teórico Matmul de Tesla T4 é de cerca de 8,1 tflops. Portanto, calculamos o MFU do modelo de treinador de llama. Veja no caderno de treinador sob o LLAMA-TRAINER. Recebemos um MFU de: 0,0527723427% em 3,22m parâmetros. É claro que isso aumentaria à medida que o número de parâmetros aumenta. Para um modelo de parâmetros de 530b, a MPU está em torno de 30% nas GPUs A100. Usamos a Seção B do papel de palma para referência.
Os LLMs exigem que muitas GPUs sejam executadas, precisamos encontrar maneiras de reduzir esses requisitos, preservando o desempenho do modelo. Foram desenvolvidas várias tecnologias que tentam diminuir o tamanho do modelo, você pode ter ouvido falar de quantização e destilação. Foi descoberto que, em vez de usar a precisão de 4 bytes FP32, podemos obter um resultado de inferência quase idêntico com a meia precisão de 2 bytes BF16/FP16, que reduz o tamanho do modelo.
Para remediar isso, a quantização de 8 bits foi introduzida. Este método usa uma precisão de um quarto, precisando de apenas 1/4 do tamanho do modelo! Mas isso não é feito apenas deixando cair outra metade dos bits. Há muito mais nesse tópico. Olhe para abraçar a quantização do rosto.
Você pode ver o Quant.md sobre como executar a quantização de lhama. Você pode procurar notebook de quantização para a introdução de um iniciante na quantização. Benchmarkings diferentes foram feitos. Para Ex:- Em uma GPU, o modelo 7B Parametre no BFLOAT16 levará cerca de 15 GB. Babygpt levará cerca de alguns kilobytes .. !!! quantization.py foi obtido do Repo Lit-Llama. Um tokenizador usando a frase de sentença também foi adicionado. Os diferentes tipos de operações de peso podem ser realizados no tokenizer.model
Para quantização pós -treinamento, somos capazes de reduzir o tamanho do modelo em um fator de quase 4.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
NOTA: Apenas para quantização, estamos usando um modelo maior com cerca de 3,22m Paramtres
O benchmarking de desempenho foi feito no BabygptModel e no modelo quantizado. Abaixo estão os resultados.
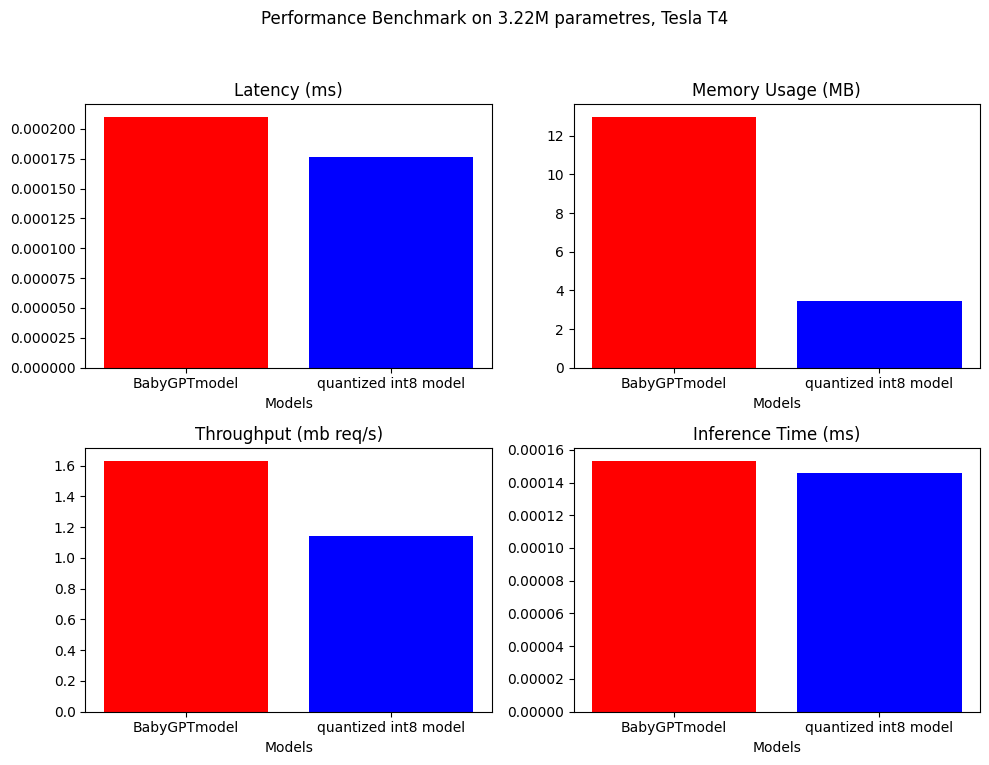 .
.
Foi adicionado ao notebook de quantização na pasta Quant.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
Clone o repo e execute o seguinte:
! git clone https://github.com/soumyadip1995/BabyGPT.git
Para executar os modelos de idiomas bigram e ngram. python bigram_lm.py e python ngram_lm.py .
Para executar transformerspython babygpt.py da pasta Transformers.
Para executar um modelo simples de transformador python transformer_model.py
Para executar um modelo de aproximação de baixa classificação python LoRa_model.py
Para executar o modelo de llama llamapython llama_model_v1.py
Para correr llama2 llamapython llama2.py
Execute os diferentes mecanismos de atenção da pasta de atenção.
Uma precisão mista automática muito preliminar foi adicionada. FP16/FP32 pode ser alcançado com uma GPU habilitada para CUDA. Uma combinação de autocast() e gradscalar() de Pytorch é usada para precisão mista. Veja mais no tutorial de Pytorch. Infelizmente, a GPU explodiu durante o treinamento e a CPU por enquanto suporta apenas o BFLOAT16. Leva muito tempo para treinar. Se alguém puder melhorar, isso seria incrível. Verifique o caderno de precisão mista.
Se você deseja começar em Babygpt e Llama, mas não quer passar por todo o aborrecimento de saber tudo sobre modelos de transformadores, você pode simplesmente começar executando o código da pasta do trem.
Treinar e gerar texto do modelo Babygpt e do modelo de lhama. Execute trainpython babygpt_trainer.py e trainpython llama_trainer.py da pasta de trem.
Ambos foram treinados nas GPUs Tesla T4. Você pode aumentar ou diminuir os valores de max_iters de acordo com o seu desejo. Leva alguns minutos para treinar.
Você pode ver o resultado dos dois modelos no caderno de treinadores.
Número de parâmetros = 3,22 m
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
Parece que o modelo converge um pouco cedo, no final. Talvez isso precise de mais modificação. Cuspindo um pouco de eminem yo ..: sorria:
A pasta de dados contém o documento de texto que tem a letra de todas as músicas de Eminem.
| Caderno | Descrição |
|---|---|
| Atenção do produto DOT | colab |
| Atenção com várias cabeças | colab |
| GPT do zero | colab (aproximadamente 860k parâmetros) |
| Transformadores espaciais | colab |
| Babygpt | Colab (16, 256 canais de saída) |
| Lora | Colab (256 canais out) |
| Lit-llama para babygpt | COLAB (16 canais de fora para lit-llama) |
| treinador para babygpt e lhama | Colab (16 canais para Babygpt, 256 canais para lhama) |
text.txt é baseado no Stan de Eminem.
As licenças foram atualizadas para incluir o FacebookResearch/LLAMA, LIT-LLAMA e IST-DAS LAB Você pode usá-lo no GNU, Apache e MIT.


