BabyGPT
1.0.0

Основываясь на интуиции NG-видео-лекций Карпати, Babygpt предоставляет рабочую модель GPT в гораздо меньшем масштабе (256, а также 16 каналов, 5 слоя GPT, тонко настроенный). BabyGPT был построен из ToyGPT, который был сделан для понимания трансформаторов с нуля. Это было масштабировано, как вы увидите ниже. Посетите ноутбуки. Мы масштабируемся до трансформаторов от простых языковых моделей, механизмов внимания и, наконец, Babygpt. В то время как ToyGPT был построен путем отделения всех слоев трансформатора. В Babygpt механизм внимания реализуется вручную. Целью строительства меньших GPT является понимание функций трансформатора на гораздо более детальном уровне.
Для обучения небольших моделей мы используем крошечные вещи. Вы можете скачать веса с обнимающегося лица. Мы устанавливаем max_iters до 5000 на Tesla T4. Для модели OG мы используем 256 каналов.
| модель | контекст длины | n_layers | n_head | n_embd | Потеря поезда | Val проигрыш | параметры | данные |
|---|---|---|---|---|---|---|---|---|
| 15 м | 16 | 4 | 4 | 16 | 2.4633 | 2.4558 | 13K | Stories15m.bin |
| 42 м | 32 | 8 | 8 | 32 | 2.3772 | 2.3821 | 1,01 м | Stories42m.bin |
| Babygpt Original | 64 | 8 | 8 | 256 | 1.3954 | 1.5959 | 6,37 м | данные |
ПРИМЕЧАНИЕ:- 110M пока не опускается. ОЗУ взорвалась .. !!
Если вы хотите понять, как трансформеры работают с нуля, эта дорожная карта поможет вам. Мы начинаем с внедрения простых языковых моделей Bigram и NGRAM, а затем оттуда проходим путь к строительству трансформаторов, GPT с нуля, а затем, наконец, Babygpt.
Мы внедряем приближение с низким рангом, а также Lit-Lama для BabyGPT. Мы наконец тренируем модели и генерируем токены.
Низкое приближение к рейтингу повышает эффективность параметра (метод сжатия). Была добавлена lora_model.py (на каналах 256). Мы получаем параметрическое сокращение примерно на 2. Все, что нам нужно сделать, это вычислить параметру ранга и соответствующим образом вычислить внимание. В ноутбуке Lora оценка провалов была сделана в соответствии с бумагой Chinchilla.
Квантование также было выполнено на модели LORA. Расчет провалов также был добавлен. Для модели BabyGPT для 256 каналов мы получаем 0,407 FLOPS. В ноутбуке Lora мы добавили квантование. С точки зрения уменьшения размера, мы получаем сокращение коэффициента на 1,3 на данный момент.
Имплеметация модели Lit-Lalama была перенесена в BabyGPT (на основе Llama-версии 1). Вы можете найти ноутбук здесь -> Llama_Implementation. Запустите модель, MFU также была добавлена. llamapython llama_model_v1.py . Обучение и генерирующие токены были предоставлены ниже.
Примечание.- У нас есть порт build_rope_cache() , apply_rope() и RMSNorm() из версии 1. Мы также не используем вес версии 1 или контрольные точки (они для еще больших моделей 7b, 13b, 65b и т. Д.). Вы можете скачать вес и порт ламы на свою собственную версию.
Мы перенесли Llama2 на Meta в Babygpt. Вы можете найти реализацию в llamapython llama2.py . Мы также предоставили расчет провалов вместе с моделью.
Флопы для вычисления k, v кэш- это провал для вычисления:-- 2 * 2 * num_layers * (upedded_dim) ^2. Найдите больше информации о том, как вычислить память, и вычислить в блоге Kipply MFU, MFU был добавлен в Llama2
Примечание:- Мы не используем оригинальные веса ламы от Meta. Мы также используем произвольные значения для 70b. Вы можете перенести его в свою собственную модель, используя свои веса.
Токенизация с использованием предложения была сделана. Мы экспортируем tokenizer.bin В отличие от токенизатора папку Quant. Запустите его в llamapython tokenizer.py (добавлены мета-часы). Мы можем использовать файл .bin для дальнейшего вывода.
Нам нужно эффективное использование памяти для LLMS. Аппаратные акселераторы используют метод, называемый использование аппаратного флопа для эффективных компромиссов между использованием памяти и вычислением. Обычно это делается с использованием оценки соотношения провалов, наблюдаемого на данном устройстве к его теоретическим пиковым провалу. MFU-это отношение наблюдаемой пропускной способности (токенс в секунду), относительно теоретической максимальной пропускной способности системы, работающей на пиковых провале. Теоретический пик мамула Tesla T4 составляет около 8,1 Tflops. Следовательно, мы рассчитываем MFU модели тренера Llama. Смотрите в ноутбуке Trainer под Llama-Trainer. Мы получаем MFU: 0,0527723427% на параметрах 3,22 м. Это, конечно, увеличится по мере увеличения количества параметров. Для модели параметров 530B MPU составляет около 30% на графических процессорах A100. Мы используем раздел B от Palm Paper для справки.
LLMS требует много графических процессоров, чтобы запустить, нам нужно найти способы уменьшить эти требования при сохранении производительности модели. Были разработаны различные технологии, которые пытаются сократить размер модели, вы, возможно, слышали о квантовании и дистилляции. Было обнаружено, что вместо использования 4-байтовой точности FP32 мы можем получить почти идентичный результат вывода с 2-байтовой полуотдельной половиной BF16/FP16, что вдвое увеличивает размер модели.
Чтобы исправить это, 8-битное квантование было введено. Этот метод использует точность четверти, таким образом, требуется только 1/4 размера модели! Но это не сделано, просто сбросив еще половину битов. В этой теме гораздо больше. Посмотрите на квантование лица.
Вы можете увидеть Quant.MD о том, как выполнить лама-квалификацию. Вы можете посмотреть ноутбук -квантование для введения новичка к квантованию. Различные бенчмаркинги были сделаны. Например:- на графическом процессоре модель параметра 7B на BFLOAT16 займет около 15 ГБ. Babygpt займет около нескольких килобитов .. !!! quantization.py был получен из Lit-Llama Repo. Также был добавлен токенизатор, использующий предложение. Рабочие виды весовых операций могут быть выполнены из Tokenizer.Model
Для квантования после обучения мы можем уменьшить размер модели в течение почти 4.
model_fp = BabyGPTmodel(config)
model_fp.eval()
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8)
/// number of parameters: 3222637
12.9688 MB
3.4603 MB ////
Примечание: только для квантования мы используем более крупную модель с примерно 3,22 м.
Производительность производительности была сделана на Babygptmodel и квантовой модели. Ниже приведены результаты.
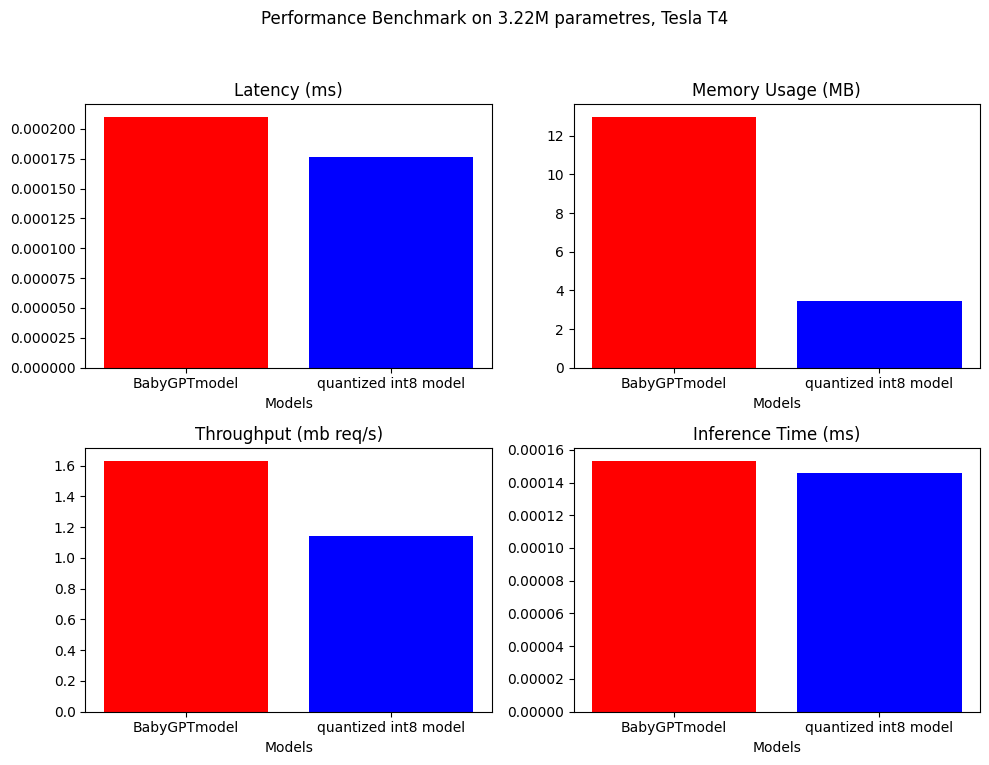 Полем
Полем
Он был добавлен в ноутбук -квантование в папке Quant.
BabyGPT
├── bigram_lm.py
├── ngram_lm.py
├── model.py
├── Lora_model.py
├── Llama_model.py
├── Attention
│ ├── dot product attention.py
│ ├── multi headed attention.py
│ ├── cross attention.py
│ ├── spatial attention.py
├── Notebook
│ ├── Dot product attention
│ ├── multiheaded attention
│ ├── gpt from scratch
│ ├── spatial transformer
│ ├── babyGPT
│ ├── LoRa
│ ├── llama_implementation
│ ├── mixed precision
├── Train
| ├── babygpt_trainer.py
| ├── llama_trainer.py
├── transformers
| ├── transformer_model.py
│ ├── babyGPT.py
├── Quant
│ ├── quantization.py
│ ├── quantization notebook
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ ├── tokenizer.py
│ ├── model.pth
│ ├── quant.md
├── llama
│ ├── llama2.py
│ ├── llama_model_v1.py
│ ├── tokenizer.py
│ ├── tokenizer.vocab
│ ├── tokenizer.bin
│ ├── tokenizer.model
├── text.txt
├── trainer.ipynb
├── requirements.txt
Клонировать репо и запустите следующее:
! git clone https://github.com/soumyadip1995/BabyGPT.git
Запустить модели языка Bigram и ngram. python bigram_lm.py и python ngram_lm.py .
Запустить Babygpt transformerspython babygpt.py из папки Transformers.
Чтобы запустить простую трансформаторную модель python transformer_model.py
Чтобы запустить модель приближения низкого ранга python LoRa_model.py
Запустить модель Llama llamapython llama_model_v1.py
Запустить Llama2 llamapython llama2.py
Запустите различные механизмы внимания из папки внимания.
Была добавлена очень предварительная автоматическая смешанная точность. FP16/FP32 он может быть достигнут с помощью графического процессора с поддержкой CUDA. Комбинация autocast() и gradscalar() Pytorch используется для смешанной точности. Смотрите больше в учебном пособии Pytorch. К сожалению, графический процессор взорвался во время тренировки и процессора, пока он только поддерживает BFLOAT16. Требуется долго, чтобы тренироваться. Если кто -то сможет улучшить это, это было бы потрясающе. Проверьте смешанную ноутбук.
Если вы хотите начать работу на Babygpt и Llama, но не хотите пройти через все проблемы, зная все о моделях трансформатора, вы можете просто начать с запуска кода из папки поезда.
Тренировать и генерировать текст как из модели BabyGPT, так и из модели Llama. Запустите trainpython babygpt_trainer.py и trainpython llama_trainer.py из папки поезда.
Оба были обучены на графических процессорах Tesla T4. Вы можете увеличить или уменьшить значения max_iters в соответствии с вашим желанием. Потребуется несколько минут, чтобы тренироваться.
Вы можете увидеть результат обеих моделей в ноутбуке Trainer.
Количество параметров = 3,22 м
``` number of parameters: 3222381 ```
step 0: train loss 4.6894, val loss 4.6895
step 500: train loss 2.1731, val loss 2.1832
step 1000: train loss 1.7580, val loss 1.8032
step 1500: train loss 1.5790, val loss 1.6645
step 2000: train loss 1.4482, val loss 1.5992
step 2500: train loss 1.3538, val loss 1.5874
step 3000: train loss 1.2574, val loss 1.5971
.
.
.
step 9000: train loss 0.5236, val loss 2.4614
step 9500: train loss 0.4916, val loss 2.5494
step 10000: train loss 0.4680, val loss 2.6631
step 10500: train loss 0.4448, val loss 2.6970
step 10999: train loss 0.4341, val loss 2.7462
Detroit, revior myself 'til I confused to get the big clead Mastles
Slaughterhouse on the blue, that's when he pine I'm hop with the cowprinton
robaly I want to a lox on my tempt
But now we can't never find a gift killed broke
Big before anyone could ever hear the first as I was cooped chill
But i this o for a big star
I said get chased up!
(Hello darkness, my old friend)[Eminem:]
If my legacy I acged buving in the tub (might what?)
I would know one [*Barrns, worried :]
Yeah, so kon bitch, it's
Похоже, модель сходится немного рано, к концу. Может быть, это потребуется больше модификации. Плевать немного Эминема, йо ..: улыбка:
Папка данных содержит текстовый документ, который имеет текст всех песен Эминема.
| Блокнот | Описание |
|---|---|
| Точечный продукт внимание | колаба |
| Многополосное внимание внимания | колаба |
| GPT с нуля | Colab (около 860 тыс. Параметры) |
| Пространственные трансформаторы | колаба |
| Babygpt | Колаб (16, 256 каналов) |
| Лора | Колаб (256 каналов) |
| Lit-Llama для Babygpt | Колаб (16 каналов для Lit-Llama) |
| тренер для Babygpt и Llama | Colab (16 каналов для Babygpt, 256 каналов для ламы) |
text.txt основан на Stan Eminem's Stan.
Лицензии были обновлены, чтобы включить FacebookResearch/Llama, Lit-Llama и IST-DAS Lab, вы можете использовать его под GNU, Apache и MIT.


